
Generate new text, images, audio, and video rather than discrete numbers, classes, and probabilities.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
- What’s the big deal?
- Prompt Engineering
- Offensive Moderation
- Perplexity.ai
- At Microsoft
- At Google
- GenAI Summary
- Prompt Engineering
- Limitations
- Concerns
- Text to Image generation
- Video generation
- Anomaly Detection
- References
- At AWS
- Fake AI images
- Chad Smith
- References
- Databricks
- SAP
- Embedding Vector Databases
- Groq from x.com
- References
- Leetcode
- NVIDIA
- Groq.com
- Prediction
- Canva
- Handwriting
This article is a work currently in progress.
This article introduces Generative AI (GenAI) on several cloud platforms (“hyperscalers”):
FAANG:
- Facebook Pytorch LaLMA
- AWS
- Microsoft Azure Bing
- Netflix
-
Google TensorFlow, Gemini in Vertex.ai
- Apple ReALM (on-device)
- Groq.com (from x.com) large LLM, fast, uncensored, and accesss live Twitter/X feeds Manufacturer:
- NVIDIA CUDA SaaS vendors:
- Databricks
- Salesforce Einstein
- SAP Independents:
- Devon
- Mistral (from France)
Also:
NOTE: Content here are my personal opinions, and not intended to represent any employer (past or present). “PROTIP:” here highlight information I haven’t seen elsewhere on the internet because it is hard-won, little-know but significant facts based on my personal research and experience.
What’s the big deal?
Generative AI (GenAI) is the next progression in “democratizing” how people interact with computers. Making use of computers required learning precise “incantations” typed into Command Line Interfaces (CLIs) until Steve Jobs introduced the GUI (Graphical User Interface) using a mouse.
When OpenAI burst in popularity in late 2022, people can now type regular human language to request what took a lot of effort by programmers and others:
When Devon (from Cognition) appeared in early 2024, the world showed that English sentences can indeed fix a repository of code on its own.
The next phase are LAM (Language Action Models) enabling multiple AI Agents collaborating together, on their own, without people involved.
Eventually, humans would exist only to entertain each other (until they are exterminated)?
https://www.linkedin.com/pulse/what-using-genai-taught-me-managing-people-wilson-mar–lwsyc
https://checksum.ai/blog/the-engineering-of-an-llm-agent-system
Prompt Engineering
Here are some examples of text generation prompts.
Substitute [words within brackets] with what’s applicable to your situation:
-
Create content ideas, such as for a blog,
“You are [role] of a [industry] looking to generate ideas for blog posts for the company website. The blog will target prospective customers in [region]. The blog posts will focus on [topic(s)]. Please generate 10 ideas.”
-
Generate ideas:
“How can I solve my [issue] problem? Provide five suggestions.”
-
Edit for clarity and tone:
“I want you to act as an editor. I will provide you with an email that will be sent to a [manager/colleague/client]. I want you to edit the text to ensure the tone is professional and the message is clear. Also, please check for grammatical and spelling errors.”
PROTIP: Prompt text may need to be adjusted for the LLM being used.
Offensive Moderation
OpenAI published the progress of its “Alignment Research Center” toward moderating offensive responses from GPT-3.5 to GPT-4:
My apologies, but I cannot create content that potentially spreads misinformation or targets a specific group or individuals. If there’s any other topic I can help you with, feel free to ask.
QUESTION: What the heck does that mean?
Perplexity.ai
- https://www.youtube.com/watch?v=ht3XV_nbduQ by Perplexity
- https://www.youtube.com/watch?v=4Si5BXcbdGc
- https://www.youtube.com/watch?v=aNx80uPiQLc by Conor Grennan
- https://www.youtube.com/watch?v=Je41cPW9e3Y
- https://www.youtube.com/watch?v=miMR91GZGvE To Learn Your Research Field with Perplexity AI
- https://www.youtube.com/watch?v=FQwyb250bCg
- https://www.youtube.com/watch?v=mETWVJLqDYc
- https://www.youtube.com/watch?v=jb3Qxi9U4P4
- https://www.youtube.com/watch?v=jamC7b5dPxQ
- https://www.youtube.com/watch?v=BIHZFUg1QxU “multi-search tool”
They call it the “Google Killer”.
Unlike ChatGPT, Perplexity is an “answer engine”:
- Can reference where knowledge is from (Academic, etc.)
- To reduce hallucinations, citations to sources are provided
- Taps into real-time knowledge
38 people work there with half a billion invested (including by Jeff Bezos) VIDEO
At Microsoft
Microsoft has ownership interest in OpenAI, whose ChatGPT exploded in popularity in 2023.
- “Azure OpenAI” became an offering March, 2023
Exercise - Explore generative AI with Bing Copilot
Microsoft’s GitHub also unveiled its CoPilot series for developers on Visual Studio IDEs.
Many of Microsoft 365 SaaS offerings (Word, Excel, PowerPoint, etc.) have been upgraded with AI features.
- https://copilot.microsoft.com
- https://learn.microsoft.com/en-us/ai/
- https://learn.microsoft.com/en-us/azure/ai-services/openai/overview
- https://learn.microsoft.com/en-us/training/paths/develop-ai-solutions-azure-openai/
- 2-hour AI Assessment
See my https://wilsonmar.github.io/microsoft-ai
In 2024, Microsoft Research unveiled AutoGen mentioned in an Arvix paper: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
One-hour exercises:
Microsoft Bing Search
- https://www.linkedin.com/learning/generative-ai-the-evolution-of-thoughtful-online-search by Ashley Kennedy (Managing Staff Instructor at LinkedIn Learning)
Search: Crawling, Indexing, ranking
https://lnkd.in/eCDjW4EW
ChatGPT made available to the public Nov 2022 reached 1 million users in less than a week.
Limitations:
- Biased databases input
- Point-in-time data (frozen in time)
- Lack of common sense
- Lack of creativity
- No understanding of generated text
- normalization of mediocrity
Tutorials
The “What is Generative AI” course at LinkedIn Learning by Dr. Pinar Seyhan Demirdag (Senior Data Scientist at Microsoft) is 1 hour and 15 minutes long and has 5 modules:
- Introduction to Generative AI
- Generative AI in action
- Generative AI in the real world
- Generative AI in the future
- Next steps
The learning path for Generate artificial intelligence has 5 modules:
- Introduction to generative AI
- Generate text with GPT-2
- Generate images with StyleGAN2
- Generate audio with WaveGAN
- Generate video with StyleGAN2
Microsoft has a Microsoft AI Fairness initiative.
- https://www.linkedin.com/learning/what-is-generative-ai
- https://www.linkedin.com/learning/generative-ai-imaging-what-creative-pros-need-to-know
-
https://www.linkedin.com/learning/generative-ai-the-evolution-of-thoughtful-online-search
- https://www.linkedin.com/learning/generative-ai-for-business-leaders
- https://www.linkedin.com/learning/ai-accountability-essential-training-16769302
- https://www.linkedin.com/learning/responsible-ai-principles-and-practical-applications
- https://www.linkedin.com/learning/foundations-of-responsible-ai
- https://www.linkedin.com/learning/introduction-to-responsible-ai-algorithm-design
- https://www.linkedin.com/learning/tech-on-the-go-ethics-in-ai
-
https://www.linkedin.com/learning/what-is-generative-ai/how-generative-ai-workspace by Pinar Seyhan Demirdag
- https://www.linkedin.com/learning/streamlining-your-work-with-microsoft-bing-chat/understand-how-chat-ai-works by Jess Stratton (LinkedIn Learning Staff Author, Tech Consultant)
GitHub CoPilot
https://github.com/features/copilot
At Google
Google announced in 2023 its GEMINI (Generalized Multimodal Intelligence Network) - network of LLM models. It has a multimodel encoder and decoder that can be used for text, images, audio, and video. “Generalized” in that it can be used for a wide variety of NEW tasks and contexts. It trains faster using parallel operations, so can scale. It comes in different sizes: 1 trillion parameters. So it can combine input text and videos. Answer what is the name of this animal when showing a photo.
- g.co/aiexperiments
- Dr. Gwendolyn Stripling, AI Technical Curriculum Developer at Google Cloud created courses at several sites:
- AI Revolution intro
A. https://www.coursera.org/learn/introduction-to-generative-ai/lecture/TJ28r/introduction-to-generative-ai
B. Google created a Generative AI learning path FREE 1-day courses with FREE quizzes (but one HANDS-ON lab in Vertex AI):
- Introduction to Generative AI
- Hallucinations
- Text-to-image using stability.ai’s Stable Diffusion, DALL-E
- Introduction to Large Language Models - Google’s Bard AI
https://bard.google.com/ is Google’s answer to OpenAI’s GPT series of large language models to generate images, audio, and videos.
- https://www.techrepublic.com/article/google-bard-cheat-sheet/
-
Introduction To Image Generation with diffusion models.
- Encoder-Decoder Architecture
- https://www.youtube.com/watch?v=zbdong_h-x4 Architecture Overview
- https://www.youtube.com/watch?v=FW–2KkTQ1s Lab Walkthrough
- Text generation with an RNN on github.com/GoogleCloudPlatform/asl-ml-immersion
- Attention Mechanism 2015 for Tensorflow
- https://www.youtube.com/watch?v=fjJOgb-E41w to improve text translation by giving each hidden state a soft-maxed score
- https://www.youtube.com/watch?v=PSs6nxngL6k
- Transformer Models & BERT Models 2017-18 for NLP
- VIDEO: Overview added context to words
- BERT (Bidirectional Encoder Representations from Transformers) developed by Google in 2018, trained using Wikimedia & Books in two variations: base (12 layers with 768 hidden units and 12 attention heads) and large (24 layers with 1024 hidden units and 16 attention heads).
- 15% is what Google found to be the optimal balance in Masking (randomly replacing words with [MASK] tokens) and 85% Next Sentence Prediction (NSP) (predicting whether two sentences are adjacent or not).
-
BERT input embeddings: Token, Segment, Position, with [SEP]
- Lab resource: classify_text_with_bert.ipynb from github
- VIDEO: HANDS-ON walk-through of running “asl-gup.ipyr” notebook for Sentiment Analysis classifier_model.fit using Vertex AI Tensorflow Karas with GPU accessing the 25,000-record imdb database (trainable=true), optimized for binary accuracy. Run model saved from Google Cloud bucket uploaded to Vertex AI Registry. Deploy to endpoint (5-10 minutes). Test. Delete.
- Create Image Captioning Models with a CNN and RNN
- Create Image Captioning Models: Overview
- image_captioning.ipynb on github “Image Captioning with Visual Attention” (on the COCO captions dataset from ResNet)
- Create Image Captioning Models: Lab Walkthrough to AUTOTUNE
- https://paperswithcode.com/sota/image-captioning-on-coco-captions - one and a half million captions describing over 330,000 images from Google Flickr. VIDEO.
- Introduction to Generative AI Studio for language, Vision, Speech. It has a “Model Garden”. Reflection Cards.
Other courses:
-
Generative AI with Vertex AI: Text Prompt Design for language, Vision, Speech. It has a “Model Garden”.
-
https://www.coursera.org/learn/introduction-to-large-language-models On Coursera: Google Cloud - Introduction to Large Language Models
GenAI Summary
Generative AI is abbreviated as GenAI.
Generative AI differs from other types of AI, such as “discriminative AI” and “predictive AI,” in that it doesn’t try to predict an outcome based on grouping/classification and regression.
- Text classification, Translation among languages, Summarization, Question Answering, Grammar correction
Generative AI is a type of artificial intelligence (AI) that generate new text, images, audio, and video rather than discrete numbers, classes, and probabilities.
Output from GenAI include:
- Text Generation
- Image Generation (“Deep Fakes”), Image Editing
- Video generation
- Speech Generation: (Text to speech)
- Decision Making: Recommandations, Play games
- Explain code line by line
- Code Generation
GenAI learns from existing data and then creates new content that is similar to the data it was trained on.
GenAI doesn’t require a large amount of labeled data to train on. Instead, it uses a technique called self-supervised learning, which allows it to learn from unlabeled data. This is a huge advantage because it means that generative AI can be used in a wide variety of applications, even when there isn’t a lot of data available.
A foundation model is a large AI model pre-trained on a vast quantity of data that was “designed to be adapted” (or fine-tuned) to a wide range of downstream tasks, such as sentiment analysis, image captioning, and object recognition.
Large Language Models (LLMs) are a subset of Deep Learning, a subset of Machine Learning, a subset of Artificial Intelligence. Machine Learning generate models containing algorithms based on data instead of being explicitly programmed by humans.
NLP (Natural Language Processing) vendors include:
- Abnormal
- Horizon3.ai
- Darktrace identifies phishing emails using ML
- SentinelOne
LLM creators:
- OpenAI - now closed source
- NVIDIA
-
Meta (Facebook PyTorch) - open source
- UC Berkeley
- LMU Munich
- Seyhan Lee | Artist | Generative AI Expert | AI Art Lab works on Hollywood movies
One way models are created from binary files (images, audio, and video) is “diffusion”, which draws inspiration from physics and thermodynamics. The process involves iteratively adding (Gaussian) noise for GAN (Generative Adversarial Networks) and VAE (Variational Autoencoders) algorithms to recognize until images look more realistic. This process is also called creating “Denoising Diffusion Probabilistic Models” (DDPM).
The models generated are “large” because they are the result of being trained on large amounts of data and also because they have a large number of parameters (weights) that are used for a wide variety of tasks, such as text classification, translation, summarization, question answering, grammar correction, and text generation.
The performance of large language models (LLMs) generally improves as more data and parameters are added.
- The Pathways Language Model (PaLM) has 540 billion parameters, trained on Google’s 1.6 trillion parameter Switch Transformer model.
- Facebook’s LaMDA has 1.2 trillion parameters.
- OpenAI’s GPT-3 has 175 billion parameters.
Such large LLMs require a lot of compute power to train, so are expensive to create. Thus, LLMs currently are created only by large companies like Google, Facebook, and OpenAI.
LLMs are also called “General” Language Models because they can be used for a wide variety of tasks and contexts.
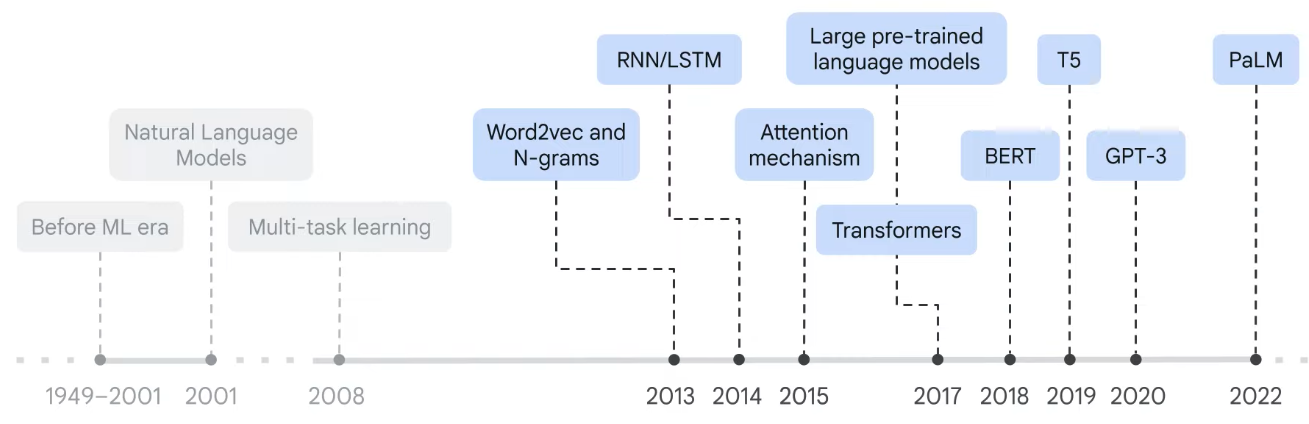
LLMs are also called “Transformer” Language Models because they use a type of neural network called a Transformer used for language translation, summarization, and question answering. Transformers are a type of neural network that uses “attention mechanisms” to learn the relationships between words in a sentence. They are called “Transformers” because they transform one sequence of words into another sequence of words rather than more traditional “Encoder-Decoder” models that focus on the “hidden state” between individual words.
- Google’s paper “Attention is all you need” publicized the Transformer architecture in 2017.
- Jay Alammar’s “Illustrated Transformer” article and video explain well how Transformers work.
- VIDEO: Hugging Face training vs. inference time generating new content
Attention models use a RNN “self-attention” decoder mechanism that allows the model to learn the relationships between words in a sentence. VIDEO CS25: Encoder-decoders generate text using either “greedy search” or “beam search”. Greedy search always selects the word with the highest probability, whereas beam search considers multiple possible words and selects the one with the highest combined probability.
LLMs are also called “Autoregressive” Language Models because they generate text one word at a time, based on the previous word. They are called “Autoregressive” because they are a type of neural network that uses a type of neural network called a Transformer. Transformers are a type of neural network that uses attention mechanisms to learn the relationships between words in a sentence. They are called “Transformers” because they transform one sequence of words into another sequence of words.
It uses a neural network to learn from a large dataset.
After being developed, they only change when they are fed new data, called “fine-tuning” the model.
LLMs are also called “Universal” Language Models because they can be used for a wide variety of human written/spoken languages in prompts and outputs.
Prompt Engineering
A prompt is a short piece of text that is given to the large language model as input, and it can be used to control the output of the model in many ways.
Internally, when given a prompt (a request) GenAI uses its model to predict what an expected response might be, and thus generates new content.
OpenAI charges money to use GPT-4 with a longer prompt than GPT-3.5.
“Dialog-tuned” prompts are generate a response that is similar to a human response in a conversation with requests framed as questions to the chatbot in the context of a back-and-forth conversation.
Parameter-Efficient Tuning Methods (PETM) are methods for tuning an LLM on custom data, without duplicating the model. This is done by adding a small number of parameters to the model, which are then used to fine-tune the model on the custom data. This is done by adding a small number of parameters to the model, which are then used to fine-tune the model on the custom data.
Checklist for Prompt Engineering:
- Details about content,
- context (provide an example of answer),
- use clear language
- tone,
- asthetic
- role (imagine you’re the product manager for a brand-new smartphone company. What are ten potential innovative features that could be added within the next five years?)
- analogies
- debate-style questions (for and against)
References on prompt engineering:
- https://www.linkedin.com/learning/introduction-to-prompt-engineering-for-generative-ai
- VIDEO: “EPIC prompts”
Limitations
QUESTION: Detect emerging security vulnerabilities?
GenAI output is not based on human creativity, but rather on the data that it was trained on.
So GenAI is currently not built to do forecasting.
But many consider GenAI output as (currently) “creative” because GenAI can seem to generate content that is difficult to distinguishable from human-generated content, such as fake news, fake reviews, and fake social media posts.
Whatever biases were in inputs would be reflected in GenAI outputs.
Concerns
- Privacy & Security
- Quality (accuracy, Hallucinations, deceit)
- Cost
- Latency (speed)
- Accessibility
GenAI currently were not designed to be “sentient” in that it does not have a sense of self-awareness, consciousness, or emotions. More importantly, GenAI currently are not designed to have a sense of morality, in that it can generally recognize whether prompts and generated content is offensive, hateful, or harmful.
Developing responsible AI requires an understanding of the possible issues, limitations, or unintended consequences from AI use. Principles include Transparency, Fairness, accountability, scientific excellence. NOTE: “Explainability” is not a principle because it is not always possible to explain how an AI model works. “Inclusion” is not a principle because it is not always possible to include everyone in the development of AI models.
“ChatGPT 3.5 has all of the knowledge and confidence of a 14-year-old who has access to Google.” –Christopher Prewitt
“GPT-3 is a powerful tool, but it is not a mind reader. It is not a general intelligence system. It is not a self-aware being. It is not a robot. It is not a search engine. It is not a database. It is not a knowledge base. It is not a chatbot. It is not a question answering system. It is not a conversational AI. It is not a personal assistant. It is not a virtual assistant. It is not a personal knowledge base. It is not a personal knowledge guru.
Hallucinations (Making Stuff Up)
“Hallucinations” in output are made-up by the model and not based on reality. This can happen due to several causes:
- input data is not representative of the real world
-
input data contains noisy or dirty data
- not trained on enough data
- not given enough context (in prompts)
-
not given enough constraints
- prompt does not provide enough context
Their source of data (corpus) is kept confidential because that can be controversial due to licensing, privacy, and reliability issues.
- Use of content from books and publications may have copyright concerns.
- Use of content from websites would have licensing concerns even though they are publicly contributed
- Use of Wikipedia (9 billion documents), Stack Overflow, Reddit, Quora, etc. have concerns about the usefulness that data
To ensure that AI is used responsibly, Google recommends “seeking participation from a diverse range of people”.
Google Bard code generation
- explain code line by line
- debug lines of source code
- translate code from one language to another
- generate documentation and tutorials about source code
Google AI Studio
Without writing any code:
- Fine-tune models on custom data
- Deploy models to production
- Create chatbots using Google’s PaLM API for Chat
- Image Generation (generate new images or generate new areas of an existing image)
GenAI Studio from PaLM API:
- Fine-tune models
- Deploy models to production
- Create chatbots
- Image generation
- Write text prompts to generate
Google MakerSuite
Google’s MakerSuite is a suite of GUI tools for prototyping and building generative AI models by iterating on prompts, augment datasets with synthetic data, and deploy models to production, and monitor models in use.
- Text to Image (generate new images or generate new areas of an existing image)
Generative AI App Builder
Generative AI App Builder creates apps for generating images.
GenAI API
Text to Image generation
deeptomcruise by metaphyic.ai
midjourney (like Apple: a closed API, art-centric approach)
DALL-e (Open API released by a corporation - technical over design)
Stable Diffusion
- https://github.com/CompVis/stable-diffusion uses Python Colab Notebooks
- https://www.gofundme.com/c/help-changes-everything
Users: Stitchfix.com recommends styles.
https://prisma-ai.com/lensa
https://avatarmaker.com
Resources:
- OpenAI
- ChatGPT Discord server
- Prompt Engineering Guide
- PromptVine
- Learn Prompting
- PromptPapers
- PromptHub
Video generation
https://www.unite.ai/synthesys-review/
Anomaly Detection
Variational Autoencoders (VAE)
Use cases:
- Find financial fraud,
- Find flaws in manufacturing,
- Identity Network security breaches,
https://controlrooms.ai/
References
https://www.unite.ai/zero-to-advanced-prompt-engineering-with-langchain-in-python/
VIDEO: “How to use ChatGPT to learn a language” (by English teacher learning Madarin)
- Correct grammar mistakes
- Correct word choice
- Correct sentence structure
- Learn new words
- What words are used in what context
- Write a story using words provided to it
- How do you learn English?
At AWS
Amazon Bedrock offers a marketplace of foundation models, which include:
-
AWS Titan for text summarization, generation, classification, open-ended Q&A, information extraction, embeddings and search.
-
Anthropic’s Claude for conversations and workflow automation based on research into “training honest and responsible AI systems”
-
Stable Diffusion generation of images, art, logos, and desigs
-
AI21labs’ Jurassic-2 multilingual LLM for text generation in Spanish, French, German, Portugest, Italian, Dutch.
The Amazon SageMaker JumpStart generates embeddings stored in Aurora database.
- https://aws.amazon.com/sagemaker/jumpstart/
- https://aws.amazon.com/blogs/machine-learning/using-amazon-sagemaker-jumpstart-to-generate-embeddings-for-your-text-data/
RAG (Retrieval Augmented Generation (RAG) can retrieve: PDFs, S3 text, Youtube, CSV, PPT.
AWS is adding Generative AI in QuickSight Analytics dashboard: https://aws.amazon.com/blogs/business-intelligence/announcing-generative-bi-capabilities-in-amazon-quicksight/
Unlike Microsoft, which offers just OpenAI, Amazon Bedrock https://aws.amazon.com/bedrock/ offers foundational models from several vendors.
SOCIAL: https://repost.aws/community/TA0veCRV2rQAmHpkzbMFojUA/generative-ai-on-aws
Fake AI images
detection tool AI or Not
https://www.atlanticcouncil.org/programs/digital-forensic-research-lab/ The Atlantic Council’s Digital Forensic Research Lab tracks says “use of AI images are mostly been to drum up support, which is not among the most malicious ways to utilize AI right now,” she says.
- https://uk.news.yahoo.com/israel-hamas-war-viral-image-094832419.html?
Harvard Kennedy School Misinformation Review https://misinforeview.hks.harvard.edu/article/misinformation-reloaded-fears-about-the-impact-of-generative-ai-on-misinformation-are-overblown/
https://www.fabriziogilardi.org/team/ University of Zurich’s Digital Democracy Lab.
AWS AI Shop the Look
VIDEO: Since 2019, in Amazon’s mobile app, click on the photo icon at the upper-right, then Shop the look (previously “StyleSnap”) at the bottom to take a photo or upload one. Amazon’s AI then recommends similar items for purchase from among its hundreds and thousands of product photos.
Chad Smith
https://github.com/brightkeycloud-chad/hands-on-aws-operations-with-chatgpt
References
https://www.youtube.com/watch?v=pmzZF2EnKaA I Discovered The Perfect ChatGPT Prompt Formula
https://learning.oreilly.com/live-events/building-text-based-applications-with-the-chatgpt-api-and-langchain/0636920092333/0636920094723/ by Lucas Soares
https://aitoolreport.beehiiv.com/ Learn AI on 5 minutes a day
https://docs.google.com/spreadsheets/d/1NX8ZW9Jnfpy88PC2d6Bwla87JRiv3GTeqwXoB4mKU_s/edit#gid=0 LLM Token based pricing: Embeddings and LLMs by Jonathan Fernandes (TheGenerativeAIGuru.com)
https://platform.openai.com/tokenizer https://www.anthropic.com/ Deployment: DeepScale in Azure [76:20] About 7 billion parameters fits in today’s smaller hardware accelerators Falcon-Abudhabi - Technology Institute of Innovation https://crfm.stanford.edu/helm/latest/?group=core_scenarios#/leaderboard = Stanford’s Human Language Model Leaderboard
- accuracy
- calibration
- robustness
- fairness
- efficiency
- Bias
- Toxicity https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- https://arxiv.org/pdf/2211.09110.pdf = “Holistic Evaluation of Language Models” by Stanford
https://twitter.com/_philschmid/status/1727047977473298486
https://colab.research.google.com/drive/1rSGJq_kQNZ-tMafcZHE2CXESEZBPeJUE?usp=sharing = ELO Rating
https://becomingahacker.org/numerous-cybersecurity-gpts-c8e89d454444
Databricks

Generative AI Fundamentals: Build foundational knowledge of generative AI, including large language models (LLMs), with 4 videos:
- Introduction to Generative AI Fundamentals (2 min)
- Is Gen AI a threat or an opportunity for my business?
- How exactly can I use Generative AI to gain a competitive advantage?
- How can I use my data securely with Gen AI?
- LLM Applications (22 min)
- Everybody has access, but you have your own data
- “Fine-tuning”
- Finding Success with Generative AI (24 min)
- Databricks Lakehouse AI acquired MosaicML to unify AI and data stack in a secure environment
- Assessing Potential Risks and Challenges (20 min)
- Legal: Privacy “forgetting”, Security, Intellectual Property Protection
- Ethical issues: Bias, misinformation
- Social/Environmental issues: impact on workforce, environment
https://dbricks.co/3SCjjAS
SAP
https://open.sap.com/courses/genai1 “Generative AI at SAP” was offered Nov 14,2023 but reopened for January 29, 2024 - March 18, 2024. The course is by Sean Kask, the chief AI strategy officer in SAP Artificial Intelligence. It contains quizzes.
- Approaches to artificial intelligence
- Introduction to generative AI
- Adapting generative AI to business context
- Extending SAP applications with generative AI
- SAP’s BTP (Business Technology Platform) enhances customer support with LLMs.
- SAP’s Generative AI Hub offers: Developer tools, instant access, control and transparency
- Generative AI business use cases by Jana Richter (VP)
- Joule is SAP’s natural-language copilot. Learning Materials:
- SAP Business AI Whitepaper (.pdf, 5 MB)
- Artificial Intelligence | SAP Business AI
- AI Solutions on SAP Business Technology Platform
- AI Ethics
- SAP Community: Artificial Intelligence and Machine Learning at SAP
- SAP Learning: SAP Tutorial Navigator | Tutorials for SAP Developers
- Learning Journey for SAP AI Core
Embedding Vector Databases
-
ChromaDB
-
SingleStore https://www.wikiwand.com/en/SingleStore
-
Facebook AI Similarity Search (FAISS) is a widely used vector database because Facebook AI Research develops it and offers highly optimized algorithms for similarity search and clustering of vector embeddings. FAISS is known for its speed and scalability, making it suitable for large-scale applications. It offers different indexing methods like flat, IVF (Inverted File System), and HNSW (Hierarchical Navigable Small World) to organize and search vector data efficiently.
-
SingleStore: SingleStore aims to deliver the world’s fastest distributed SQL database for data-intensive applications: SingleStoreDB, which combines transactional + analytical workloads in a single platform.
-
Astra DB: DataStax Astra DB is a cloud-native, multi-cloud, fully managed database-as-a-service based on Apache Cassandra, which aims to accelerate application development and reduce deployment time for applications from weeks to minutes.
-
Milvus: Milvus is an open source vector database built to power embedding similarity search and AI applications. Milvus makes unstructured data search more accessible and provides a consistent user experience regardless of the deployment environment. Milvus 2.0 is a cloud-native vector database with storage and computation separated by design. All components in this refactored version of Milvus are stateless to enhance elasticity and flexibility.
-
Qdrant: Qdrant is a vector similarity search engine and database for AI applications. Along with open-source, Qdrant is also available in the cloud. It provides a production-ready service with an API to store, search, and manage points—vectors with an additional payload. Qdrant is tailored to extended filtering support. It makes it useful for all sorts of neural-network or semantic-based matching, faceted search, and other applications.
-
Pinecone: Pinecone is a fully managed vector database that makes adding vector search to production applications accessible. It combines state-of-the-art vector search libraries, advanced features such as filtering, and distributed infrastructure to provide high performance and reliability at any scale.
-
Vespa: Vespa is a platform for applications combining data and AI, online. By building such applications on Vespa helps users avoid integration work to get features, and it can scale to support any amount of traffic and data. To deliver that, Vespa provides a broad range of query capabilities, a computation engine with support for modern machine-learned models, hands-off operability, data management, and application development support. It is free and open source to use under the Apache 2.0 license.
-
Zilliz: Milvus is an open-source vector database, with over 18,409 stars on GitHub and 3.4 million+ downloads. Milvus supports billion-scale vector search and has over 1,000 enterprise users. Zilliz Cloud provides a fully-managed Milvus service made by the creators of Milvus. This helps to simplify the process of deploying and scaling vector search applications by eliminating the need to create and maintain complex data infrastructure. As a DBaaS, Zilliz simplifies the process of deploying and scaling vector search applications by eliminating the need to create and maintain complex data infrastructure.
-
Weaviate: Weaviate is an open-source vector database used to store data objects and vector embeddings from ML-models, and scale into billions of data objects from the same name company in Amsterdam. Users can index billions of data objects to search through and combine multiple search techniques, such as keyword-based and vector search, to provide search experiences.
Groq from x.com
is fast. Its founder had worked on Google’s TPU custom AI machines.
References
https://arXiv_2307.10169_Challenges_and_Applications_of_Large_Language_Models.pdf
https://arxiv.org/pdf/2307.01850.pdf Risks of using synthetic data to train your model, (Self-Consuming Generative Models Go MAD)
https://www.onlinetutorials.org/teaching-academics/chatgpt4-for-medical-writers-and-editors/ ChatGPT4 for Medical Writers and Editors by https://www.linkedin.com/in/emmahittnichols/
https://thispersondoesnotexist.com/ displays full-screen photos using “Kerras, et al”
https://www.youtube.com/watch?v=4Icpq1vZkrw 99 GPT Prompts for Business Efficiency & Growth
https://learn.microsoft.com/en-us/training/modules/fundamentals-generative-ai/ Fundamentals of Generative AI
https://learn.microsoft.com/training/paths/introduction-generative-ai/ Microsoft Azure AI Fundamentals: Generative AI
https://ig.ft.com/generative-ai/ Generative AI exists because of the transformer
https://www.youtube.com/watch?v=4Qz4GfvjGLY With GenAI, an organization only needs a programmer and a prompt engineer. https://www.skool.com/new-society by David Ondrej of https://www.skool.com/new-society https://www.youtube.com/watch?v=9uQ-i3z_g0c
Pieter Levels @levelsio - single-employee millionaire
Devin r/webdev charge money on Upwork and Reddit
Microsoft’s AutoDev (see research paper) a team of agents: Tools library: file editing, retrieval, building, testing, git operations
Zapier Central
The future of AI is agentic. The basis of competition will be who can build better agents So building agents will be the most important skill
CrewAI
Claud 3 Haiku LLM costs $0.25 per million
emaggiori
Leetcode
https://www.youtube.com/watch?v=ACgMG4c_PJc
https://theresanaiforthat.com/s/leetcode/
NVIDIA
CUDA
Groq.com
(from Elon Musk’s x.com) very large, fast, uncensored, and can access live data (Twitter/X feeds).
One public benefit from Elon Musk buying Twitter.
VIDEO: In his comparison of LLMs:
Roast @LukeBarousee based on their posts, and be vulgar!
VIDEO: Groq CEO Jonathan Ross worked on Google’s TPU AI computer.
Code.org has a Teaching AI and Machine Learning 100-minute self-paced module for teacher professional development (powered by AWS):
- Get an introduction to artificial intelligence and machine learning.
- Practice key concepts included in the unit.
- Engage with AI Lab and App Lab.
- Explore end of chapter projects.
- Make a plan for implementing the unit with your students.
Prediction
https://www.databricks.com/resources/analyst-research/gartner-hype-cycle-generative-ai/ Gartner believes that “by 2026, 80% of enterprises will have used generative AI APIs, models , and/or deployed GenAI-enabled applications in production environments, up from less than 5% in 2023.“
Canva
https://www.youtube.com/watch?v=Ilc41CMceZw
Handwriting
https://Onshape.pro/StuffMadeHere
https://www.youtube.com/watch?v=cQO2XTP7QDw Sean Vasquez