

It’s more relational than relational databases
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
- Graph databases: the latest thing
- Faster and Better?
- Where graph databases are needed
- Simpler complex connections, naturally
- More relational than relational databases?
- Which graph database and language?
- Gremlin language
- TigerGraph
- JanusGraph on GKE with Cloud Bigtable
- Microsoft Cosmos
- Jobs
- Resources
The contribution of this article is a maticulously sequenced presentation that curates concise yet deep insights from the many resources about this topic.
NOTE: Content here are my personal opinions, and not intended to represent any employer (past or present). “PROTIP:” here highlight information I haven’t seen elsewhere on the internet because it is hard-won, little-know but significant facts based on my personal research and experience.
Graph databases: the latest thing
Graph type databases is the latest in the evolution of data storage mechanisms to handle complexity.

PROTIP: People using graph databases call themselves “Graphistas”.
Below is a (probably controversial) table comparing the different types of stores and their strengths and weaknesses.
| Types: | Key-value | Column | Document | Relational | Graph |
|---|---|---|---|---|---|
| Complexity | none | low | low | moderate | high |
| Performance | high | high | high | high | variable |
| Scalability | high | high | high / variable | high | variable |
| Flexibility | high | moderate | high | high | high |
Google Cloud Spanner is a cloud-based relational database that’s a horizontally scalable, globally immediate consistent. Released in 2017.
References:
- Wikipedia: Graph_database
- https://itnext.io/getting-started-with-graph-databases-azure-cosmosdb-with-gremlin-api-and-python-80e57cbd1c5e
- https://www.c-sharpcorner.com/article/what-is-a-graph-database/
- VIDEO: Neo4j on GKE via GCP Marketplace at https://bit.ly/2u6ryt3
Faster and Better?
It is time consuming for traditional relational databases to process complex indexed queries (even if it’s all in cache). However, graph databases can process complex data structures efficiently because it uses pointers instead of table lookups (for “index free adjacency”). A comparison VIDEO:
| # persons | query time | |
|---|---|---|
| Relational database | 1,000 | 200 ms |
| Neo4j | 1,000 | 2 ms |
| "Supernodes" in Neo4j | 1,000,000 | 2 ms |
Where graph databases are needed
Graphs can provide insights not easily found using other technologies.
Graph databases provides an alternative way to to store data. Instead of static predefined schemas which require shutdown to change, graph databases can be configured dynamically while running.
Where graphs are important to visualizing AI/Machine Learning algorithms:
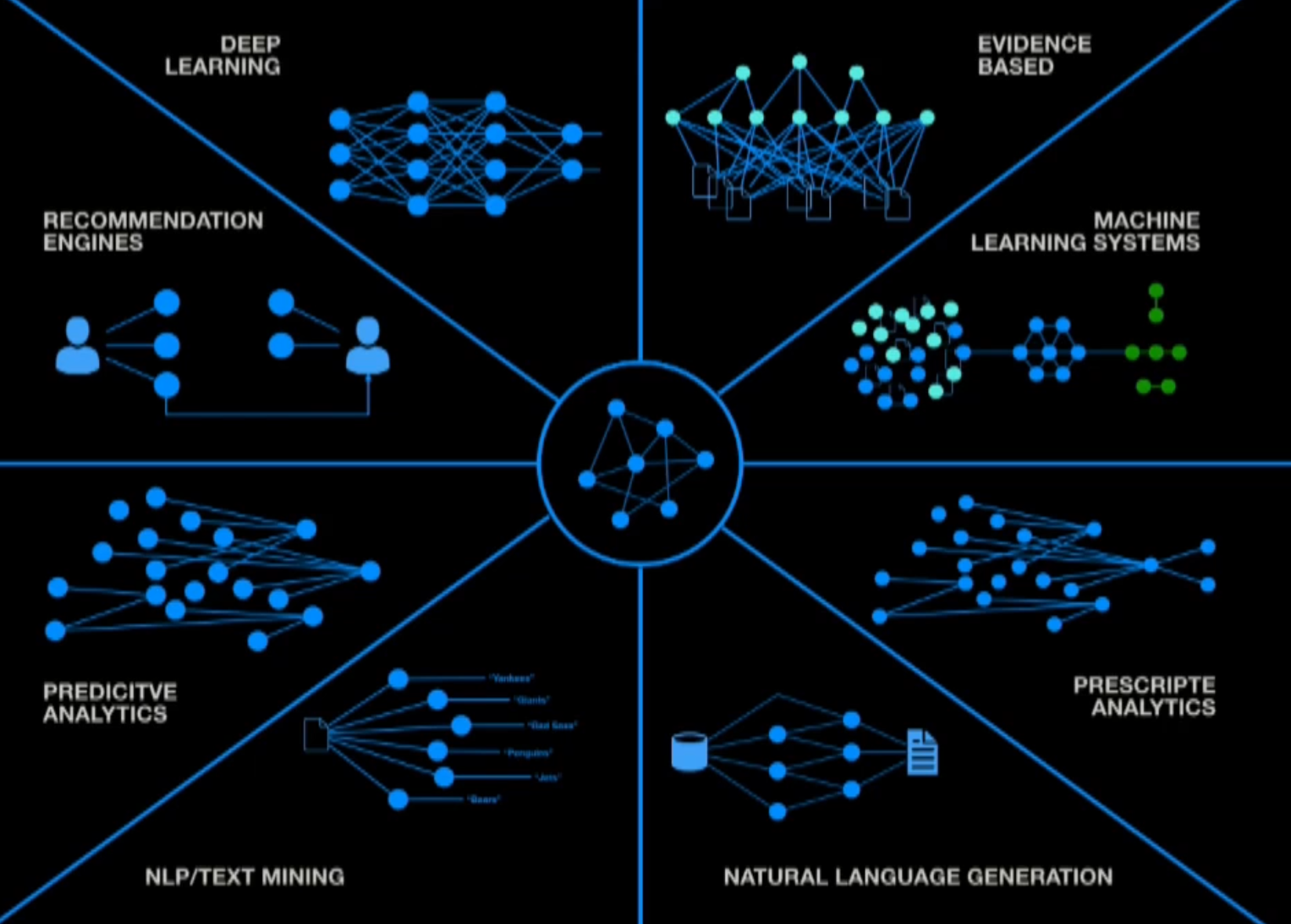
Directed acyclic (one-way) graphs (DAGs) are used in Git, scheduling algorithms, and form the heart of many neuro network (Tensor) models in many other modern applications. Its representation of dependencies (precedence relationships) enable its use in the Airflow task processing app.
- https://www.techtarget.com/searchcio/tip/Expect-graph-database-use-cases-for-the-enterprise-to-take-off
Simpler complex connections, naturally
It’s difficult for SQL to answer questions that were not already expected ahead of time.
SQL databases from Oracle, MySQL, etc. need to join physical tables together using foreign keys and link tables.*
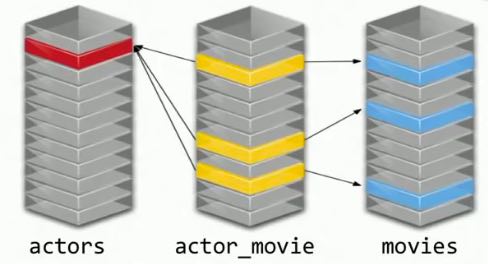
Writing SQL to represent a social graph containing 1,000 persons averaging 50 friends each can be difficult due to the need for joins and “de-normalized” physical structures.
More relational than relational databases?
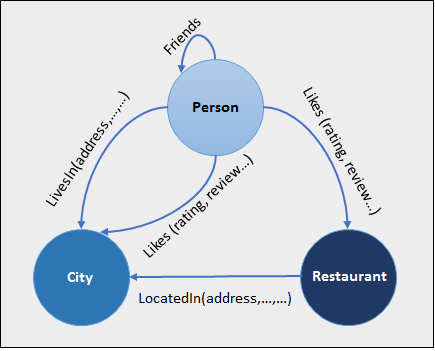
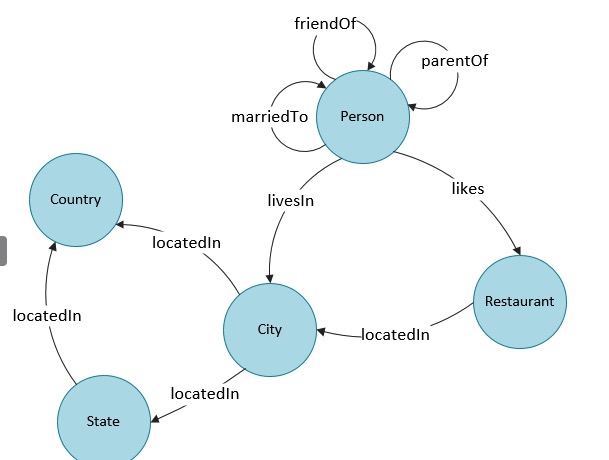
Whereas SQL data is stored in separate tables joined together using complex queries, Graph databases are “white-board friendly” because it stores data the same way as illustrated by its data model. Graph database diagrams look like ER (Entity-Relation) diagrams for SQL databases. The example below uses data from Movielens database containing 62,000 movies with 25 million ratings and one million tag applications applied by 162,000 users:

Graph databases manage nodes (data entities) in relationship to other nodes.
Instead of elaborate joins, labeled relationships between red nodes defining movie titles and green nodes defining actor names. Red and green differentiate entity types. Titles and actor names labels to nodes. “ACTED_IN” and “DIRECTED” are attributes of relationships.
Nodes objects are also called “vertices” and relationships are also called “edges”.
In Neural Network Computation Graphs:
vertices are neurons (simple building blocks) and edges are tensors (data items).
Each vertex has an ID (identifier).
Each edge has a weight. In a graph of edges representing segments of a road being built, the Shortest Path (Djisktra’s) algorithm reveals the least-cost set of road segments.
Adjacency Lists makes sense for large, sparsely connected graphs.
Adjacency Sets makes sense for small, densely connected graphs.
To order all nodes that satisfies all precedence relationships, a topological sort, implemented using a simple iterative algorithm.
Spanning Tree Algorithms find a path through all nodes. The minimum spanning tree is one that has the lowest sum of weights. Prim’s (greedy) algorithm works only for connected (weighted undirected) graphs. Krushal’s algorithm works even for disconnected graphs.
Traversing graphs indirectly
The advantage of graph databases appears when working with complex indirect relationships.
Relationships and nodes can be associated with name/value pair properties used to narrow searches.

Third-party add-ons can add a GUID to each entity.
Which graph database and language?
This ranking by db-engines.com lists Neo4j as the most popular graph database, with Microsoft Azure Cosmos catching up quickly.
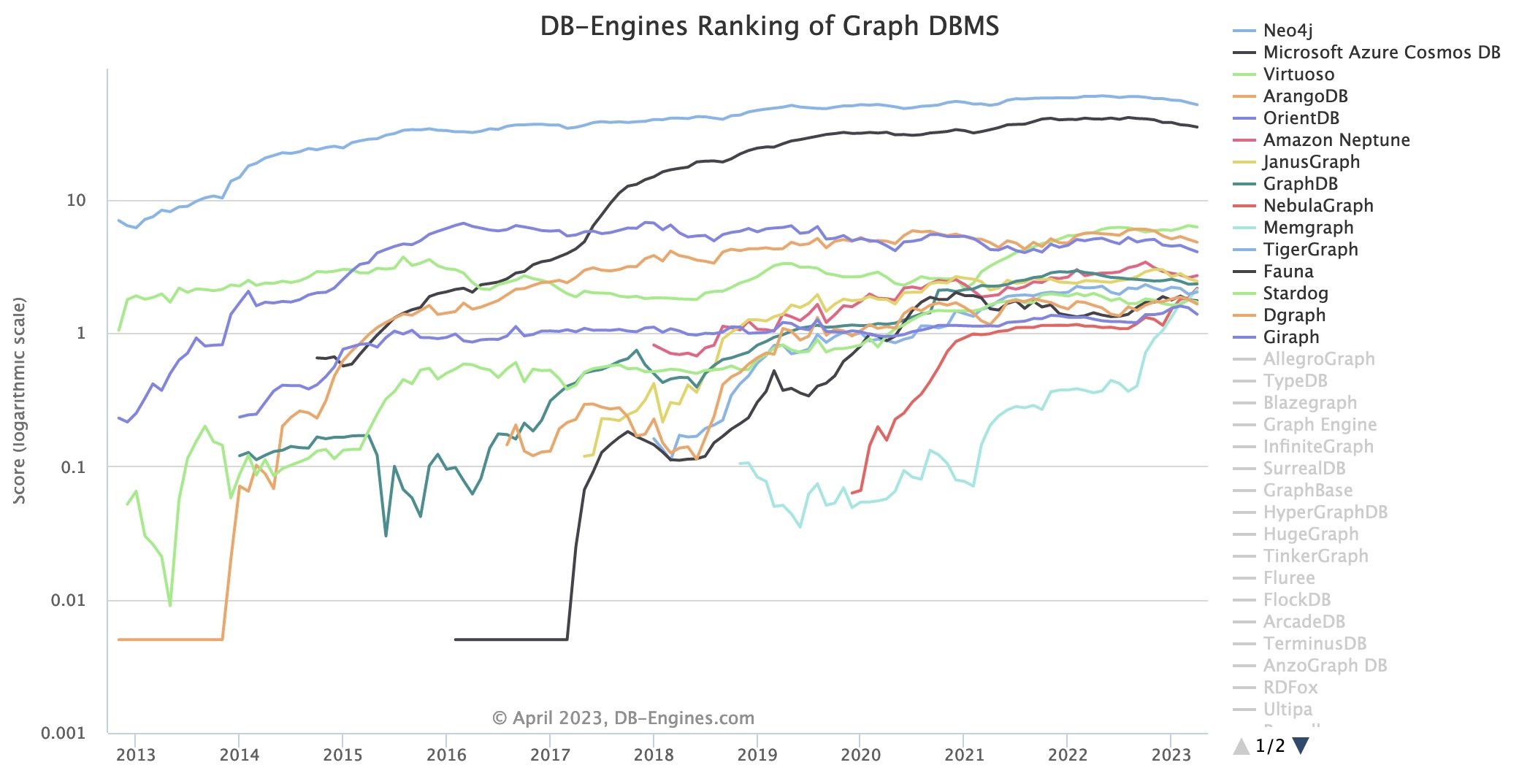
https://db-engines.com/en/system/GraphDB%3BMicrosoft+Azure+Cosmos+DB%3BNeo4j
Notice that Cosmos and others are called “Multi-model” (providing a Document store, Key-value store, wide-column store as well as graph database).
Gremlin language
The Gremlin language traversal machine (GTM) is to graph computing as what the Java virtual machine (JVM) is to general purpose computing. The Gremlin language is implemented by a wide variety of vendors, including Neo4j. Gremlin is popular largely because it is supported (beginning in 2009) by the open-source Apache Tinkerpop/TinkerGraph (docs
“It’s harder to get started with Gremlin than Neo4j’s Cypher. Gremlin has a SQL-like syntax (SELECT, WHERE, etc.). But Gremlin helps you understand graphs better than Cypher. And it’s available on free open-source software and most portable and available among vendors.” – John Ptacek [24:25] into “THAT Conference ‘19: Introduction to Graph Databases”
References:
- https://www.codeproject.com/Articles/1066378/Introduction-to-Graph-Databases-using-Neo-J-and-it
TigerGraph
TigerGraph analytics cloud calls itself “the most scalable graph database-as-a-service for your connected data analytics”. It is Apache-2 licensed. It’s purpose-built for loading terabytes of data in hours and, in real-time, analyzing 10+ hops deep in to relationships.
- https://www.tigergraph.com/google-cloud/
- https://docs.tigergraph.com/tigergraph-server/current/getting-started/cloud-images/gcp
JanusGraph on GKE with Cloud Bigtable
http://janusgraph.org was open-sourced in 2017 under The Linux Foundation, with participants from Google, Hortonworks, IBM, Amazon, GRAKN.AI, Expero Labs, etc. Named customers include Ebay and Target.
The Janusgraph distributed graph database has multiple scalable storage backends:
- Apache Cassandra®
- Apache HBase®
- Google Cloud Bigtable
- Oracle BerkeleyDB
https://db-engines.com/en/system/Google+Cloud+Datastore%3BGraphDB%3BNeo4j Google Cloud Datastore
JanusGraph uses a pluggable indexing backend to provide full-text indexing for vertex and edge properties.
Janusgraph runs within GKE with ElasticSearch as the indexing backend running in Pods in a StatefulSet.
Bigtable as the underlying backend storage layer.
For fast and deep graph traversals among relationships, JanusGraph stores data as an adjacency list.
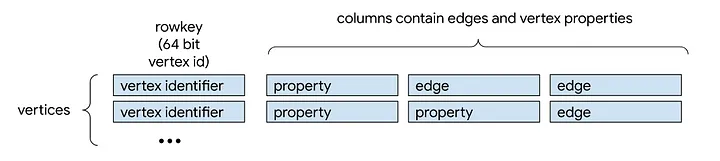
The above diagram[1] shows the logical storage structure for a small graph fragment with two vertex rows. Two example rows represent two vertices. The first vertex is labeled with a single vertex property and is related to two other vertices by two separate edges. The second vertex holds columns containing two properties and one edge.
Each row represents a vertex, any adjacent vertices (edges), and property metadata about the vertices and edges. A row key is the unique identifier for each vertex. Each relationship between the vertex and another vertex and any properties that further define the relationship are stored as an edge or edge-property column. Both the column qualifier and column value store data that defines the edge, in accordance with Bigtable best practices. Each vertex property is stored as a separate column, again using both the column qualifier and the column value to define the property.
RDF Triplestore
RDF stands for Resource Description Framework and is a standard for describing web resources and data interchange, developed and standardized with the World Wide Web Consortium (W3C). While there are many conventional tools for dealing with data and more specifically for dealing with the relationships between data, RDF is the easiest, most powerful and expressive standard design.
RDF enables effective data integration from multiple sources, detaching data from its schema. This allows multiple schemas to be applied, interlinked, queried as one and modified without changing the data instances.
RDF is a standard for data interchange used for representing highly interconnected data. Each RDF statement is a three-part structure consisting of resources where every resource is identified by a URI. Representing data in RDF allows information to be easily identified, disambiguated and interconnected by AI systems.
- https://www.ontotext.com/knowledgehub/fundamentals/what-is-rdf/
References:
- [1] https://connectsaurabhmishra.medium.com/how-google-cloud-deals-with-graph-databases-19790cd1d43e
- https://connectsaurabhmishra.medium.com/neo4j-aura-graph-database-extension-on-google-cloud-1b2c7f11fbd2
- https://cloud.google.com/architecture/running-janusgraph-with-bigtable
Neo4j Aura:
- https://console.cloud.google.com/marketplace/product/endpoints/prod.n4gcp.neo4j.io?project=glass-bridge-285601
- https://connectsaurabhmishra.medium.com/neo4j-aura-graph-database-extension-on-google-cloud-1b2c7f11fbd2
Cloud SaaS Graph database services
References:
- https://www.g2.com/categories/graph-databases
- https://www.g2.com/categories/graph-databases#grid
Instead of a local instance, if you’re working as a team of developers, consider always-on availability, on-demand scalability, and support:
-
Neo4j’s own Aura cloud offering runs on GCP.
-
GraphStory.com provides single-node Cloud Graph Neo4j databases from Azure, AWS, and GCP with their dashboard for $299/month (and up). $899/month and up with monitoring with HA multi-zone failover protection. GraphStory can stand up Enterprise Neo4j Causal Clusters on Google Cloud Platform. Also on the GCP Marketplace. INTRO VIDEO
- Microsoft’s Cosmos graph database processes Gremlin queries.
-
Neo4j VMs on MS Azure Marketplace in partnership VIDEO: Graph DataConnect
-
Apache TinkerPop Gremlin queries on DataStax Enterprise Graph
-
AWS Neptune (named the ice planet in our solar system) is Amazon’s graph database managed cloud service (documentation). Pluralsight video course by Jeff Hoopper covers use of (non-prod) CloudFormation to establish a cluster of $250/month db.r4.large (or larger) EC2 instances in several availability zones within a region. IAM is used, but is accessible only via a VPC from a Lambda service. The read-only Reader can access Up to 16 read replicas behind separate IP addresses. The modules used in the course are release 2018.3:
- apache-tinkerpop-gremlin-console-3.3.2 for Gremlin queries
- eclipse-rd4jf-2.3.2 for SPARQL queries Triplestore
AWS Neptune can (from S3) use curl to POST bulk-load graph UTF-8 data in several formats:
- CSV
- N-Tuples
- N-Quads
- RDF/XML
- Turtle to load SPARQL
-
AnzoGraph DB from Cambridge Semantics - a Massively Parallel Processing (MPP) native graph database built for data harmonization and analytics. Horizontally scalable graph database built for online analytics and data harmonization. Take on data harmonization and linked data challenges. It uses SPARQL*/OWL for semantic graphs but also supports Labeled Property Graphs (LPGs). VIDEO
- ArangoDB earned high performance scores from Gartner. Natively store data for graph, document and search needs. Utilize feature-rich access with one query language. Map data natively to the database and access it with the best patterns for the job – traversals, joins, search, ranking, geospatial, aggregations – you name it. Polyglot persistence without the costs. Easily design, scale and adapt your architectures to changing needs and with much less effort. Combine the flexibility of JSON with semantic search and graph technology for next generation feature extraction even for large datasets.
Microsoft Cosmos
Microsoft’s Cosmos graph database running within a Azure HDInsight Spark cluster 2.0. VIDEO, slides
- https://learn.microsoft.com/en-us/azure/cosmos-db/gremlin/introduction
- https://learn.microsoft.com/en-us/azure/cosmos-db/gremlin/support
- https://learn.microsoft.com/en-us/azure/cosmos-db/gremlin/modeling
-
https://learn.microsoft.com/en-us/azure/cosmos-db/gremlin/partitioning
- https://www.tomsawyer.com/graph-database-browser/azure
- https://towardsdatascience.com/getting-started-with-graph-databases-in-azure-cosmos-db-cbfbf708cda5
Microsoft Graph 365
Microsoft “Graph” product stores user metadata from its 365 product (documents, emails, etc).
It has an API.
- https://azure.microsoft.com/en-us/products/graph-data-connect
- https://github.com/microsoftgraph/dataconnect-solutions
- https://blog.pragmaticworks.com/what-is-microsoft-graph
- https://www.infoworld.com/article/3231658/making-sense-of-microsofts-graph-database-strategy.html
- https://blog.victoriaholt.co.uk/2018/06/microsoft-graph-useful-tool.html
- https://laurakokkarinen.com/the-ultimate-beginners-guide-to-microsoft-graph/
- https://blog.ciaops.com/2019/04/17/using-interactive-powershell-to-access-the-microsoft-graph/
- https://www.red-gate.com/simple-talk/development/dotnet-development/getting-started-with-microsoft-graph-api/
- https://www.epcgroup.net/microsoft-graph-data-connect-pricing-and-features-guide/
- https://blog.codewithdan.com/getting-started-calling-the-microsoft-graph-api/
Microsoft SQL Server
SQL Server offers graph database capabilities to model many-to-many relationships. The graph relationships are integrated into Transact-SQL and receive the benefits of using SQL Server as the foundational database management system.
Transact-SQL Graph extensions are fully integrated in Microsoft’s SQL Server engine. Use the same storage engine, metadata, query processor, etc. to store and query graph data. Query across graph and relational data in a single query. Combining graph capabilities with other SQL Server technologies like columnstore, HA, R services, etc. SQL graph database also supports all the security and compliance features available with SQL Server.
All graph operations supported on relational tables are supported on node or edge table. A node table is collection of similar type of nodes.
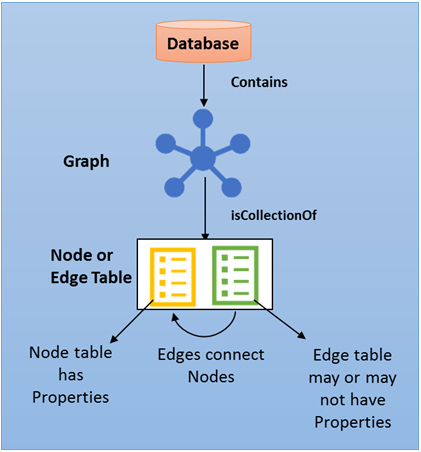
Transact-SQL Graph extensions allow users to create node or edge tables. Here is an example:
CREATE TABLE Person (ID INTEGER PRIMARY KEY, Name VARCHAR(100), Age INT) AS NODE; CREATE TABLE friends (StartDate date) AS EDGE;
A graph is a collection of node and edge tables.
One graph per database.
Node or edge tables can be created under any schema in the database, but they all belong to one logical graph.
A more complex diagram using Visio and PowerBI:
MATCH clause
The new MATCH clause supports pattern matching and multi-hop navigation through the graph. It uses ASCII-art style syntax for pattern matching:
-- Find friends of John SELECT Person2.Name FROM Person Person1, Friends, Person Person2 WHERE MATCH(Person1-(Friends)->Person2) AND Person1.Name = 'John';
The Person node table holds all the Person nodes belonging to a graph. An edge table is a collection of similar type of edges. A Friends edge table holds all the edges that connect a Person to another Person.
Since nodes and edges are stored in tables, most of the operations supported on regular tables are supported on node or edge tables.
Both nodes and edges can have properties associated to them.
Sample code
https://www.sqlshack.com/introduction-sql-server-2017-graph-database/
QUESTION: Sample template code for a web app built using C# .NET referencing graph SQL?
- https://guyinacube.com/2020/10/08/visualize-graph-data-in-power-bi/
SHORTEST_PATH
The SHORTEST_PATH function finds the shortest path between any 2 nodes in a graph or starting from a given node to all the other nodes in the graph. It can also be used to find a transitive closure or for arbitrary length traversals in the graph.
Edge constraints
To enforce data integrity and specific semantics on the edge tables in SQL Server graph database, use edge constraints to edge tables</a> so that when a new edge is added, the Database Engine enforces that the nodes which the edge is trying to connect, exist in the proper node tables. It is also ensured that a node cannot be dropped, if it is still referenced by an edge. Example:
CONSTRAINT EC_BOUGHT CONNECTION (Customer TO Product, Customer TO Product)
- EC_BOUGHT is the constraint_name.
-
Within parenteses are clauses that define the edge constraint.
- https://bvisual.net/2018/02/09/using-visio-and-powerbi-with-graphdatabase-in-sqlserver/
Jobs
https://www.linkedin.com/jobs/microsoft-graph-science-jobs/
Resources
-
“Working with Graph Algorithms in Python” video tutorial on Pluralsight by Janani Ravi explains sample Python 3.5.1 code (not using Neo4J or Gremlin).
-
QUESTION: Sample code for a web app using Neo4j and Python? Stack Overflow
-
VIDEO Neo4j CTO Jim Webber