
Toward Observability
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
“The database is a cache of the logs.”
Different vendors have varying definitions about “Observability”.
Lifetime of system
QUESTION [1] - What is the expected lifetime of this system? (based on existing systems in the organization)
Example: 10 years * 50 weeks per year = 500 weeks
500 weeks * weekly views = Lifetime views
Usage Demographics
QUESTION [2] - Over the lifetime of this system, about how often (per week) do measurements of the system need to be considered by each persona in the company?
Example for a hypothetical 1,000-user scenario, where % Each is the percentage of total users grouped into that persona.
| Persona | % Each | # Users | #/Week | # Lifetime Views [1] | Notes |
|---|---|---|---|---|---|
| Developers | 55% | 550 | 30 | 15,000 | - |
| Operations | 15% | 150 | 70 | 35,000 | - |
| Security | 17% | 170 | 60 | 30,000 | - |
| Managers | 10% | 100 | 15 | 7,500 | - |
| Auditors | 2% | 20 | 2 | 1,000 | - |
| Others | 6% | 60 | 5 | 2,500 | - |
| Total | 100% | 1000 | 182 | 91,000 | - |
The number of Lifetime accesses is used to understand how much history will be stored.
QUESTION [_] - What is the corporate data retention policy which specifies how long historical data is maintained?
Expectations
QUESTION [3] - What expectations for Availability (Uptime) do each persona have of the system?
| Persona | Uptime % Expectation |
|---|---|
| Developers | 95% + |
| Operations | 99% + |
| Security | 99% + |
| Managers | 80% + |
| Auditors | 99% + |
| Others | 85% + |
Measurements
QUESTION [4] - What monitoring is desired?
Examples of usage volume statistics:
- Cloud Regions
- Cloud resource components (Nodes, ELB)
-
Files
- User logins
- User Groups
- Number of accesses by each persona over time [2]
- Rate of users abondoning workflows
Example of limits imposed by cloud vendors:
- App executable size bytes on disk and when loaded in RAM
- Number of endpoints to the AWS API gateway REST API service - errors after 300 endpoints.
- Response time of Lambda API - if more than 30 seconds, a user of your service receives a 504 HTTP Error even though that Lambda transaction is still running in the background.
- The AWS API gateway can have 10,000 (RPS limit) x 29 (timeout limit) = 290,000 open connections. Growth beyond that result in 429 “too many requests”.
- There are many other AWS service quotas
Example of “shallow” incident management metrics:
- Number of incidents to investigate
- TTD (Time To Detect) issue
- TTR (Time to Remediate/Repair) issue
- Frequency of incidents
- Severity level of events
Examples of computing resource usage statistics (at various points in time):
- CPU
- Memory
- Storage usage
- Disk I/O
- Network I/O
PROTIP: Monitoring queues enables identification of bottlenecks which delay response time. Capacity bottlenecks are not revealed until a queue builds up when additional simultaneous users during load tests.
Examples of app-specific statistics, for Consul:
- KV count
- Intentions
- ACLs
- etc.
Unit Cost measurements provide data for business-level assessments when costs are measured against outputs:
- What does it cost to process each request/transaction, by type of process?
- How much of a difference is the cost of a new request vs. existing request?
- What is the cost per change request?
Productivity measurements reveal improvements in terms of speed and effort.
- Cycle time – How long does it take to complete a unit of work, in total, and by phase?
- Break it out by new vs. maintenance work (most will be maintenance)
- Average time to create new document/message
- Average time to change existing document/message
- Dev. “Productivity” - Requests completed per person – What number of new and/or change requests per person per period?
- Requests by new vs. maintenance work (most will be maintenance)
- Average change requests completed per person
- Average new requests completed per person
- Dev. Velocity - How many content edit cycles (iterations) are needed? This can have a significant impact on cycle time and overall productivity.
- Iterations per new release
- Iterations per maintenance release
PROTIP: Less churn and resulting delays occur in firms with alignment on standards, customer experience objectives, and roles responsible.
Levels of monitoring investment
The discussion below traverses from left to right through this table:
| Level of monitoring: | 1 - Shallow Individual Component Monitoring | 2 - In-Depth Monitoring on Different Levels | 3 - Next Generation Monitoring | 4 - Observability |
| Investment (TCO): | Minimal [5] | ~3X | ~10X | ~20X |
| Approach: | Reactive collections | In-depth trends | Responsive alerts | Proactive self-healing |
| Mechanism: | Each component monitored using a different independent approach | Dashboards display various components of each specific service | Interdependence among components apparent when a specific component is changed for manual RCA | Anomalous behavior automatically identified for automated RCA and remediation, using Machine Learning (AI), before a crisis |
| Deficiency: | Extensive and frequent manual investigation [6] | Issues impacting the entire IT stack not apparent | Manual remediation necessary | Human oversight and tuning still needed |
| Achievable (Uptime): | < 65%[6] | < 85% | < 90.0% | < 99.5% |
Minimal investment
QUESTION: [5] What do you consider to be the minimal investment in monitoring infrastructure?
Level 0 -
Level 0 is to use only commands provided by default by the operating system being used.
Level 1 - Reactive Monitoring
Level 1 is to install FOSS monitoring utilities such as Prometheus with Grafana dashboards or Elastic Stack.
- PROTIP: Instead of having each app team figure out how to install, configure, and manage monitoring, many enterprises staff a monitoring team to provide quick start expertise and reduce the time and frustration by each team.
[6] A "reactive" monitoring system means that significant issues may NOT be noticed until users complain (high TTD and low user satisfaction). Tracing of issues encountered by a specific user is not possible at this level. High TTR is likely because success at incident response depend on lucky guesses, every time there is an issue. And troublshooting is needed for every incident because issues are not avoided while time is spent on troubleshooting. This approach also requires long tenure of people, which is unlikely since turnover is usually high under these work conditions. So Uptime would be low, especially if investments in backup and restore are also minimal.
Level 2 is to install licensed monitoring utilities such as Datadog, Splunk, New Relic, Honeycomb, etc.
- NOTE: Some vendors (such as SolarWinds) specialize in network monitoring based on the SNMP (Simple Network Management Protocol). However, more and more data centers disable SNMP to improve security against external hacking. https://learn.hashicorp.com/tutorials/terraform/tfe-log-forwarding?in=terraform/recommended-patterns
Level 3 is to add an enterprise-wide end-to-end “capabilities dashboard” plus tracing to a single user’s impact across components, plus PagerDuty or XMatters for smart alerting/incident management.
- The time that a specific HTTP request or a database call takes to go across various components is called a "span". Each span is associated with attributes. Such instrumentation is done by functions in an open-source Open Telemetry (OTel) library for each programming language and framework (such as Flask for Python). Spans are displayed in the program's console (STDOUT) and also exported to an application performance monitoring utility such as Datadog, which correlates the various spans on a visual dashboard. Spans can be nested, and have a parent-child relationship with other spans. This aggregating of spans is done by a "distributed tracing backend" such as Jaeger. See https://open-telemetry.github.io/opentelemetry-python/getting-started.html
The react-based Heimdall Application Dashboard (instead of Grafana) show links to monitoring data collected into Prometheus:VIDEO:
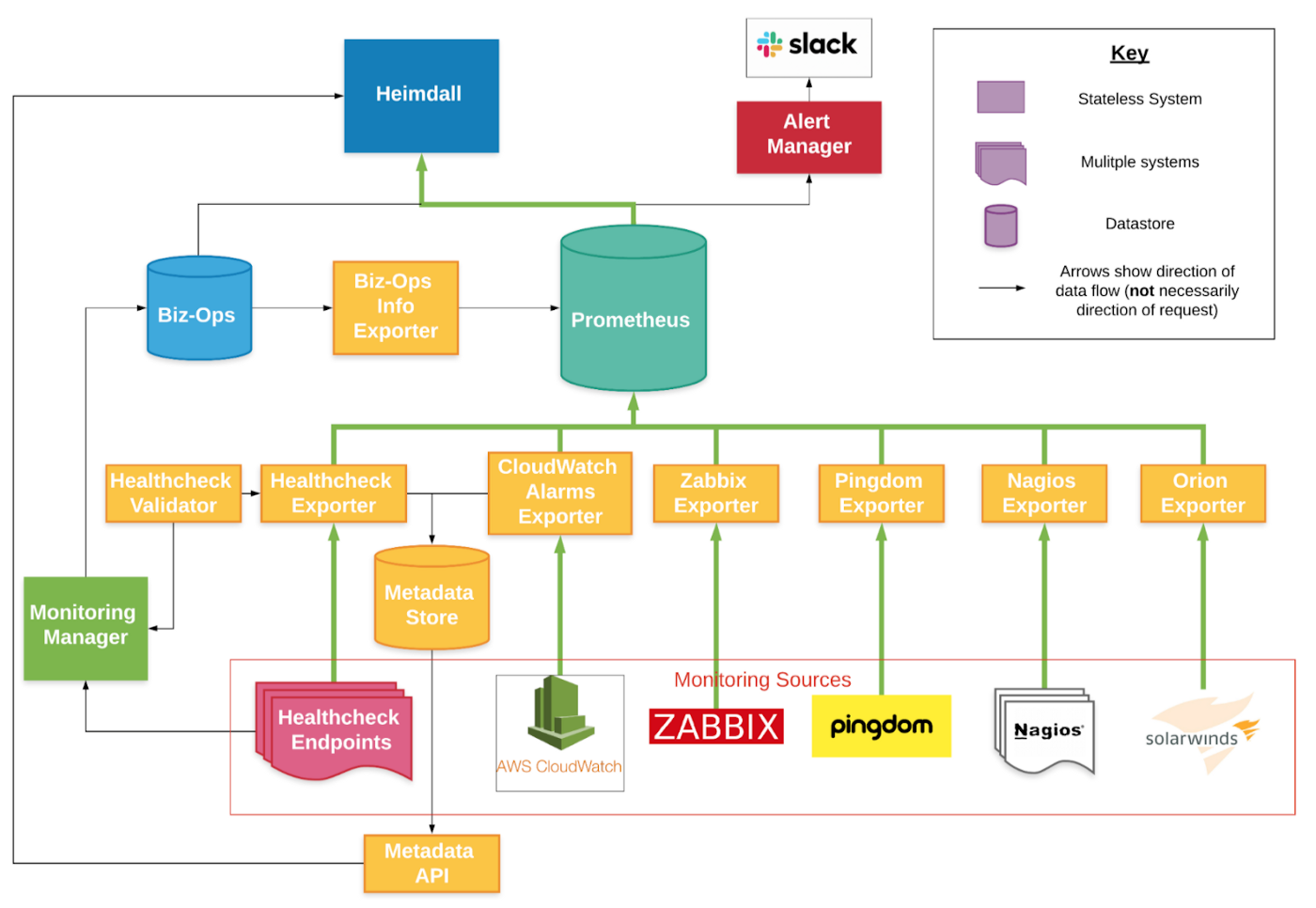
Level 4 is to install Machine-Learning (AI) based “Observability” systems such as InsightFinder, StackState, etc.
- Instrumentation is necessary to determine whether system are able to achieve scalability and availability objectives (and when they are not). Measurable reliability goals enable people to know when to stop tuning efforts. However, there are financial and operational tradeoffs for adopting each level of instrumentation. It is convenient and less stressful when systems are self-healing. But can the organization afford the time and expense to achieve that convenience? One can over-invest in achieving the ultimate level of observability. Over-investment in monitoring drains focus from feature development work. On the other hand, under-investment in monitoring can reduce development teams to “spinning their wheels” on guesses that waste precious time and create frustration which leads to turnover.
Dashboards
Resources
[1] https://f.hubspotusercontent20.net/hubfs/516677/monitoring-maturity-model-2020.pdf
https://www.hashicorp.com/blog/improve-observability-with-opentelemetry-and-consul-service-mesh