

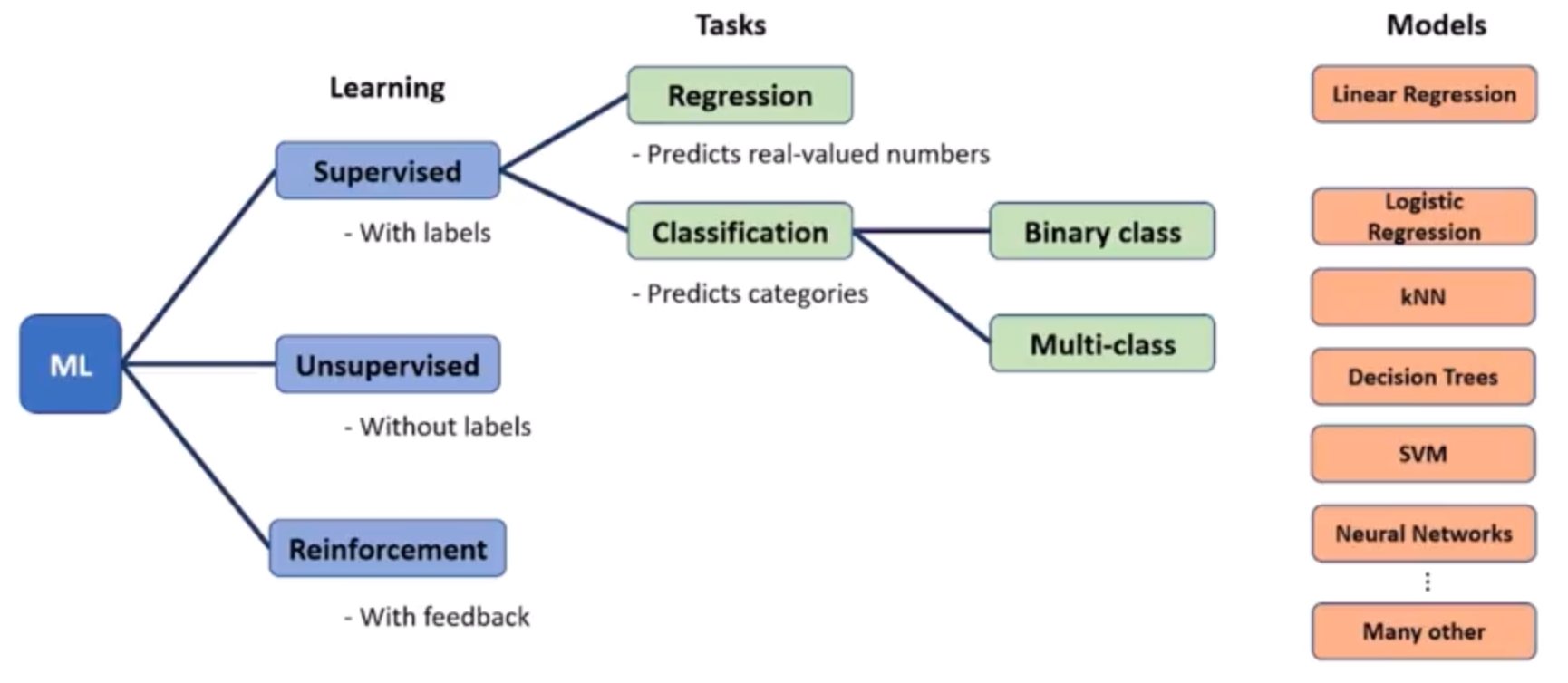
Different ways to use data to create a model (program)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
The pervasiveness of AI and Machine Learning was recognized by Google CEO Sundar Pichai when he said in 2016:
“Machine learning is a core, transformative way by which we’re rethinking how we’re doing everything. We are thoughtfully applying it across all our products, be it search, ads, YouTube, or Play. And we’re in early days, but you will see us — in a systematic way — apply machine learning in all these areas.”
Skill-building from games
In 1997, when Deep Blue beat world chess champion Gary Kasparov, it did so by “brute force”, by using a supercomputer to analyze the outcome of every possible move, looking further ahead than any human possibly could. That wasn’t Machine Learning or AI.
But In 2016, IBM’s Watson software beat top Jeopardy game champions by “learning” from books and encyclopedias. IBM only created the program that enables the computer to learn. The software makes use of a “model” from example vs. following strictly static program instructions (logic defined by human developers).
Machine learning is a type of AI (Artificial Intelligence) that enables computers to do things without being explicitly programmed by human developers. Rather than explicit programming, Machine Learning algorithms identify rules through “training” based on many examples.

The photo above is the Todai Robot,
back in 2014, scoring among the upper 20% of students in Japan’s university entrance exams – writing essays using a pen on paper. In Japanese. It knows 8,000 Japanese words, 2,000 mathematical axioms, and uses “symbolic computation” for “automatic reasoning” on 15 billion sentences.
In 2017, the top ranked player in the Chinese game Go was defeated by Google’s AlphaGo, which is based on Google’s DeepMind acquisition. The software made moves that many human players considered illogical. BTW, Go is considered the most complex game ever invented. Whereas chess players have, at any given turn, an average of 35 possible moves, on a Go board’s 19-by-19 grid, there are 250 possible moves.
Also in 2017, all top-ranked poker players were bested by software named Libratus from Tuomas Sandholm at CMU. The software adjusted its strategies during the tournament. And its algorithms for strategy and negotiation are game-independent, meaning they’re not just about poker, but a range of adversarial problems.
Rather than neat rows structured in fixed columns and rows within tables, AI computers deal with less structured data, such as (natural language text, images, and videos).
21 August 2017, Elon Musk tweets: “OpenAI first ever to defeat world’s best players in competitive eSports [dota2]. Vastly more complex than traditional board games like Chess & Go”. VIDEO.
Use Cases for AI
What ordinary people might appreciate:
- Estimate the price of a house given real estate data (multiple regression), so you don’t waste time on properties that don’t fit your criteria.
- Classify movie reviews from imdb.com into positive and negative categories (such as “revenge”), to spend time only on movies you want to see.
- Classify news wire articles by topic (multi-class classification), to save time avoiding skimming articles not of interest to you specifically.
For small businesses:
- Sort vegetables using computer vision
For enterprises:
- Data Security - identify malware by detecting minute variations in file signatures.
- Fraud detection - fight money laundering by finding anomalies in transactions.
- Financial trading
- Health care - understand risk factors and spot patterns in medical info
- Marketing - personalize ads based on interests identified for individuals
- Smart cars
- Insurance - identify risks in smaller populations
Algorithms
Use of hard-coded (static) “rules” crafted by human programmers is called “symbolic AI”, used in “expert systems” fashionable during the 1980s.
Machine learning algorithms identify information from data fed through “generic” (general purpose) algorithms which build their own logic from detecting patterns within the data.
Patterns are recognized by neural network algorithms. This cycle of “learning” is implicit in a definition of Machine Learning by Mitchell (in 1997): “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E”.
The “network” in a neural network has multiple “layers” or data-processing modules that “distill” data. Models using a small number of layers are called “shallow learning”. GoogleNet in 2014 used 22 layers. In 2016, one network uses over 1,000 layers.
By contrast, the human brain has 300 million modules that recognize patterns, each having 100 neurons.
At the input layer, the network trains on a specific set of “features” and then sends that information to the next layer. That next layer combines previous conclusions with other features and passes it to the next layer, and so on, sequentially.

Models are trained using examples so they can be used to make predictions. The result of training is a mathematical model used to make predictions, such as taking an unlabled photo and deriving the label “cat”.
Terminology
An example of the last layer which presents the output/decision (from recognizing what number is written down in a photo from the MNIST collection) is a 10-way “softmax” layer returning an array of 10 probability scores (all summing to 1). Each of the 10 contains the probability that the digit image belongs to one of 10 digit classes.
“Supervised” Machine Learning systems learn how to combine input to produce useful predictions on never-before-seen data.
Machine learning uses some terms that have alternate meanings for words also used by traditional programmers and statisticians:
-
(In statistics, a “target” is called a dependent variable.) In machine learning, a target is also called a label, what a model should ideally have predicted, according to an external source of data.
-
A “label” is a specific instance of a class. A label can be an answer (target) for a prediction task – either the answer produced by a machine learning system, or the right answer supplied in training data. It’s represented as “y” in mathematical notation.
-
Data points are called “samples” or “examples”, represented as “x” in mathematical notation.
-
Unlabeled examples are used for making predictions on new data.
-
A “category” of a classification problem is called a class. For example, when classifying pictures, “puppy” and “muffin” are two of the classes. Each class describes a set of possible labels to choose from.
-
A model maps examples to predicted labels. It’s defined by internal parameters, which are learned.
-
The prediction error, also called loss value, the measure of the distance between a model’s prediction and the target.
It’s a metric of measurements that you care about, which may or may not be directly optimized.
-
An instance is the aspect about which you want to make a prediction. (An instance is called an “objective” in other fields.)
-
A feature is a property of an instance used in a prediction task. For example, a web page might have a feature “contains the word ‘cat’”.
A feature in machine learning is called a “variable” in statistics. A feature is an input variable—the x variable in simple linear regression. (Feature creation in machine learning is called a “transformation” in statistics.)
-
A feature Column is a set of related features, such as the set of all possible countries in which users might live. An example may have one or more features present in a feature column. A feature column is referred to as a “namespace” in the VW system (at Yahoo/Microsoft), or a field. Example: An instance (with its features) and a label.
-
An objective is a metric that an algorithm is trying to optimize.
-
A pipeline is the infrastructure surrounding a machine learning algorithm. A particular pipeline can include:
- gathering the data from the front end,
- putting it into training data files,
- training one or more models, and
- exporting the models to production.
Types of machine learning
 </sub>–by Geena Kim</sub)
</sub>–by Geena Kim</sub)
Supervised learning
The supervised learning approach predicts an output by making use of a labeled data set of training data(examples) which provide and “answer” or target giving feedback on what is correct or not.
- The training correlates features to outputs in order to predict outputs based on new inputs.
For time series analysis, use a “recurrent net”. Recurrent nets process data that changes with time, using a feedback loop that acts as a forecasting engine.
Recurrent networks have a network topology in which data flow itself is recycled. It is used, for example, to generate sequences of words from the vectors describing the “meaning” of pictures. Each word depends on all that have already been produced.
- For text processing (Sentiment Analysis)
and speech recognition: use a
Recurrent Net or a
RNTN (Recursive Neural Tensor Network)
that operates at individual character level.
RNTNs were conceived by Richard Socher of MetaMind.io as part of his PhD thesis at Stanford. In 2016 it became part of Salesforce Einstein Predictive Services at https://metamind.readme.io/v1/docs
RNTNs are better than feed-forward or recurrent nets with data with a hierarchical structure (binary trees), such as the parse trees of a group of sentences.
- For image (object) recognition is DBN (Deep Belief Network) or Convolutional Net.
Convolution means use of the same filter (also called a “kernel”) across the whole image, just like use of a filter in Photoshop. Clarifai uses a convolutional net to recognize things and concepts in a digital image. It then presents similar images.
Kernel methods are a group of algorithms for classification–Support Vector Machine (SVM) being the best known from Vapnik and Cortes in the early 1990s at Bell Labs and Vapnik and Chervonenkis as early as 1963. SVM classifies by finding in training data “decision boundaries” between sets of points belonging to different categories. Classifying new data points involves checking which side of the decision boundary they fall on.
Used in both feed-forward and (unrolled) recurrent networks is Backpropagation to update weights so networks learn (improve). * The Deep Visualization Toolkit illustrates the intermediate process.
Unsupervised learning
The “unsupervised” part of unsupervised learning means it makes use of a dataset without labels.
It uses “feature extraction” to discover a good internal representation of the input. It identifies the structure of data to solve some given task.
It uses “Pattern recognition” to classify patterns and clusters data.
- Autoencoders encode their own structure. They are feature extractors with the same number of input and output nodes.
A hidden layer in Autoencoders provides a bottleneck of nodes reconstruction of input layer. So they can be used for image compression.
- RBM (Restricted Boltzmann Machine) is an autoencoder with one visible and one hidden layer. Each visible node connects to all nodes in the hidden layer.
The “restricted” is because there is no connection among nodes within its layer.
RBM is like a two-way translator. RBM determines the relationship among input features.
In training loops, RBM reconstructs inputs in the backward pass.
RBM uses a measure called “KL Divergence” that compares actual to recreation of data. RBM makes decisions about what features are important based on weights and overall bias.
All this means that data in RBM does not need to be labeled.
As an example, to determine whether an animal is acerous or not acerous (has horns), it look at features such as color, number of legs, horns.
“Principal Component Analysis” (PCA) is a linear method for finding a low-dimensional representation.
Reinforcement learning
Reinforcement learning does not provide feedback until a goal is achieved. Its objective is to select an action to maximize payoff.
In Dec 2013, Volodymyr Mnih and others at DeepMind.com (a small company in London) uploaded to Arxiv a paper titled “Playing Atari with Deep Reinforcement Learning”. The paper describes how a “convolutional neural network” program learned to play several games on the Atari 2600 console (Pong, Breakout, SpaceInvaders, Seaquest, Beam Rider) by observing raw screen pixels of 210 × 160. The program learned by receiving a reward when the game score increased. This was hailed as “general AI” because the games and the goals in every game were very different but, without any change, learned seven different games, and performed better than some humans in three of them. * Their Feb. 2015 article in Nature gave them widespread attention. Then Google bought DeepMind (for $400 million).
-
https://www.youtube.com/watch?v=e3Jy2vShroE&index=17&list=PLjJh1vlSEYgvZ3ze_4pxKHNh1g5PId36-
-
https://www.nervanasys.com/demystifying-deep-reinforcement-learning/
Transfer learning
- https://www.youtube.com/watch?v=Yx6Wv_SCKjI&index=16&list=PLjJh1vlSEYgvZ3ze_4pxKHNh1g5PId36-
One-shot learning
(aka Probabilistic Programming) is where a neural network learns from one (or a few) examples, as opposed to a large amount of data.
Deep Learning
“Deep learning” is a specific subfield of machine learning. The “deep” in “deep learning” is not about “deeper” understanding, but about the depth of various filters in a multi-stage information distillation operation. Each stage extracts some meaning from different representations of the input.
Deep learning learns all layers of representation “greedily”, in parallel at the same time, rather than each layer in succession. Intermediate incremental representations are learned jointly. Each layer is updated to follow the representational needs of layers both above and below itself.
See https://www.wikiwand.com/en/Deep_learning
Tools for Machine Learning
From http://www.infoworld.com/article/3163525/analytics/review-the-best-frameworks-for-machine-learning-and-deep-learning.html
Python or R is supported.
Many corporations have efforts using Machine Learning:
SAP’s “Leonardo” platform for ML courseuses the R language.
Tool: Neural Network Playground.
Python
Python is extended by libraries:
- for handling csv, textblob and other data formats
- for visualization: Matplotlib, Seaborn, Bokeh, Yellowbrick
- for matrix operations, Numpy (Quickstart)
- for statistics and linear algebra: SciPy, tweepy
- for vectorized computing: Pandas and SFrame, which is not limited to datasets that can fit in memory, so it can deal with large datasets, even on a laptop.
- for Machine Learning, see below:
Machine Learning frameworks
Scikit-learn 0.18.1 from Scikit-learn
-
http://www.infoworld.com/article/3158509/analytics/review-scikit-learn-shines-for-simpler-machine-learning.html
-
Mature documentation and libraries
-
Python-based, but does not support PyPy compiler
Spark MLlib 2.01 from Apache Software Foundation
-
http://www.infoworld.com/article/3141605/artificial-intelligence/review-spark-lights-up-machine-learning.html
-
Written in Scala and uses the linear algebra package Breeze which uses netlib-java.
-
Get data easily from Spark big-data clusters
-
Supported in the Databricks cloud
Keras (at https://keras.io) is not a library of its own but is a high-level API to simplify the complexity of deep learning frameworks by running on top of other deep learning APIs (TensorFlow, Theano and CNTK).
-
Keras runs on both CPU and GPU through backend engines Google’s TensorFlow and Theano developed by the MILA lab at Universite de Montreal.
-
PROTIP: Bypass manual installation by using the Docker image for Keras at
https://github.com/fchollet/keras/tree/master/docker based on Ubuntu.
In 2007, Nvidia launched CUDA, a C++ programming interface for its line of GPUs (Graphic Processing Units) begins to replace clusters of less efficient CPUs.
- In 2017, NVIDIA provides GPU supercomputers used in many self-driving cars.
In 2017, basic Python scripting skills suffice to do advanced deep learning research.
https://www.exxactcorp.com/blog/Deep-Learning/tensorflow-vs-pytorch-vs-keras-for-nlp
Java in DL4j
Although Python is vastly more popular, there is a Java library that can run on both Scala and Clojure.
Adam Gibson at SkyMind developed Deeplearning4j (referred to as DL4j) to be commercial-grade library to run on a distributed, multi-node setup. It comes with GPU support for distributed training.
The DL4j team built a vectorization library called Canova.
In it one can select values for its hyper parameters.
DL4j supports most of the deep nets – RBM, DBN, Convolutional net, Recurrent net, RNTN, autoencoders, and vanilla MLP.
Deep Learning Frameworks
The list of frameworks today is NVIDIA to make because <a target=”_blank” href=”they optimize for their NVIDIA GPU Cloud (NGC) at ngc.nvidia.com.
A ranking of Deep Learning frameworks based on GitHub star count in 2017:

Since then, Google’s search history shows Pytorch overtaking Tensorflow:
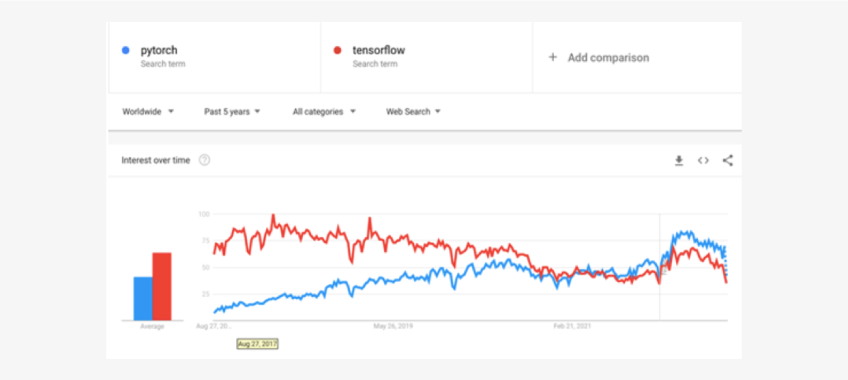
Facebook/Meta’s PyTorch framework rising steadily from October, 2018 to become the one most people use:
- On NVIDIA’s NGC
- Based on Torch, another deep learning framework based on Lua
- Easier to learn and debug its dynamic computational processes
- TorchVision, TorchText, TorchAudio, PyTorch-XLA, PyTorch Hub, SpeechBrain, TorchX, TorchElastic and PyTorch Lightning
- Pytorch perf tuning is easier due to its reliance on native support for asynchronous execution through Python means optimal performance in data parallelism
- Poster projects: CycleGAN, FastAI, Netron
TensorFlow AI platform from Google
- TensorFlow 2.0 has Keras integrated, supports dynamic graphs using eager execution
- When running on CPUs, TensorFlow wraps itself over a low-level library for tensor operations called Eigen. BLAS
- When running on GPUs, TensorFlow wraps itself over a library of optimized deep learning operations called cuDNN (with CUDA drivers developed by NVIDIA).
- TorchServe deployment
- TensorFlow Serving, TensorFlow Extended, TF Lite, TensorFlow.js, TensorFlow Cloud, Model Garden, MediaPipe and Coral
- Google TPU (Tensor Processing Units)
-
Poster projects: DeepSpeech, Magenta, StellarGraph
- Google’s Machine Learning Crash Course
Microsoft Cognitive Toolkit v2.0 Beta 1 (aka CNTK 2), as of 2017:
- http://www.infoworld.com/article/3138507/artificial-intelligence/review-microsoft-takes-on-tensorflow.html
- uses a declarative BrainScript neural network configuration language
- No MacOS support yet
- CNTK 2 models on GPU-equipped N-series family of Azure Virtual Machines.
- Azure Machine Learning is part of the larger Microsoft Cortana Analytics Suite offering.
Caffe 1.0 RC3 from Berkeley Artificial Intelligence…
- http://www.infoworld.com/article/3154273/analytics/review-caffe-deep-learning-conquers-image-classification.html
MXNet v0.7 from Distributed Machine Learning Amazon…
-
http://www.infoworld.com/article/3149598/artificial-intelligence/mxnet-review-amazons-scalable-deep-learning.html
-
Amazon’s DNN framework of choice, combines symbolic declaration of neural network geometries with imperative programming of tensor operations.
-
MXNet scales to multiple GPUs across multiple hosts with a near-linear scaling efficiency of 85 percent and boasts excellent development speed, programmability, and portability.
-
Its dynamic dependency scheduler allows mixing symbolic and imperative programming flavors: Python, R, Scala, Julia, and C++
-
trained MXNet models can also be used for prediction in Matlab and JavaScript.
-
Ahead of TensorFlow with embed imperative tensor operations.
Data representation
Tensors generalize matrices to an arbitrary number of axes (3 or more “dimensions”).
A tensor that contains only one number is called a “scalar”
(aka “scalar tensor”), also called a “0D tensor” because
in Numpy the ndim attribute of a scalar tensor has 0 axis (ndim == 0).
(Yes, it confuses axis with dimensions)
An array (list) of several numbers is called a vector or 1D tensor having one axis. As Lecun explains it:
A vector of 5 entries is called a “5-dimensional vector”. Do not confuse a 5-dimensional vector with a 5D tensor! A 5D vector has only one axis and has 5 dimensions along its axis, while a 5D tensor has 5 axes (and may have any number of dimensions along each axis).
An array of vectors is a matrix, or 2D tensor of two axes.
x = np.array([[1, 2, 3, 4, 5],
[10, 11, 12, 13, 14],
[100, 101, 102, 103, 104]])
Each vertical “column” is like a variable. The first one has values 1, 10, and 100 from the three lines (rows), which are akin to a set of observations for a particular point in time.
The “shape” of the above is (3,5) for 3 vectors each containing 5 values.
A 3D tensor is defined as a “cube” of numbers. The MNIST library of 60,000 sample images, each consisting of 28x28 black-and-white pixels (each pixel represented by a number range from white to black), has a shape of (60000,28,28).
4D tensors are used to process matrices of color pictures :
(samples, width, height, channels)
5D tensors are used when processing video data:
(samples, frames, width, height, color_depth).
In Python Numpy, a data type of “float32” or “float64” is a scalar tensor (or scalar array).
“Selecting” specific elements in a tensor is called “tensor slicing”.
Axies for Shape
2D tensors containing simple vector data of shape (samples, features) are typically processed in “fully-connected” (“densely-connected” or “dense”) layers using the Dense class in Keras.
3D tensors containing sequence data of shape (samples, timesteps, features) are typically processed by “recurrent” layers such as a LSTM layer.
4D tensors containing image data is typically processed by Convolution2D layers.
5D tensors containing video data use the reshape layer. See https://github.com/anayebi/keras-extra for using Extra Layers for Keras to connect a RNN (Recurrent Neural Network) to a Convolutional Neural Network (CNN) by allowing the CNN layers to be time distributed.
Pandas
The Padas Python library reads databases directly into these Pandas structures:
| Dimensions | Name | Description |
|---|---|---|
| 1 | “Series” | Indexed 1 dimension data structure |
| 2 | “Timeseries” | Series using time stamps as an index |
| 3 | “DataFrame” | A two-dimensional table |
| 4 | “Panel” | A three-dimensional table data structure |
-
A scalar regression task is one where the target is a continuous scalar value. For example, when predicting house prices, the different target prices form a continuous space.
-
A vector regression task is one where the target is a set of continuous values (e.g. a continuous vector) while doing regression against multiple values (e.g. the coordinates of a bounding box in an image).
Metrics
The goal is to derive models that generalize.
When using its training data, a “loss function” is used to measure how well a neural network layer meets its objective. Thus, some call it an “objective function”.
It is called a function because it’s the result of changes, and thus used to determine whether changes are moving in the right direction. Changes are made to minimize the loss function.
The number of data values is typically split into a training set, a validation set, and a test set. This is so we don’t evaluate data using what was used for training in order to avoid overfitting.
An “optimizer” is the mechanism a network uses to update itself (based on data received and loss function values). It implements a specific variant for stochastic gradient descent.
Gradient Boosting
To address shallow learning problems, where structured data is available, “gradient boosting machines” have been used.
Practitioners of gradient boosting make use of the XGB library, which supports both the two most popular languages of data science: Python and R.
Introductory Resources
YOUTUBE: A friendly introduction to Deep Learning and Neural Networks by Luis Serrano
Machine Learning is Fun! (article on Medium) self-proclaimed “the world’s easiest introduction to Machine Learning”.
Adam Geitgy’s introduction of Machine Learning https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471/ “for anyone who is curious about machine learning but has no idea where to start”
https://www.youtube.com/watch?v=dYT2LSuemgg Apr 26, 2017 by Dr. Joseph Reger, CTO of Fujitsu Technology Solutions
Enterprise Machine Learning in a Nutshell free class from SAP.
Recommended by Elon Musk: Nick Bostrom “SuperIntelligence: Paths, Dangers, Strategies”
More
This is one of a series on AI, Machine Learning, Deep Learning, Robotics, and Analytics:
- AI Ecosystem
- Machine Learning
- Microsoft’s AI
- Microsoft’s Azure Machine Learning Algorithms
- Microsoft’s Azure Machine Learning tutorial
- Python installation
- Image Processing
- Tessaract OCR using OpenCV
- Multiple Regression calculation and visualization using Excel and Machine Learning
- Tableau Data Visualization