
Let’s get to know the benchmarks AI companies use to compare each others’ versions.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
- AI Vendors and their LLM Brands
- List of benchmarks
- Show your work. Get famous.
- LLMs by subject category
- AGI & ASI?
- Sneaky Tricks with Benchmarks
- Math Benchmarks
- Science benchmarks
- GPQA
- Coding LCB (Live Code Bench)
- SWE-Bench benchmark
- Creative Writing
- Instruction Following
- Language Translations
- Evaluation Quality Metrics
In AI Computer Science, a benchmark is a way to determine how well each LLM model can solve problems. Several benchmarks have been created, mostly by academics and giant frountier LLM producers.
AI Vendors and their LLM Brands
| Country | Vendor | LLM brand | app |
|---|---|---|---|
| China | Alibaba | Qwen | |
| US | Allen AI | Olmo | |
| US | Amazon | Nova | |
| US | Anthropic | Claude | |
| US | Apple | MM1, ReALM | |
| China | DeepSeek | R1,R2,V3 | |
| US | Fireworks.ai | KwaiKAT-Coder | |
| US | Gemini | ||
| China | Zhipu (Z.Ai) | Kimi K2 | |
| US | Meta | Llama | |
| US | Microsoft | Phi | |
| Singapore | MiniMax | M2, Hailuo, Speech | |
| France | Mistral | Medium, Large | |
| US | NVIDIA | Nemotron | |
| US | OpenAI | GPT | ChatGPT |
| US | xAI | Grok |
LLM Highlights:
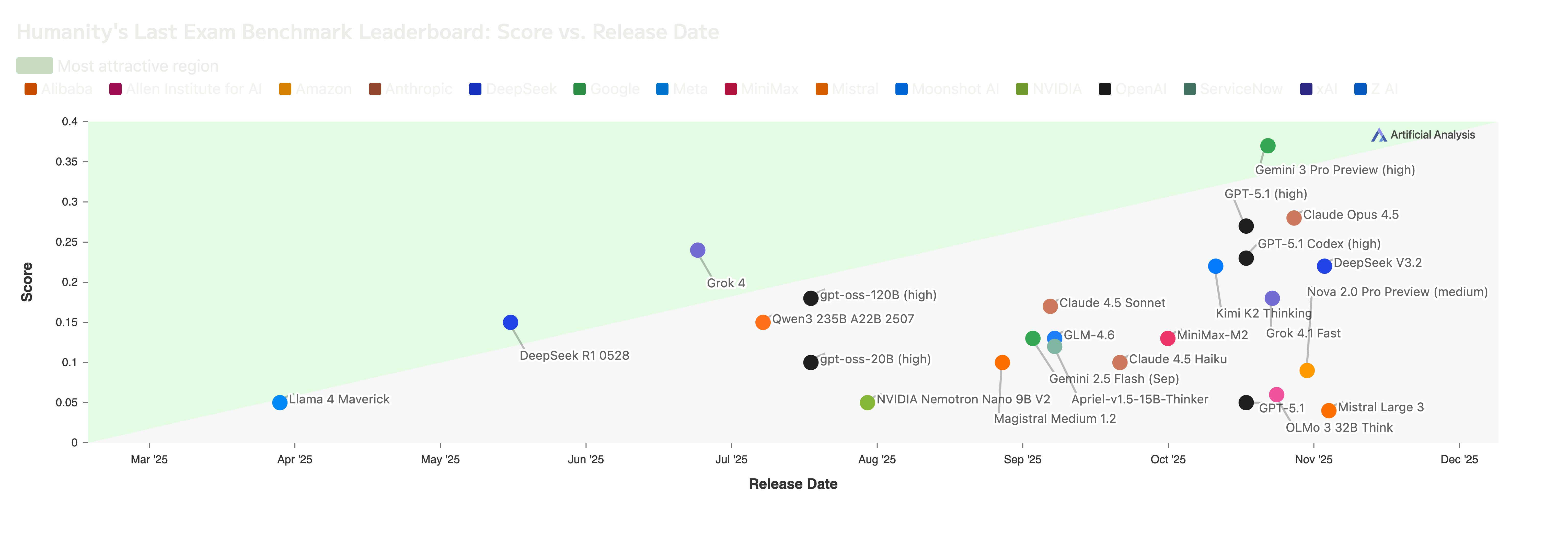
Nathan Lambert’s 2025 tier list shows Chinese labs (DeepSeek, Qwen, Kimi) now define the frontier. Their list:
- Frontier: DeepSeek, Qwen, Moonshot AI (Kimi)
- Close competitors: Zhipu (Z.Ai), Minimax
- Noteworthy: StepFun, InclusionAI / Ant Ling, Meituan Longcat, Tencent, IBM, NVIDIA, Google, Mistral
- Specialists: OpenAI, Ai2, Moondream, Arcee, RedNote, HuggingFace, LiquidAI, Microsoft, Xiaomi, Mohamed bin Zayed University of Artificial Intelligence
- On the rise: ByteDance Seed, Apertus, OpenBMB, Motif, Baidu, Marin Community, InternLM, OpenGVLab, ServiceNow, Skywork
- Honorable mentions: TNG Group, Meta, Cohere, Beijing Academy of Artificial Intelligence, Multimodal Art Projection, Huawei
No US company currently appears in their top tier.
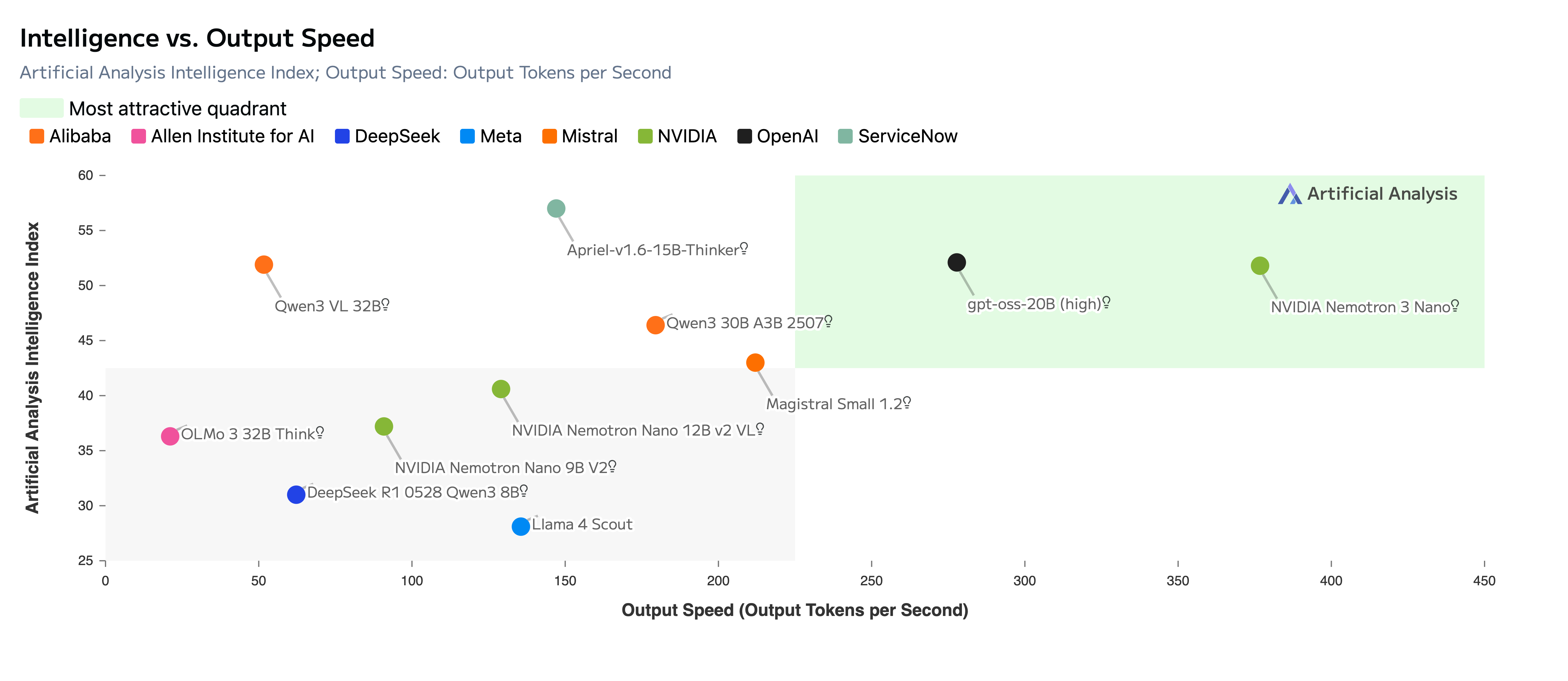
But NVIDIA’s response is to compete on efficiency and openness. NVIDIA’s Nemotron 3 claims to be the Intelligence vs. Output Speed king:
OpenRouter
-
KAT-Coder-Pro V1 from Fireworks.ai was ranked 2nd on HLE and the lowest token usage. What a bargain! It’s for coding and “agentic” work. Founded by leads from Meta PyTorch & Google Vertex at San Mateo.
- Anthropic’s Claude
- Microsoft’s Phi-1 (1.3B parameters) LLM is focused on Python coding. Microsoft’s focus is on edge devices.
List of benchmarks
https://betterbench.stanford.edu is a repository of AI benchmark assessments for informed benchmark selection through quality evaluation and best practice analysis.
Huggingface.co is the internet’s repository of LLMs. For example:
https://huggingface.co/datasets/cais/hle/viewer/default/test?p=24&views%5B%5D=test
VIDEO: Huggingface accelerate library to run
The biggest one is “Humanity’s Last Exam”,
Show your work. Get famous.
PROTIP: Look through the problems from a category (below) you might be able to solve. Explain how you solved each problem in text and video. Really solving just one problem provides proof of your academic capabilities and grit. It shows you’re not lazy enough to blindly let AI rot your brain. And it others notice you can defend against false charges of plagerism.
Making YouTube videos may get you some money. And if you find issues with a problem’s autograder, even better. File an issue on the benchmark problem GitHub repo.
PROTIP: Suggest new problems. File a PR and get listed as a contributor.
BTW I’m working on a website to encourage such evaluations and contributions, by giving out rewards and recognition (including cash). Let me know if you’re interested.
A concern about AI benchmarks is data contamination, where test questions leak into training data, enabling models to “memorize” answers instead of reasoning that connect concepts rather than just recalling facts. Thus, the Massive Multitask Language Understanding (MMLU) benchmark that evaluates language understanding is enhanced by MMLU-Pro with broader and more challenging tasks. Its Leaderboard now exceeds 90% over its 12,000 rigorously curated questions from academic exams and textbooks, spanning 14 diverse domains including Biology, Business, Chemistry, Computer Science, Economics, Engineering, Health, History, Law, Math, Philosophy, Physics, Psychology, and Others.
To raise the difficulty and reduce the chance of success through random guessing, ten answer options are given.
LLMs by subject category
Language:
- HELLASWAG (Harder Endings Longer context Low-shot Activities Situations With Adversarial Generations) to finish sentences
- MMLU (Massive Multitask Language Understanding) 15K questions
- Creative Writing
- TRUTHFULQA to test whether the LLM recognises 800 unhinged conspiracy theories as false
General safety:
- IFEval (Instruction Following)
- Instruction Following
- HarmBench of prompts to jail-break out of content moderation controls by LLMs
- Mind2Web and AITW benchmark of GUI screen object recognition to evaluate OMNIPARSER vs GPT-4V
Reasoning:
- ARC (AI2 Reasoning Challenge) from the Allen Institute for AI
- ARC is “Abstraction and Reasoning Corpus”. The best models solves 30% of the tasks.
Science:
- MT-bench as a judge of 160 questions in 8 categories of knowledge
- Science (GPQA Diamond) of 198 questions
Composite:
- Humanity’s Last Exam (Math, Physics, Computer Science, Biology/Medicine, Chemistry, Engineering, Humanities/Social Science, Other) 2500 of the most difficult closed-end questions submitted by volunteers from universities around the world.
- AGIEval 5m58s - ARVIX: Available in English (AGIEval-en) and Chinese Gaokao (AGIEval-zh), a bilingual benchmark designed to use 20 official, public, and high-standard admission and qualification exams taken by humans around tasks relevant to human cognition and problem-solving. law school admission (LSAT) tests, math competitions.
- MMMU (Massive Multitask Math Understanding) Visual Reasoning
- GSM8K (Grade School Math 8K) word problems which take 2-8 steps to solve, from OpenAI
- Math 500 Math Problem Solving
- Math (AIME) Math competition
Coding/Programming:
- WINOGRADE 44K
- Coding LCB (Live Code Bench)
- SWE-Bench (Agentic SoftWare Engineering)
- SWE-bench Lite - curated to make evaluation less costly and more accessible
- SWE-bench Multimodal featuring issues with visual elements (images, videos) from JavaScript repositories
- SWE-bench Verified - a human annotator filtered subset that has been deemed to have a ceiling of 100% resolution rate
- TAU-Bench (Task Analysis Unit) to test agentic tool use
- humaneval, humaneval+ and taco to cover the current programming benchmarks.
Humanity’s Last Exam
https://huggingface.co/datasets/cais/hle
The data folder (in parquet format) can be downloaded from: https://huggingface.co/datasets/cais/hle/tree/main
Create an account at https://agi.safe.ai/ and click “Contributors” to see submissions in the fields of Math, Physics, Computer Science, Biology/Medicine, Chemistry, Engineering, Humanities/Social Science
AGI & ASI?
VIDEO: In June 2024, Leopold Aschenbrenner wrote his situational-awareness.ai blog with this illustration:
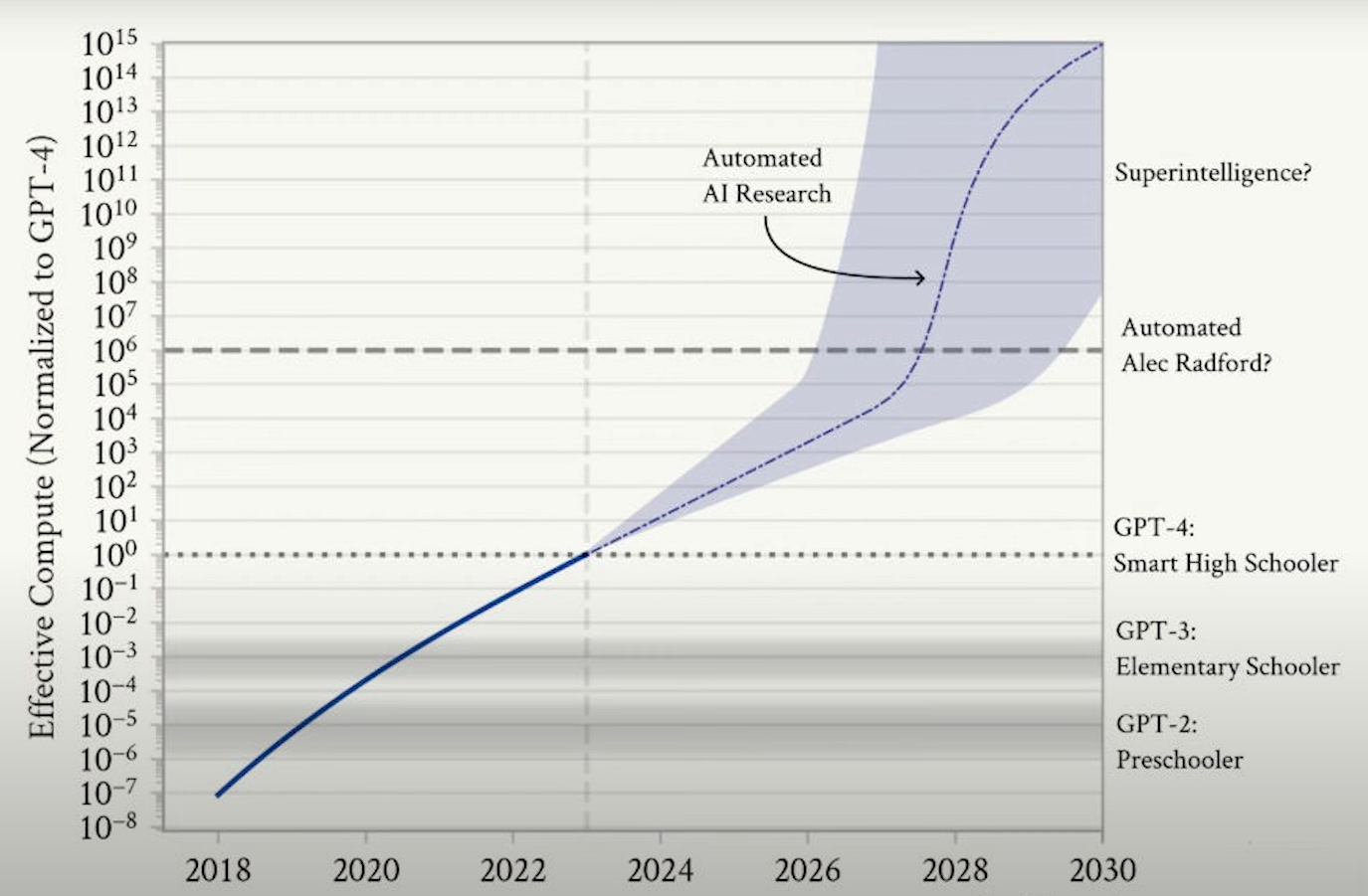
Click image to enlarge to full frame.
By 2025, AI companies have sucked up all the information that have been created by humans. The next thing is generation of new information. New problems need to be defined because, in 2025, evaluations about the extent that a particular offering has reached AGI (Artificial General Intelligence) based on a relatively small number of challenges.
ASI (Artificial Super Intelligence) will be reached when “proto-automated” researchers automate research (within massive AI datacenters).
AGIEval
Introduced 16 Dec 2023 on ARVIX (by Ruixiang Cui while working at Microsoft and during his PhD at the University of Copenhage) as “A Human-Centric Benchmark for Evaluating Foundation Models” for AGI (Artificial General Intelligence) development.
- 5m58s -
AGIEVal is called “human-centric” because its prompts are based on 20 exams: official, public, and high-standard admission and qualification exams taken by humans: SAT, law school admission (LSAT) tests, math competitions.
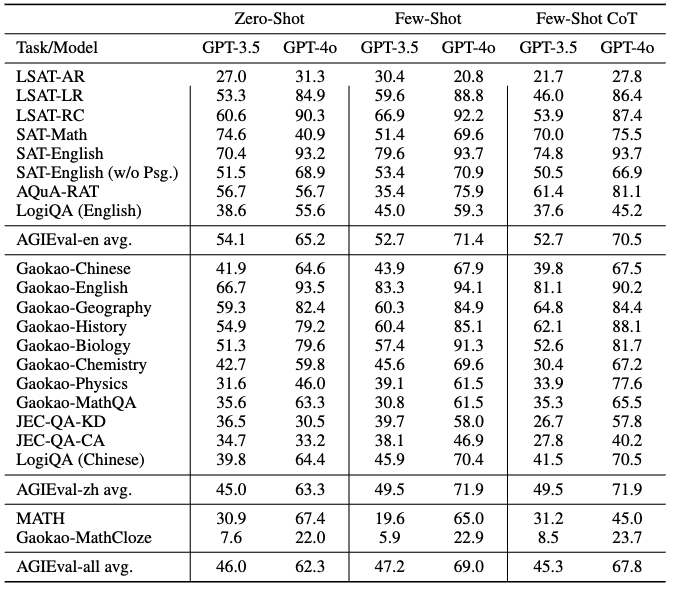
As of March 2025, the v1.1 version of the leaderboard for AGIEval shows:
- A top score in the low 70% by GPT-4o means a low “pass” for humans?
- Providing examples (Few Shot and Few Shot-COT) improved accuracy by 3.1 points (AGIEval-en).
- The newer GPT-4o with reasoning capabilities improved accuracy over GPT-3.5 by an average of 1.2 points (AGIEval-en).
- Because AGIEval is uniquely bilingual, it provides insight on the “arms race” toward AGI development between the US and China. With Few-shot GPT-4o, the achievement of 71.9% puts the Chinese (AGIEval-zh) slightly ahead of the 71.4% (AGIEval-en) for English.
An example is https://github.com/ruixiangcui/AGIEval JSONL (JSON Lines) is a lightweight, text-based data format designed for storing structured data records, where each line in the file represents a valid JSON object. This format is particularly useful for handling large datasets efficiently, as it allows for line-by-line processing without requiring the entire file to be loaded into memory.
Shown below: https://github.com/ruixiangcui/AGIEval/blob/main/data/v1_1/math.jsonl
{"passage": null, "question": "Let $\\lambda$ be a constant, $0 \\le \\lambda \\le 4,$ and let $f : [0,1] \\to [0,1]$ be defined by\n\\[f(x) = \\lambda x(1 - x).\\]Find the values of $\\lambda,$ $0 \\le \\lambda \\le 4,$ for which there exists an $x \\in [0,1]$ such that $f(x) \\neq x$ but $f(f(x)) = x.$", "options": null, "label": null, "answer": "(3,4]", "other": {"solution": "We have that\n\\[f(f(x)) = f(\\lambda x(1 - x)) = \\lambda \\cdot \\lambda x(1 - x) (1 - \\lambda x(1 - x)),\\]so we want to solve $\\lambda \\cdot \\lambda x(1 - x) (1 - \\lambda x(1 - x)) = x.$\n\nNote that if $f(x) = x,$ then $f(f(x)) = f(x) = x,$ so any roots of $\\lambda x(1 - x) = x$ will also be roots of $\\lambda \\cdot \\lambda x(1 - x) (1 - \\lambda x(1 - x)) = x.$ Thus, we should expect $\\lambda x(1 - x) - x$ to be a factor of $\\lambda \\cdot \\lambda x(1 - x) (1 - \\lambda x(1 - x)) - x.$ Indeed,\n\\[\\lambda \\cdot \\lambda x(1 - x) (1 - \\lambda x(1 - x)) - x = (\\lambda x(1 - x) - x)(\\lambda^2 x^2 - (\\lambda^2 + \\lambda) x + \\lambda + 1).\\]The discriminant of $\\lambda^2 x^2 - (\\lambda^2 + \\lambda) x + \\lambda + 1$ is\n\\[(\\lambda^2 + \\lambda)^2 - 4 \\lambda^2 (\\lambda + 1) = \\lambda^4 - 2 \\lambda^3 - 3 \\lambda^2 = \\lambda^2 (\\lambda + 1)(\\lambda - 3).\\]This is nonnegative when $\\lambda = 0$ or $3 \\le \\lambda \\le 4.$\n\nIf $\\lambda = 0,$ then $f(x) = 0$ for all $x \\in [0,1].$\n\nIf $\\lambda = 3,$ then the equation $f(f(x)) = x$ becomes\n\\[(3x(1 - x) - x)(9x^2 - 12x + 4) = 0.\\]The roots of $9x^2 - 12x + 4 = 0$ are both $\\frac{2}{3},$ which satisfy $f(x) = x.$\n\nOn the other hand, for $\\lambda > 3,$ the roots of $\\lambda x(1 - x) = x$ are $x = 0$ and $x = \\frac{\\lambda - 1}{\\lambda}.$ Clearly $x = 0$ is not a root of $\\lambda^2 x^2 - (\\lambda^2 + \\lambda) x + \\lambda + 1 = 0.$ Also, if $x = \\frac{\\lambda - 1}{\\lambda},$ then\n\\[\\lambda^2 x^2 - (\\lambda^2 + \\lambda) x + \\lambda + 1 = \\lambda^2 \\left( \\frac{\\lambda - 1}{\\lambda} \\right)^2 - (\\lambda^2 + \\lambda) \\cdot \\frac{\\lambda - 1}{\\lambda} + \\lambda + 1 = 3 - \\lambda \\neq 0.\\]Furthermore, the product of the roots is $\\frac{\\lambda + 1}{\\lambda^2},$ which is positive, so either both roots are positive or both roots are negative. Since the sum of the roots is $\\frac{\\lambda^2 + \\lambda}{\\lambda^2} > 0,$ both roots are positive. Also,\n\\[\\frac{\\lambda^2 + \\lambda}{\\lambda} = 1 + \\frac{1}{\\lambda} < \\frac{4}{3},\\]so at least one root must be less than 1.\n\nTherefore, the set of $\\lambda$ that satisfy the given condition is $\\lambda \\in \\boxed{(3,4]}.$", "level": 5, "type": "Intermediate Algebra"}}
TODO: Utility to display jsonl files for human consumption.
Upload a .json file and download it as .jsonl using online converters Code Beautify and Konbert.com
Sneaky Tricks with Benchmarks
When xAI unveiled its Grok-3 LLM on Feb 18, 2025, one analysis shows it ranking #1 across the various benchmarks (including Creative Writing, Instruction Following, etc.):
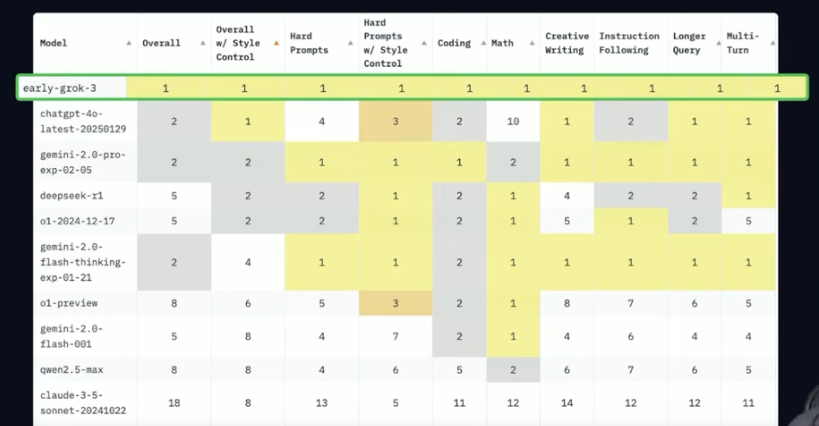
This table compares specific scores on specific benchmarks:
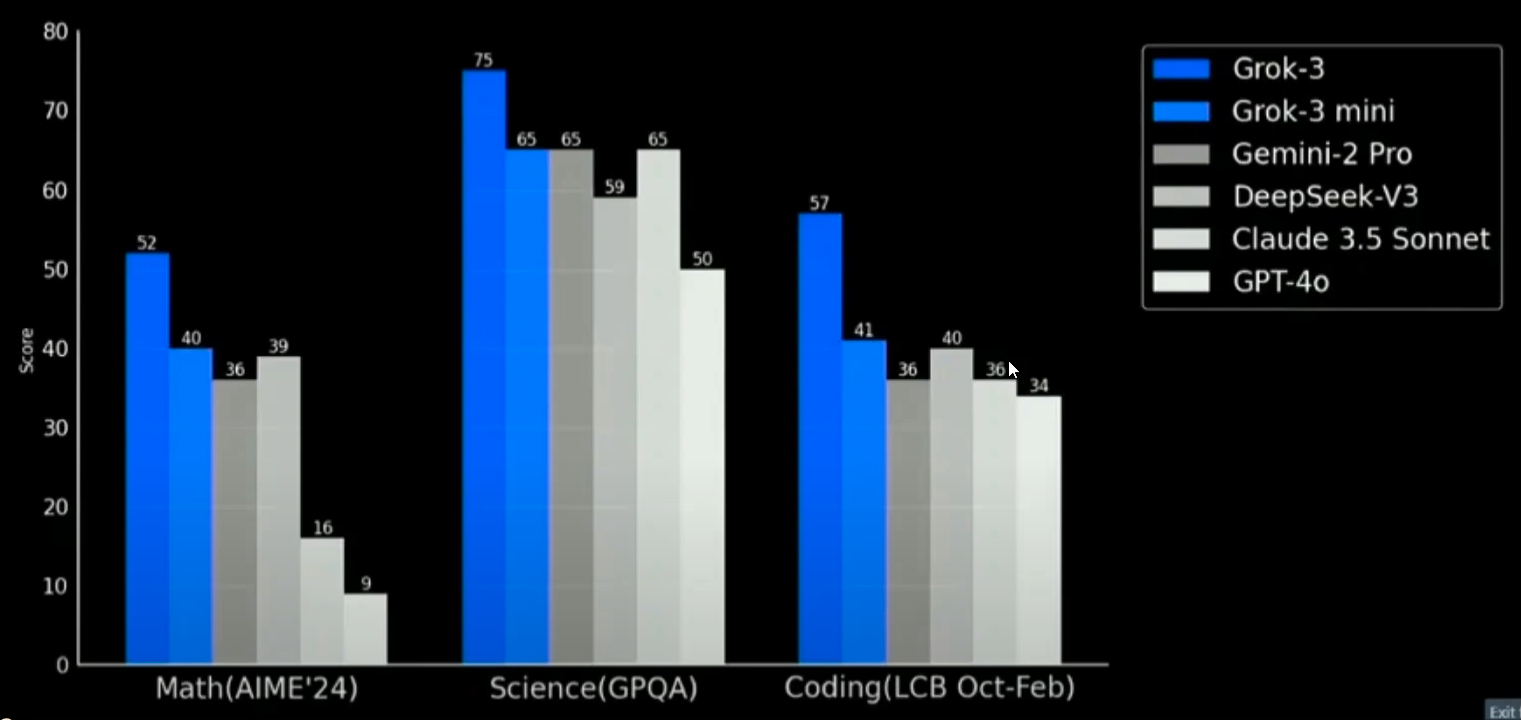
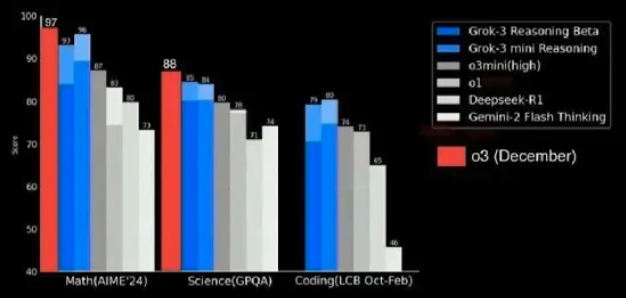
That resulted in some crying that xAI neglected to include in the comparison results of OpenAI’s o3 December results:
Claude 3.7 Sonnet
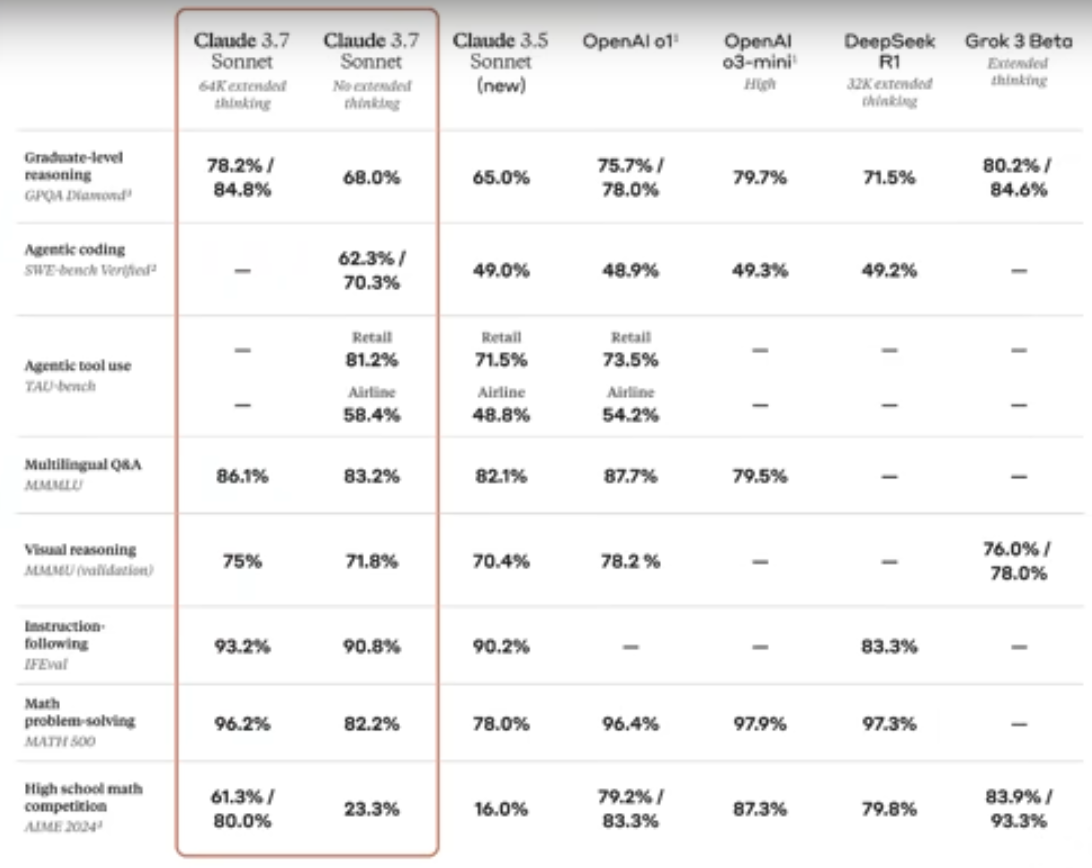
The above is from Anthropic’s Claude 3.7 Sonnet announcement on Feb 25, 2025. Dubbed the first hybrid AI reasoning model, it is a groundbreaking AI model because it allows users to control how long it “thinks” before responding to deliver real-time answers or take extra time to provide more complex, well-reasoned responses. It’s available to premium Claude users. Pricing: $3 per million input tokens and $15 per million output tokens—higher than OpenAI’s o3-mini.
Anthropic is also launching Claude Code, a tool that lets developers run AI-driven code edits directly from their terminal, analyze projects, and even push changes to GitHub.
Math Benchmarks
There are several mathematics competitions: AIME, HMMT, Mandelbrot, ARML.
Additionally, each US state:
- MCTM (Montana Council of Teachers of Mathematics)
Math notations
VIDEO: Answers of specific (discrete) values can be represented between commas within curly braces (keyed by Shift + [ and Shift + ]) in “Roster Notation (aka Roster Form)” such as this to enumerate (list) a set of elements. VIDEO:
Within curly braces { } is a “set,” i.e., a collection of elements without order or repetition rules. Commas separate elements within the set.
A = {1, 2, 3, 4,…,999}
On Macs, to open the Character Viewer, press Control + Command + Space to type in a search term:
- ℕ means Natural numbers (positive integers)
- 2ℤ means even integers (positive or negative integers)
- ℚ means rational numbers (fractions)
- ℝ
- ℂ
- Three dots between elements represents intermediate values between 4 and 999.
- Three dots at the end of the list represents infinite number of elements.
With Roster Notation, the order of elements does not matter. There is no order in a set. All elements are written in any order and only once.
An alternative is “Set Builder Form”, which defines the unique properties or conditions satisfied by all the elements of the set, using symbols:
{ x | -1 ≤ x < 6 }
- ”|” is read “such that”.
- “≤” is less than or equal symbol \leq
- ”<” is less than or not equal to \leq.
- ”>” is greater than or not equal to \geq.
Thus: All values of x such that X is less than or equal to -1 or less than 6.
{ 2x | x ∈ ℤ+ }
- “x” is \times multiplier.
- ∈ (epsilon, set by Option+E or \in) in (belongs to) “x ∈ ℤ+” is read: x among positive integers.
- ∉ (not element of)
DEFINITION: “Cardinality” is the number of elements in a set, represented as |N|.
-
n(A)
- |∅| (null, set by Option + O) means an empty set.
- ø means similar
-
|{∅}| means the size of an empty set = 1 for the empty set itself.
- ⊂ (subset) is set by \subset
- ⊆ (subset or equal)
- ∪ (union = \cup)
- ∩ (intersection), as is “Fish n Chips”
- Δ or δ (delta symbol for difference, keyed by Option + J or Option + D)
- ° (degree symbol keyed by Option + Shift + 8
- ∝ (proportional symbol ∝)
- ≈ is approximately equal \approx, keyed by Option + X. ≈
About mathematical set notation, see:
- https://www.purplemath.com/modules/setnotn.htm
- https://www.geeksforgeeks.org/maths/set-notation/
Mathjax
VIDEO: Mathematical symbols are typeset from textual notation markup in LaTeX (or ASCIImath MathML), such as:
\$$\frac{4}{9} \left( 17 - 8\cos(2\sqrt{3}) \right)$$
The \$$ at the beginning and $$ at the end specifies use of the Mathjax library to generate graphical mathematical symbols using CSS with web fonts or SVG, such as:
\(\frac{4}{9} \left( 17 - 8\cos(2\sqrt{3}) \right)\)
- \frac specifies the fraction “4/9”.
- \left specifies left parentheses.
- \right specifies right parentheses.
- \sqrt specifies square root.
$$x = {-b \pm \sqrt{b^2-4ac} \over 2a}.$$
specifies the quadratic equation:
\(x = {-b \pm \sqrt{b^2-4ac} \over 2a}\)
- \pm specifies the ⨦ plus or minus symbol.
Others:
- \ne specifies the ≠ not equal symbol.
- π is the symbol for Pi (3.14…), written as \pi or π
- ∞ is the infinity symbol ∞ written as \infty
-
e^ of P(???) specifies exponentiation to the power of {-1/3}, presented as a superscript.
- _ (underline) define subscript as in \log_2(x)
Alternatives to LaTex coding include VIDEO: Typst which enables automatically formats as you write, and thus real-time collaboration on Google Docs.
AIME
The American Invitational Mathematics Examination (AIME) is administered by the Mathematical Association of America each year as the second exam in the series of exams used to challenge high school mathletes competing to represent the US at the International Mathematics Olympiad (MOP). over 300,000 students in 50 states and over 30 countries
Students are invited to take the AIME based on their scores for exams AMC 10 for middle schoolers and AMC 12 for high schoolers offered November each year.
The questions test knowledge in algebra, geometry, counting and probability, and number theory. Both tests cover material typically covered in the first few years of high school math. Topics such as trigonometry, complex numbers, and logarithms are only needed for the AMC 12. Calculus is not required for either exam. Challenges include fundamentals in Pigeonhole Principle, Mathematical Induction, Inequalities, Diophantine Equations, and Functional Equations.
All answers are a single integer between 0 and 999. Click the “Solution” link for explanations.
In 2025, the AIME was held February 6th, with problems and answers published immediately afterwards on various YouTube channels, forums, and blogs:
- Pi Academy
- MathProblemSolvingSkills.com
- Anton Levonian
- https://areteem.org/blog/2025-aime-i-answer-key-released/
BLOG: Annie Cushing (author of Making Data Sexy), notes that “The MathArena team … worked against the clock to run evaluations using the … problems before models could start training on it.” because the challenging math problems “makes for an excellent benchmark to see how well these models reason through more complex problems, with less opportunity to get the answer correct by chance since the test isn’t multiple choice like many benchmarks.”
For use by AI, Lex code for the first of 15 problems in AIME 2025 II are at:
https://github.com/eth-sri/matharena/blob/main/data/aime/aime_2025_II/problems/1.tex
QUESTION: Print properly formatted Lex files using wlect cat ???.lex
https://matharena.ai publishes how well various LLM models reasoned about mathematics challenges in terms of Accuracy and cost of compute.
As of Feb 20, 2025:
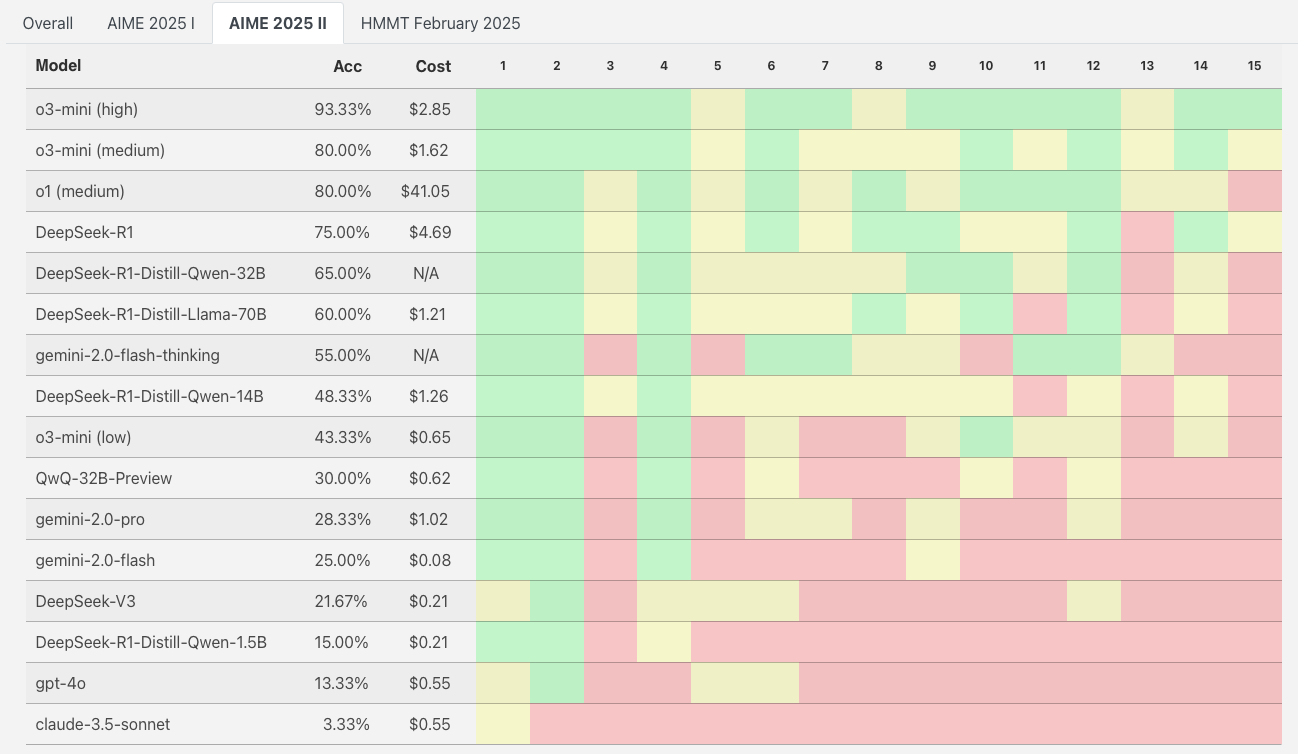
Each green box indicates the AI solved the problem >75% of 4 runs (repeated passes with the same prompt). Red boxes indicate problem solved less than 25% of passes. Yellow: Problem solved 25-75% of the time.
Stats: 150 is the highest score.
Math HMMT Feburary 2025
The HMMT (Harvard-MIT Mathematics Tournament, at hmmt.org) is a math competition founded in 1998 by students at Harvard, MIT, and schools near Boston, Massachuetts. It remains organized by students.
Each tournament draws close to 1000 students from around the globe.
WIKIPEDIA: The HMMT February tournament is generally considered to be more difficult than the American Invitational Mathematics Examination (AIME). However, difficulty varies by tournament and by round.
The top 50 scorers in the February tournament are invited to compete in the HMIC (Harvard MIT Invitational Competition), a five question proof contest.
The November tournament is easier than the February tournament, with problems similar to the AMC 10 and 12, and the AIME.
Calculus is not required for most of the problems, but it may be needed to solve some of the more difficult problems.
HMMT hosts staff exchange programs with the Princeton University Mathematics Competition (PUMaC), Carnegie Mellon Informatics and Mathematics Competition (CMIMC), and Stanford Math Tournament (SMT) to further collaboration between the competitions’ organizers. During exchanges, participants ranging from first-year members to more senior officers spend the weekend proctoring, grading, and otherwise volunteering at the host competition day-of.
Science benchmarks
GPQA
GPQA (Google-Proof Q&A) is a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry.
“Google Proof” means that the answer is not discoverable by a query on Google.com (or Perplexity.ai). The answer requires “reasoning” through several intermediate queries to a panel of “experts”.
PDF of https://arxiv.org/abs/2311.12022 says “We ensure that the questions are high-quality and extremely difficult: experts who have or are pursuing PhDs in the corresponding domains reach 65% accuracy (74% when discounting clear mistakes the experts identified in retrospect), while highly skilled non-expert validators only reach 34% accuracy, despite spending on average over 30 minutes with unrestricted access to the web (i.e., the questions are “Google-proof”).
“The questions are also difficult for state-of-the-art AI systems, with our strongest GPT-4 based baseline achieving 39% accuracy. If we are to use future AI systems to help us answer very hard questions, for example, when developing new scientific knowledge, we need to develop scalable oversight methods that enable humans to supervise their outputs, which may be difficult even if the supervisors are themselves skilled and knowledgeable. The difficulty of GPQA both for skilled non-experts and frontier AI systems should enable realistic scalable oversight experiments, which we hope can help devise ways for human experts to reliably get truthful information from AI systems that surpass human capabilities.
The GPQA Leaderboard at https://klu.ai/glossary/gpqa-eval
The GPQA Dataset at https://github.com/idavidrein/gpqa was created by I. David Rein while he was a Researcher at New York University and now part of METR FAR.AI
https://sofworld.org/pattern-questions-and-marking-scheme
- SOF ICSO - International Computer Science Olympiad
- SOF NSO - National Science Olympiad
- SOF IMO - International Mathematics Olympiad
- SOF IEO - International English Olympiad
- SOF ICO - International Commerce Olympiad
- SOF IGKO - International General Knowledge Olympiad
- SOF ISSO - International Social Studies Olympiad
- SOF International Hindi Olympiad
GAIA Real-World AI Assistant Assessment
VIDEO: https://arxiv.org/abs/2311.12983 [Submitted on 21 Nov 2023] GAIA (General AI Assistant) real-World AI assistant Benchmark evaluates AI systems on practical, real-world tasks that encompass reasoning, multi-modal processing, web browsing, and tool utilization.
Despite being conceptually simple for humans, who achieve 92% accuracy, GAIA’s 466 questions aims to pose 3 levels of challenges for AI, requiring web browsing, multi-modaity, coding, diverse file type reading, play Tetris, translation, spell checking. GPT-4 (with plugins) scored only 15%. This stark performance gap underscores GAIA’s effectiveness in benchmarking AI systems’ robustness and adaptability across diverse, everyday scenarios, emphasizing the need for AI to match or exceed average human performance on practical tasks.
BASIS
BASIS: Frontier of Scientific AI Capabilities BASIS (Benchmark for Advanced Scientific Inquiry Systems) pushes the boundaries of AI evaluation in scientific domains, surpassing even GPQA in complexity. Tailored for assessing AI systems expected to perform at or beyond human expert level, BASIS focuses on tasks demanding advanced scientific inquiry and reasoning. This benchmark is crucial for developing and evaluating AI systems capable of contributing meaningfully to cutting-edge scientific research and problem-solving, potentially accelerating breakthroughs across various scientific disciplines.
Coding LCB (Live Code Bench)

- Model names beginning with “O” such as “O3” are from OpenAI.com
- Model name “Kimi” is at https://kimi.moonshot.cn from China.
- Model name “DeepSeek” is DeepSeek.com from China.
- Model names “Gemini” are from chat.google.com
- Model names “Claude” are from Anthropic at https://claude.ai/new where it proclaims its “emphasis on what’s called “constitutional AI” - an approach to developing AI systems with built-in safeguards and values.
- Model names “Dracarys” uch as Dracarys2-Llama-3.1-70B-Instruct are in the Smaug series, a finetune of Qwen2.5-72B-Instruct developed by: Abacus.AI China at
- LLama3-70b-Ins from Meta at https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
-
DSCodder at https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-base
- Where is IBM WatsonX in this list?
Over time, a larger fraction of difficult problems are introduced with model capability improvements. A drop in performance in the later months is expected.
https://livecodebench.github.io says LCB (Live Code Bench) collects problems from periodic contests on
- LeetCode,
- AtCoder, and
-
Codeforces (ELO). VIDEO
VIDEO: Build a game usong ChatGPT 03 Mini O3-mini achieved a perfect 10/10 on pylint for a Hangman game project.
LLM platforms use them for constructing a holistic benchmark for evaluating Code LLMs across variety of code-related scenarios continuously over time.
The livecodebench runner is Naman Jain CS Ph.D. Berkeley.
Shangdian (King) Han living in Berkeley, California. Previously Microsoft Research.
OpenAI o3 scored among the top 10 contestants in Codeforces.com competitive programming solving complex problems under time constraints (2.5 hours).
LiveCodeBench.com publishes four Leaderboards: For each leadershboard provides a time slider. As of this writing:
- 880 Code Generation
- 713 Self Repair
- 442 Test Output Prediction
-
479 Code Execution
- Not Kaggle competitions?
Models submitted for evaluation are at https://github.com/LiveCodeBench/submissions
For a more nuanced evaluation of LLM performance across different difficulty levels,
“Pass@1” measures the percentage of problems a model can solve correctly on its first attempt across all difficulty levels.
“Easy Pass@1” refers to the Pass@1 performance on problems categorized as “Easy”.
See https://openreview.net/forum?id=chfJJYC3iL
At https://github.com/LiveCodeBench/LiveCodeBench/blob/main/lcb_runner/prompts/code_execution.py
prompts begin with:
system_message = "You are an expert at Python programming, code execution, test case generation, and fuzzing."
``
You are given a Python function and an assertion containing an input to the function. Complete the assertion with a literal (no unsimplified expressions, no function calls) containing the output when executing the provided code on the given input, even if the function is incorrect or incomplete. Do NOT output any extra information. Execute the program step by step before arriving at an answer, and provide the full assertion with the correct output in [ANSWER] and [/ANSWER] tags, following the examples. ```
Its dataset of “448” multiple-choice questions is in the password-protected 2.2MB dataset.zip file at https://github.com/idavidrein/gpqa/blob/main/dataset.zip
VIDEO: Here’s a question about use of hour glasses that Grok3 cannot solve in 3 minutes.
VIDEO “Write a chess engine using the UCI (Universal Chess Interface) protocol”
SWE-Bench benchmark
SWE-Bench (Software Engineering Benchmark) at https://www.swebench.com involves giving agents a code repository and issue description, and challenging them to generate a patch that resolves the problem described by the issue.
https://www.swebench.com/#verified
https://github.com/swe-bench/sb-cli/ provides the CLI to run the benchmarks.
SWE-Bench has been used as the way to compare how well LLM offerings tests systems’ ability to automatically solve GitHub issues in a dataset containing 2,294 Issue-Pull Request pairs from 12 popular Python repositories:
- astropy (95)
- Django (850)
- Flask (11)
- matplotlib (184)
- pylint (57)
- pytest (119)
- requests (44)
- scikit-learn (229)
- seaborn (22)
- sphinx (187)
- sympy (386)
- xarray (110)
The 10 Oct 2023 Arxiv article describes the unit test verification using post-PR behavior as the reference solution.
- "Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation tasks."
Those working on it include carlosej@princeton.edu and johnby@stanford.edu
CodeClash
https://codeclash.ai/
This evaluates 8 models on 6 arenas across 1680 tournaments at 15 rounds each (25,200 rounds total), generating 50k agent trajectories.
An LLM’s success over several “rounds” is measured by relative scores like income, territory control, survival in 6 “arenas”:
-
Battlesnake: Snake AIs compete to survive and grow in a grid
-
Core War : Redcode warriors battle to control a virtual computer
-
Halite : Distribute resources wisely to conquer territory
-
Poker : No Limit Texas Hold’em with 2+ players
-
RoboCode - Tank combat - outlast and outgun opponents
-
RobotRumble : Program swarms to overwhelm opponents
https://viewer.codeclash.ai/ shows the leader – Anthropic Sonnet 4 and 4.5 – score between 30 to 70.
Instead of explicit GitHub issues or tasks to solve (like other benchmarks), competitors are given just a high-level objective (goals) so models decide for themselves what to build.
Each round has two phases: edit, then compete. In the edit phase, models get to improve their codebase as they see fit. Write notes, analyze past rounds, run test suites, refactor code – whatever helps.
In each round, the LLM analyzes gigabytes of logs, adapt strategies, implement algorithms, and make all high- to low-level decisions.
Competition logs are then copied back to each model’s codebase and the next round begins.
https://github.com/CodeClash-ai/CodeClash
Creative Writing
Coming soon.
Instruction Following
Coming soon.
https://www.youtube.com/watch?v=a6bPt9oyoa8&t=1m32s “retirement will come for most people sooner than they think”. Brandage: Ex OpenAI Employee Gives Warning About The Economy TheAIGRID
https://www.youtube.com/watch?v=REjFL9hkkL4 Anthropic’s Chilling 18-Month Warning: AI Apocalypse in 18 Months TheAIGRID
https://www.youtube.com/watch?v=379s4W_EaTk
https://www.youtube.com/watch?v=379s4W_EaTk&t=9m3s LLM Engineer’s Handbook (from Packt) by Paul Lustzien,
OmniParser https://microsoft.github.io/OmniParser/
https://www.youtube.com/watch?v=kkZ4-xY7oyU&t=2m11s PersonaQA for Hallucination Evaluation
Language Translations
COMET, BLEU, and CHRF are widely used metrics for evaluating machine translation (MT) quality.
https://www.perplexity.ai/search/what-is-the-comet-score-for-tr-9RkzS6rsRr6R9oyBwYZvag
Evaluation Quality Metrics
It depends on what you are trying to achieve.
- Classification tasks are measured using the “Accuracy” metric.
- Regression tasks are measured using mean squared error (MSE).
-
Generation tasks are measured using mean squared error (MSE).
- Task allocation tasks are measured using the F1 score.
- Text summarization tasks are measured using the ROUGE score.
- Question answering tasks are measured using the BLEU score.
https://bomonike.github.io/ai-benchmarks
25-12-16 v030 Nemotron :2024-12-28-ai-benchmarks.md created 2024-12-28