

Tools for data science
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
Here is a catalog of what AI and Machine Learning algorithms and Modules offered by Microsoft Azure, Amazon, Google, SAS, MatLab, etc.
- Anomaly Detection to identify and predict rare or unusual data points.
- Clustering to discover structure, separate similar data points into intuitive groups.
- Regression to predict values (forecast the future by estimating the relationship between variables)
- Two-class Classification to answer simple two-choice questions like yes-no or true-false.
-
Multi-class Classification to answer complex questions with multiple possible answers
- (descriptive) Statistical Functions
- Recommendation (collaborative filtering)
- Sentiment Analysis
These Artificial Intelligence (AI) services make use of algorithms:
Microsoft created a cute interactive museum to view their use cases in a non-technical way at http://azuremlsimpleds.azurewebsites.net/simpleds/ along with PDF: Microsoft’s long infographic about algorithms
This cheat sheet PDF of Microsoft’a Azure ML Algorithms
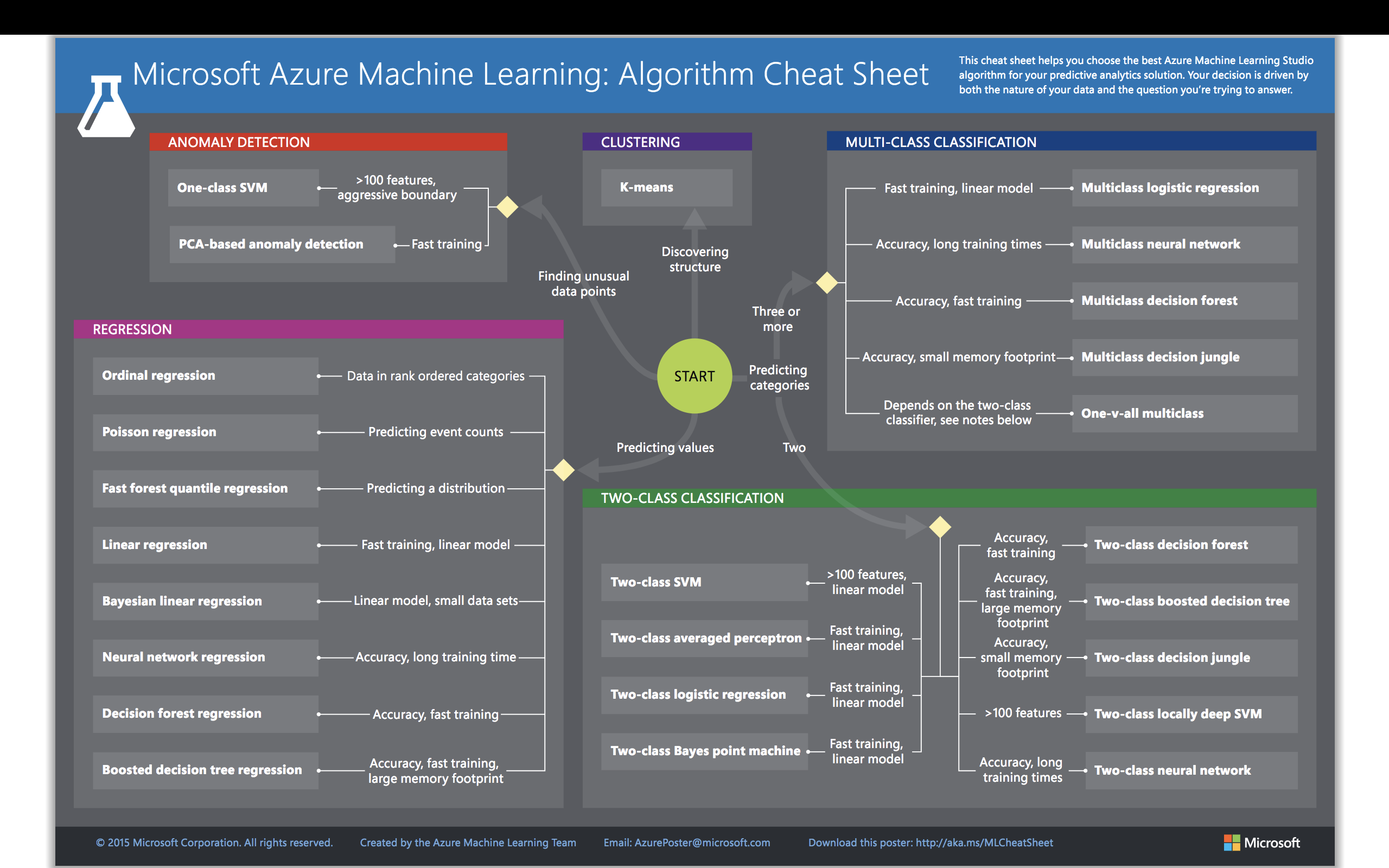
(click for full-screen image)
From the A-Z List of Machine Learning Studio Modules, lists basic database and UI features such as forms, which means it’s building standard computing functions on top of AI capabilities.
SAS machine learning algorithms explains this diagram of their algorithms:

(click image for full screen pop-up)
Translation
https://translate.google.com and the Google Translate API has been working on translating websites since the 90’s. In 2017 Google made a breakthrough
Computer Vision
Open-source OpenCV (Computer Vision) was an early entrant and is still used today by many because it is written in C and runs quite efficiently.
https://docs.microsoft.com/en-us/azure/cognitive-services/custom-vision-service/getting-started-build-a-classifier Hands-on guide: build a classifier with Custom Vision
-
https://algorithmia.com/algorithms/z/ColorPalettefromImage
-
https://algorithmia.com/algorithms/opencv/FaceDetection then https://algorithmia.com/algorithms/opencv/CensorFace
-
https://algorithmia.com/algorithms/ocr/RecognizeCharacters OCR
Some of these make use of OpenCV (CV = Computer Vision).
Voice Recognition
-
Google Cloud Speech API, which powers Google’s own voice search and voice-enabled apps.
-
Microsoft says its Cortana is as accurate as human transcriptionists
NLP Sentiment Analysis
Analyze text for positive or negative sentiment (opinion), based on a training database of potential word meanings, which involved Natural Language Processing:
-
https://algorithmia.com/algorithms/nlp/SentimentAnalysis
-
IBM’s algorithm
Andrew W. Trask, PhD student at University of Oxford Deep Learning for Natural Language Processing authored Grokking Deep Learning.
Use Bag of words and Word2vec transform words into vectors. Use TFLearn, a Python library for quickly building networks.
Document (article) Search
Google made it’s fortune on offering search services.
TF-IDF = Term Frequency - Inverse Document Frequency emphasizes important words (called a vector) which appear rarely in the corpus searched (rare globally). which appear frequently in document (common locally) Term frequency is measured by word count (how many occurances of each word).
The IDF to downweight words is the log of #docs divided by 1 + #docs using given word.
Cosine similarity normalizes vectors so small angle thetas identify similarity.
Normalizing makes the comparison invariant to the number of words. The common compromise is to cap maximum word count.
CNTK 106: Part B - Time series prediction with LSTM (IOT Data)
More
This is one of a series on AI, Machine Learning, Deep Learning, Robotics, and Analytics:
- AI Ecosystem
- Machine Learning
- Microsoft’s AI
- Microsoft’s Azure Machine Learning Algorithms
- Microsoft’s Azure Machine Learning tutorial
- Python installation
- Image Processing
- Tessaract OCR using OpenCV
- Multiple Regression calculation and visualization using Excel and Machine Learning
- Tableau Data Visualization