

Distribute load to scale and upgrade servers with no down time. Also route transactions across clouds using ZeroLB
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
The contribution of this article is a deep yet succinct hands-on step-by-step tutorial which is logically sequenced, with “PROTIP” marking hard-won, little-know but significant facts available no where else on the internet.
NOTE: Content here are my personal opinions, and not intended to represent any employer (past or present). “PROTIP:” here highlight information I haven’t seen elsewhere on the internet because it is hard-won, little-know but significant facts based on my personal research and experience.
- Why Load Balance?
- The Trouble with Load Balancing
- Load Balancing in Azure
- Load Balancing in AWS
- Routng
- Mechanisms
- Network LB
- More Resources
Why - Who Needs Load Balancing?
Server load balancing scales “horizontally” to accomodate higher volume work by distributing (balancing) client requests among several servers. This allows more servers (hosts) to be added to handle additional load.
Even if a single server can handle current load, it is still a good idea to design and test your system to use a load balancer to distribute load so that the cluster stays up.
Having your applications on more than one machine allows operations personnel to work on one machine while the other is busy working.
Having “fault resilience” means that an alternative server can take over when, inevitably, a server crashes or just needs maintenance work done.
This is called ensuring uninterrupted continuous avialability of mission-critical applications.
It’s also a good idea to test your system for its ability to handle growth when it’s still fresh on developer’s minds, since load balancing and fail-over issues can be quite complex.
The oldest load balancers operated at network level 4 (L4), which route based on IP address.
Newer “application” load balancers, operating at network level 5 (L7), allocate traffic based on the URL, such as routing to web vs. API servers.
Algorithms
The Trouble with Load Balancing
-
Use of a load balancer takes an extra hop in the network, which adds latency.
PROTIP: Measure the extra time load balancers take by measuring with and without load balancing. Monitor in real-time the load on each individual resource in a pool.
-
Load balancers may not evenly distribute load among active machines in the cluster. This can happen for several reasons:
-
Since each session poses different levels of load, load balacers which allocate based on frequency of allocation (such as round-robin algorithm) may over-allocate sessions to a server which ended up with users and sessions who consume a higher-than-average amount of resources.
PROTIP: While running synthetic transactions, experiment with different algorithms for allocation/splitting of traffic:
- round robin across nodes
- least request
- random
- ring hash
- maglev
-
Session stickiness. Once the IP of a client gets assigned to a particular server (at Login), it stays with that server until the session ends. This means that fake IP addresses need to be allocated for testing. Session stickiness is inherently fragile because the backend hosting the session may die.
Global Load Balancing in Service Mesh
Kong Mesh claims a reduction in “network latency by 2x on request lifecycles and 4x on full roundtrips” plus “zone aware load balancing to reduce egress costs” across multi-cloud Kubernetes clusters, VMs, and bare metal.
Such progress can be made with new “decentralized” applications using the Service Mesh> architecture pattern working within Kubernetes, which deploys (bootstraps) intelligent proxies as “sidecars” running in each pod alongside each app container.
Decentralized microservices apps Dockerized for running in containers make all network communication through its sidecar proxy (like handing a box to UPS to deliver).
BLOG:

Each sidecar proxy can communicate with backends in different zones (generically named A, B, and C in the diagram). Policies sent to each sidecar can specify zones and a different amount of traffic be sent to each zone. Each zone can be in different clouds (thus multi-cloud).
This approach also enables security-related policies to be applied (such as limiting outflows from some countries) and detection of zonal failure and automatic rerouting around traffic anomalies (including DDoS attacks).
Each sidecar proxy and backend service report periodic state to the global load balancer (GLB) so it can make decisions that take into account latency, cost, load, current failures, etc. This enables centralized visualizations engineers use to understand and operate the entire distributed system in context.
This means app developers no longer need to bother coding for a long list of operational cross-cutting concerns:
-
collection and reporting of telemetry (health checks, logs, metrics, traces)
- TLS termination (SSH key handling)
-
Handle protocols HTTP/2, WebSocket, gRPC, Redis, as well as TCP traffic
- rate limiting (DoS mitigation)
- timeout and back-out handling when response is not received
-
Circuit breakers
- Fault injection (for chaos engineering to improve reliability)
-
Enforce policy decisions
- load balancing
- Staged rollouts with percentage-based traffic splits
Embedding the above functionality in each app program may provide the best performance and scalability, but requires polyglot coding to implement the library in many languages. It can also be cumbersome to coordinate upgrades of new versions of each library across all services.
There are several sidecar programs:
Logically, communication of packets/requests travel through a “data plane”.
There is also a “control plane” which, rather than exchanging packets/requests, traffic in policies and configuration settings to enable services such as:
- deploy control (blue/green and/or traffic shifting),
- authentication and authorization settings,
- route table specification (e.g., when service A requests /foo what happens), and
- load balancer settings (e.g., timeouts, retries, circuit breakers, etc.).
Several products provide a “control plane UI” (web portal/CLI) to set global system configuration settings and policies as well as
- Dynamic service discovery
- certificate management (acts as a Certificate Authority (CA) and generates certificates to allow secure mTLS communication in the data plane).
- automatic self-healing and zone failover (to maximize uptime)
Several control plane vendors compete on features, configurability, extensibility, and usability:
-
IstioD
-
open-sourced Nelson uses Envoy as its proxy and builds a robust service mesh control plane around the HashiCorp stack (i.e. Nomad, etc.).
-
Kong Mesh (part of the Konnect Connectivity Platform) makes use of Envoy
-
SmartStack creates a control plane using HAProxy or NGINX.
References:
- https://www.prnewswire.com/news-releases/kong-introduces-zerolb-a-new-load-balancing-pattern-using-service-mesh-301352046.html
- https://thenewstack.io/zerolb-a-new-decentralized-pattern-for-load-balancing/
Load Balancing in Azure
If an availability zone goes down within the Azure cloud, Microsoft takes care of switchover transparently to users.
Load Balancing in AWS
Amazon requires that each user sets up their own Load Balancer for distributing traffic to running nodes in several AZs in case an one availability zone goes down.
To distribute traffic among several regions, setup a DNS (using Amazon Route 53). Public Load Balancers need a public DNS entry (Route53).
Load Balancing is covered in the $300 AWS Certified Advanced Networking - Speciality certification exam (65 questions in 175 minutes). Video courses:
- Pluralsight: ALB
- Pluralsight: Implementing AWS Load Balancing by Mike Pfeiffer 1 hour
- VIDEO: https://aws.amazon.com/elasticloadbalancing
Internal load balancers use only private IPs within AWS.
Elastic Load Balancing (ELB) is a DNS “A” record pointing at 1+ nodes in each AZ elaticized by a ASG (Application Scaling Group).
ELB consists of four types of load balancers that all feature the high availability, automatic scaling, and robust security necessary to make your applications fault tolerant.
AWS has these types of Load Balancers:
- Version 1 introduced 2009 is the Classic Load Balancer. One SSL cert per server.
- Version 2 are faster and support target groups and rules
- NLB Network LB handles TCP, TLS, UDP
- ALB Application LB handles HTTP/WebSocket async traffic
REMEMBER:
| ECS LB Type: | Classic LB | App LB | Network LB | Gateway |
|---|---|---|---|---|
| Layer: | 4 & 7 | Layer 7 | Layer 4 | 4 & 7 |
| Protocols: | HTTP/S TCP | HTTP/S/2 | TCP TLS UDP | HTTP/S |
| $ Per GB: | $0.025 | $0.0225 | $0.0225 | $0.0125 |
| $/Capacity Unit hour: | $0.008 /LCU | $0.008 /ALCU | $0.006 /NLCU | $0.004 /GLCU |
| Web Sockets: | - | Yes | - | - |
| Static EIP: | - | - | Yes | - |
| X-Forward headers: | Yes | Yes | - | - |
| Proxy TCP: | Yes | - | Yes | - |
| VPC IPv6: | - | Yes | Yes | - |
| AWS Privatelink: | - | - | Yes | - |
| Security Groups: | Yes | Yes | - | - |
| Containers: | - | Yes | Yes | - |
-
The Classic Load Balancer provides basic load balancing across multiple Amazon EC2 instances and operates at both the request level and the connection level. Classic Load Balancer is intended for applications that were built within a EC2-Classic network.
Each port handled by a Classic Load Balancer needs a separate load balancer setup:

To create a classic load balancer within Kubernetes, define this service.yaml:
--- apiVersion: v1 kind: Service metadata: name: some-web labels: app: some-app role: web spec: ports: - port: 80 protocol: TCP targetPort: 80 selector: app: some-app role: web type: LoadBalancerCharges are in Load Balancer Capacity Units (LCU) used per hour plus $0.008 per GB of data processed (the only type to charge by network), more expensive to encourage users to get off this legacy offering.
-
 NLB (Network Load Balancers) distributes Transmission Control Protocol (TCP), User Datagram Protocol (UDP), and Transport Layer Security (TLS) traffic where extreme performance is required. Network Load Balancer routes traffic to targets within Amazon VPC and is capable of handling millions of requests per second while maintaining ultra-low latencies.
NLB (Network Load Balancers) distributes Transmission Control Protocol (TCP), User Datagram Protocol (UDP), and Transport Layer Security (TLS) traffic where extreme performance is required. Network Load Balancer routes traffic to targets within Amazon VPC and is capable of handling millions of requests per second while maintaining ultra-low latencies.Charges are in Network Load Balancer Capacity Units (NLCU) per hour.
NLB is defined within service.yaml by annotations metadata:
--- apiVersion: v1 kind: Service metadata: name: some-web labels: app: some-app role: web annotations: service.beta.kubernetes.io/aws-load-balancer-type: external service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing spec: ports: - port: 80 protocol: TCP targetPort: 80 selector: app: some-app role: web type: LoadBalancer -
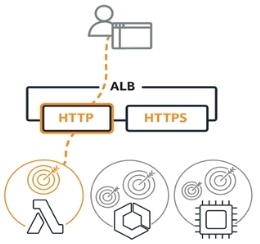 ALB (Application Load Balancer) distributes HTTP and HTTPS traffic and provides advanced request routing targeted at microservices and containers. Application Load Balancer routes traffic to targets within Amazon VPC based on the content of the request.
ALB (Application Load Balancer) distributes HTTP and HTTPS traffic and provides advanced request routing targeted at microservices and containers. Application Load Balancer routes traffic to targets within Amazon VPC based on the content of the request.Only ALB handles:
- HTTP host header
- HTTP method
- Source IP address or CIDR
- Arbitrary HTTP header
- HTTP query string parameter
- Combined rules
- AWS WAF
- Weighted Target Group routing for A/B testing, migrations, gradual Blue/Green deployments
Charges are in Application Load Balancer Capacity Units (ALCU) used per hour.
-
Both NLB and ALB require installation of an AWS Load Balancer Controller as a Kubernetes plug-in. See https://docs.aws.amazon.com/eks/latest/userguide/aws-load-balancer-controller.html
The ingress.yaml:
--- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: some-web annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip spec: rules: - http: paths: - path: / pathType: Prefix backend: service: name: some-web port: number: 80 ...
-
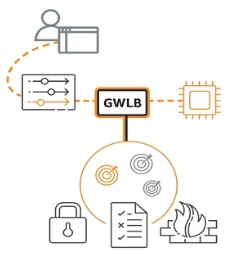 Gateway Load Balancer makes it easier to deploy, scale, and run fleets of third-party virtual networking appliances (such as F5) for security, network analytics, etc. Gateway Load Balancer uses Gateway Load Balancer Endpoint (GWLBE), a new type of VPC Endpoint powered by AWS PrivateLink technology that simplifies how applications can securely exchange traffic with GWLB across VPC boundaries. GWLBE is priced and billed separately.
Gateway Load Balancer makes it easier to deploy, scale, and run fleets of third-party virtual networking appliances (such as F5) for security, network analytics, etc. Gateway Load Balancer uses Gateway Load Balancer Endpoint (GWLBE), a new type of VPC Endpoint powered by AWS PrivateLink technology that simplifies how applications can securely exchange traffic with GWLB across VPC boundaries. GWLBE is priced and billed separately.Gateway Load Balancers are transparent to the source and destination of traffic.
REMEMBER: A /27 subnet allows scaling to 8 free IPs for use by up to 8 nodes in that subnet. (28 is enough actually)
Charges are in Gateway Load Balancer Capacity Units (GLCU) per hour.

AWS Networking
AWS WAF up front for DDoS protection.
Define separate subnets. Scheme: internet-facing
Scheme: internal: In Security group of targets in a private subnet, only allow inbound traffic only from the load balancer (in a specific security group ID).

https://docs.aws.amazon.com/autoscaling/ec2/userguide/autoscaling-load-balancer.html
https://docs.aws.amazon.com/eks/latest/userguide/calico.html
AWS Distribution Rules
VIDEO: One rule for each app group, defined by up to 100 rules:

To avoid impacting app servers used by humans, route automated spiders to app servers not used by humans.

VIDEO: ALB Ingress Controller for Kubernetes routes requests to different services in the cluster based on host, path, or other advanced request routing feature.
There is a 1 MB limit on Lambda request and response bodies. Lambda functions and ALB must be in the same AWS account.
Billing metrics
Workload Metric: ConsumedLCU is based on the highest among metrics during each given hour:
- RequestCount (new requests per second)
- Active connections
- ProcessedBytes (payload GB per second) bandwidth
Connections:
Target metrics: connection errors and Request time (latency)
AWS Health checks
External (Route 53) checks health of each ELB IP from the world. Failing IP health checks are removed from DNS.
Target health checks before sending requests.
AWS Config
Name each LB running (as EC2 instances) with prefix “LB-“:

No SSH and Security Key Pair (idempotent).
In Advanced, specify an Apache shell script to run on start to create a folder for what it processes, then show a message:
#!/bin/bash yum install httpd -y systemctl enable httpd mkdir /var/www/html/orders echo "<h1>Orders LB here</h1>" > /var/www/html/orders/index.html systemctl start httpd
PROTIP: For “Zero Trust” strategy, do not have LB handle HTTPS termination internally - use HTTPS throughout. Redirect HTTP to HTTPS.

AWS “Elastic Load Balancing” distributes incoming application traffic across multiple registered targets such as Amazon EC2 instances, containers, IP addresses, Lambda functions, and virtual appliances.

LBs can handle application traffic in a single or multiple Availability Zones.
SNI (Server Name Indication) can send different certs to different clients, with automatic cert renewals by ACM (Amazon Cert. Manager).
Apps need to add back-off on failure (up to a point of abandonment).
Algorithms for routing
Classic LBs route HTTP/S based on “Least outstanding requests” and TCP/TLS(SSL) using “round robin” algorithms.
NLBs routes based on “flow hashing”.
There are several basic types of load balancing:
Round robin DNS (RRDNS) involves client DNS servers to resolve a URL to multiple ip addresses (and thus multiple machines).
The problem with “round robin” is that it blindly hits each server regardless of its ability to accept work. This scheme requires every server to be homogeneous (nearly identical).
RRDNS is not recommended because it places load balancing outside the organization to authoritative DNS servers which caches DNS A entries. Changes to those entries can take a long time to propagate throughout the internet.
Network-based load balancers offer more sophisticated allocation algorithms. Network Load Balancing operates at the NIC driver level to detect the failure of a server and reassigns client computer traffic among the remaining servers.
Microsoft’s NLB service can take up to eight seconds to redirect load. How To Set Up TCP/IP for Network Load Balancing in Windows Server 2003 notes that
TCP/IP must be the only network protocol present on the cluster adapter. You must not add any other protocols (for example, Internetwork Packet Exchange [IPX]) to this adapter.
Because traffic enters the network, network load balancing cannot withstand moderate Dos (Denial of Service) attacks as well as large-capacity front-end network appliances which detect ad filter out malicious traffic before it gets to the server.
Dispatcher or proxy / switch based load balancers resolves requests from clients directed to a single virtual IP address (VIP) . The load balancer then uses a load balancing algorithm to distribute work to real IP addresses.
Such “server-based” load balancing is done either by an application running on a regular server or an appliance.
-
* Using regular PC machines (on standard operating systems such as Windows or UNIX)
has the advantage that it can be replaced (after configuration) with another machine
that is familiar to the staff.
There is less hassle from dealing with another vendor.
However, an individual central dispatcher can become a single point of failure. So:
A hot spare is a machine that’s configured as a mirror image of the machine it replaces if that fails. It’s also called a passive node if it sits unused until it’s need to support a failover.
Both the active and standby load balancers occassionally send out heartbeat messages such as VRRP (Virtual Router Redundancy Protocol, RFC 2338) format UDP packets to multicast IP 225.0.0.2 port 1985. (in the range from 224.0.0.0 to 239.255.255.255).
Cisco has its HSRP (Hot Standby Routing Protocol) and Extreme Networks has its ESRP (Extreme Standby Router Protocol).
This communication can occur over a serial cable between two machines.
Multicast can span several subnets, but they must reach their final destination after a network latency of no more than 200 to 300 milliseconds.
The passive node takes over (assumes “master” status) when it does not hear the “I’m alive” heartbeat from the other machine.
Because failover can cause a VIP to be the destination address at different devices at different times, a VIP can be called “floating”.
Failback occurs when the failed server comes back online and takes load back from the failover node. This happens after a transfer of client state information.
To avoid “bridging loops” when each load balancer thinks the other is inactive, the ISO Level 2 Spanning-Tree Protocol (STP) is used to set a cost for each port. This provides a way to block multiple paths by opening only the lowest-cost port (the highest-priority port). However, “STP is almost never used since it can take 10 seconds or more to react. Typically, a proprietary variation of a hot-standby protocol is used.”[2,p59]
CAUTION: Proxies forward both client requests to servers and server responses to clients, so unless they can handle as much throughput as all the machines in its subnet, it can easily become a throughput bottleneck.
Note: Although not necessary for production work, “Individual Pass-Though VIPs” are requested/defined so that for performance measurement and troubleshooting, individual servers can be reached through the load balancer.
Mechanisms
There are several distinguishing features among load balancers:
“Flat-based” IP typology means the VIP and real IPs are on the same subnet (usually behind a firewall). FTP and streaming applications use this typology along with Return Path DSR.
Many load balancers also have firewall capabilities (packet filtering, stateful inspection, intrusion detection, etc.)
More advanced load balancers enable the VIP to be on a different (more private/secure) subnet than IPs on servers receiving traffic. In this case, the load balancer acts as a gateway between the two LANs.
This is achieved with NAT (Network Address Translation). (RFC 1631) which enables real servers to hide themselves as non-routed RFC 1918 addresses.
But this only allows one pair of load balancer machines.
Load allocation algorithms within daemons (or windows services), which dynamically:
1) listens for a “heartbeat”; or
2) periodically sends ICMP ECHO_REQUEST to measure RTT (Round Trip Time) “pings”; or
3) detect the status of bandwidth usage or CPU utilization on each server; or
4) counts the number of connections active on each server.
</ul>
BEA Loogic 8.1 is server affinity that reduces the number of RMI sockets.
SAP R/3’s login balancing (SMLG) clustering technology makes the decision of which server receives a user for login based on the number of users currently logged in and response time, (not how many work processes are used at any moment).
Once a SAP user is logged on a particular app server, the user session is pinned to that server. Background jobs are also assigned to a server, but a new job might get assigned to another server.
failover automatic repartioning of client traffic among the remaining servers in the cluster so that users experience continuous performance Quality of Service (QoS).
Within the BEA WebLogic 8.1 HttpClusterServlet Plug-in, sessions are attached to a particular server by the client’s IP address. This means that a server must stay up until all sessions finish (which can take many minutes).
A failover mechanism must have an awareness of the progress of all activities so that client sessions can continue to complete if processing stops.
IP Multicasts are sent by each WebLogic server to broadcast their status. Each Weblogic server listens for the one-to-many messages to update its own JNDI tree.
Cisco’s LoadDirector uses a “Cookie Sticky” feature that redirects traffic to the same physical machine by examining cookies.
“Virtualization” software (such as EMC VMware) automatically installs application software to meet demand.
- Global load balancing that routes requests among several data centers over the WAN (Wide Area Network). “With cross-country latency at around 60 ms or more” [2,p10]
- Intelligent response to denial of service flooding attacks.
Direct Server Return of traffic back to clients
The least sophisticated load balancers use “Route-path”, where the load balancer acts as a Layer 3 router. But this allows 3 or more load balancers.
More sophisticated load balancers use “Bridge-path”, where the load balancer acts as a Layer 2 bridge between two LANs. However, this only works with flat-based nets.
Most sophisticated of all are when real servers (especially streaming and FTP servers) can bypass going back to the Load Balancer and send responses directly to clients by using Direct Server Return (DSR). This is desirable because “web traffic has a ratio of about 1:8, which is one packet out for every eight packets in.”[2,p26]
F5 calls this “nPath”. Foundry calls it “SwitchBack”.
DSR works by configuring the IP alias on the server’s loopback interface “lo” with the IP address of the VIP. This is done using the ifconfig command on Unix.
The server needs to still bind to the real IP address as well so the load balancer can perform health checks on the sever.
The default route path of the server needs to point to the router rather than the load balancer.
MAC Address Translation (MAT) ???
Load Balancing in the Cloud
The internal processes (life-cycle) of a "redundant, self-curing, and self-scaling" computing facility are
- Authorizing those who need to perform various activities with rights for their role (who can do what when)
- Imaging os and software apps into server snapshot images templates used to create working instances
- Provisioning (condensing) instances (with unique URLS and OS level settings)
- Configuring each instance (with unique application-level settings) [Puppet]
- Persisting data in and out each instance (with our without encryption)
- Storing logs eminating from instances into a centralized location
- Monitoring health and other metrics by instance type
- Deciding when alerts are appropriate, when an instance should be registered or un-registered with its load balancer, when instances should be added or removed
- Switching among instances from a static IP address [Sclar]
- De-Provisioning (evaporating) instances
- Analyzing logs for trends (cost per transaction over time) and implications to adjust number and size of instances most appropriate for each instance type/purpose and time frames) [capacity management like vkernel]
</ol>
Sclar (a $50/month open-source offering from
Intridea, a Washington DC Ruby on Rails development firm) illustrates its approach for a polling controller this way:
## MS NLB Services
After Microsoft acquired, in 1998, from Valence Research the "Convoy Cluster"
component of Windows NT 4.0 Enterprise Edition,
Microsoft introduced its Network Load Balancing (NLB) service
as a free add-on service to Advanced and Datacenter versions of Windows 2000 Server
(known as Enterprise Edition of Windows 2003).
The acronymn for Windows Load Balancing Service (WLBS) is also the name
of the utility which verifies whether load balanced hosts "converge":
-
wlbs query
wlbs stop
wlbs start
 $35 Windows 2000 & Windows Server 2003 Clustering & Load Balancing
(McGraw-Hill Osborne: April 9, 2003)
by Robert J. Shimonski
NLB capabilities come built-in with high-end Windows servers.
Use either the NIC properties page or the
"Administrative Tools\Network Load Balanacing Manager" tool.
A. After right-clicking "My Network Places", select "Properties".
1. In the "Networking Connections" dialog:
1.Rename "Local Area Connection" to your name for the
private interface for NLB heartbeat messages.
1. Rename "Local Area Connection2" to your name for the
public interface.
Select the "Network Load Balancing" check box.
In the "Network Load Balancing Properties" dialog box,
click the "Cluster Parameters" tab.
Enter the public IP address in the Cluster IP configuration area.
(This should be the same for all nodes in the cluster.)
Enter the Fully Qualified Domain Name (FQDN)
and network address handling incoming client requests.
To verify whether the hosts "converge":
$35 Windows 2000 & Windows Server 2003 Clustering & Load Balancing
(McGraw-Hill Osborne: April 9, 2003)
by Robert J. Shimonski
NLB capabilities come built-in with high-end Windows servers.
Use either the NIC properties page or the
"Administrative Tools\Network Load Balanacing Manager" tool.
A. After right-clicking "My Network Places", select "Properties".
1. In the "Networking Connections" dialog:
1.Rename "Local Area Connection" to your name for the
private interface for NLB heartbeat messages.
1. Rename "Local Area Connection2" to your name for the
public interface.
Select the "Network Load Balancing" check box.
In the "Network Load Balancing Properties" dialog box,
click the "Cluster Parameters" tab.
Enter the public IP address in the Cluster IP configuration area.
(This should be the same for all nodes in the cluster.)
Enter the Fully Qualified Domain Name (FQDN)
and network address handling incoming client requests.
To verify whether the hosts "converge":
-
wlbs query
- wlbs stop
- wlbs start