

How to code Python as if it matters, as shown in my samples github: how best to use Keywords, arguments, Exception Handling, OS commands, Strings, Lists, Sets, Tuples, Files, Timers
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
- Why This?
- Retry backoff with jitter
- PCEP-30-02 Exam Outline
- Debugging using IDE
- Pydantic
- Use Python Code Scans
- Lexis
- Built-in Methods/Functions
- import
- print, printf, echo
- While Loop
- Magic underlines
- Operators
- What Day and Time is it?
- Run Duration calculations
- Swapping
- Sorting
- Avoid divide by zero errors
- Random
- Environment Variable Cleansing
- Object-oriented class functions
- Blob vs. File vs. Text
- GUI
- Cloud
- Web Scraper
- Movie Recommender
- GCP
- OpenCV
- GIS
- String Handling
- Regular Expressions
- Unicode Superscript & Subscript characters
- Internationalization & Localization (I18N & L18N)
- Version management
- File open() modes
- File Copy commands
- Error Exception handling
- Operating system
- Command generator
- CLI code enhancement
- Handling Arguments
- Python in the Cloud
- Sets: Day of week Set handling
- Lists
- Tuples
- Range
- List comprehension
- Classes and Objects
- Protocols
- Secure coding
- Insecure code in Pygoat
- Logging for Monitoring
- Use assert only during testing
- Concurrency Programming
- Bit-wise operators
- Stegnography
- Parallel Computing
- ODBC
- Referenes
- CS50P Harvard
- Cybrary.it
- CS50 Python class at Project STEM
- Streamlit
- Docstrings
- Google Style Docstrings
- Compilers
- Resources
- Algorithms: Big O Time Complexity
- Data Managements
- Visualization
- More about Python
 NOTE: Content here are my personal opinions, and
not intended to represent any employer (past or present).
“PROTIP:” here highlight information I haven’t seen elsewhere on the internet
because it is hard-won, little-know but significant facts
based on my personal research and experience.
NOTE: Content here are my personal opinions, and
not intended to represent any employer (past or present).
“PROTIP:” here highlight information I haven’t seen elsewhere on the internet
because it is hard-won, little-know but significant facts
based on my personal research and experience.
This is the last in my series of articles about Python:
-
Put learning and creativity to work on the python-samples.py program described at:
wilsonmar.github.io/python-samples -
Handle the intricacies of installing Python and associated utilities (pyenv, pip, venv, conda, etc.) at:
wilsonmar.github.io/python-install -
Handle the intricacies of installing Jupyter which runs Python at:
wilsonmar.github.io/jupyter -
Know who provides Python coding tutorials at:
wilsonmar.github.io/python-tutorials -
Analyze the topics covered in certification tests at:
wilsonmar.github.io/python-certs -
Know Python language coding tricks and techniques at:
wilsonmar.github.io/python-coding
Why This?
In my python-tutorials page I list the many tutorials on YouTube and paid subscription channels.
What I don’t like about them I aim to fix on this page.
-
Over-emphasis on games rather than practical usage that improves productivity, etc. Making trivial games cheapens Python as if it doesn’t matter.
-
Assumption that people invoke Python programs and wait to manually answer input() commands. In real life, Python programs are executed automatically. So provide data in CLI invocation parameters and CSV files. Verify whether all input data is correct before making changes.
-
Lack of security features, such as retrieving API keys from a memory variable or (better yet) from a Key Vault rather that having them hard-coded in the program source code.
-
Over-emphasize the use of a particular IDE add-ons which those who use Google Colab can’t take advantage of. The most popular IDEs for Python are:
-
VSCode from Microsoft (free) has add-ons for Python, but some fear vulnerabilities from unknown authors. BLOG: Setup VSCode for Python Development https://code.visualstudio.com/docs/editor/extension-marketplace
-
PyCharm (FREE or PRO $89/$71/$53 year)
-
Cloud9 free on-line on AWS (which automatically generates new credentials every 5 minutes or on browser Reset*)
-
Stryker?
-
Retry backoff with jitter
When a program is not successful at reaching a remote service, the program should use this standard error-handling strategy for network applications defined at
- https://cloud.google.com/iam/docs/retry-strategy
When communication lines are temporarily busy (and not refused, as in “not found” return code 404):
Retry until quota is reached, using truncated exponential backoff with introduced jitter.
- https://en.wikipedia.org/wiki/Exponential_backoff
- https://en.wikipedia.org/wiki/Jitter
- https://en.wikipedia.org/wiki/Truncated_exponential_backoff
- https://en.wikipedia.org/wiki/Exponential_backoff#Exponential_backoff
- https://en.wikipedia.org/wiki/Exponential_backoff#Exponential_backoff_with_jitter
If a request fails: Before each retry, the wait time is min((2n + random-fraction), maximum-backoff), with n starting at 0 and incremented by 1 for each retry.
- wait 1 + random-fraction seconds, then retry the request.
- wait 2 + random-fraction seconds, then retry the request.
- wait 4 + random-fraction seconds, then retry the request.
- Continue this pattern, waiting 2n + random-fraction seconds after each retry, up to a maximum-backoff time.
- After deadline seconds, stop retrying the request.
The backoff function in sample program gcp-services.py is defined by this code:
def backoff(
max_retries: int = 5,
exceptions: Union[Type[Exception], List[Type[Exception]]] = Exception,
base_delay: float = 0.5,
max_delay: float = 60.0,
factor: float = 2.0,
jitter: bool = True,
on_backoff: Optional[Callable[[Dict[str, Any]], None]] = None
) -> Callable:
Its parameters are named with default values, so can be omitted from the function call:
- max_retries is the maximum number of retries to attempt.
- exceptions is the exceptions to catch and retry.
- base_delay is the base delay in seconds – a random-fraction of a second (less than or equal to 1) to prevent clients from becoming synchronized and sending large numbers of retries at the same time.
- max_delay is the maximum delay in seconds.
- factor is the factor to multiply the delay by.
- jitter is the small, random delay between retries to prevent the thundering herd problem (a synchronized wave of retries from multiple clients).
-
on_backoff “None” is NO callable (callback) to call when a retry is made.
- Specify a maximum-backoff with the maximum amount of time, in seconds, to wait between retries. Typical values are 32 or 64 (25 or 26) seconds. Choose the value that works best for your use case.
Additionally:
- A deadline with the maximum number of seconds to keep sending retries. For example, in a continuous integration/continuous deployment (CI/CD) pipeline that is not highly time-sensitive, set deadline to 300 seconds (5 minutes).
PCEP-30-02 Exam Outline
This article contains topic names and links to the PCEP™ – Certified Entry-Level Python Programmer (Exam PCEP-30-02) last updated: February 23, 2022: Sections:
- 7 items (18%) Computer Programming and Python Fundamentals
- 8 items (29%) Control Flow – Conditional Blocks and Loops
- 7 items (25%) Data Collections – Tuples, Dictionaries, Lists, and Strings
- 8 items (28%) Functions and Exceptions
1: Computer Programming and Python Fundamentals
1.1 – Understand fundamental terms and definitions
- interpreting and the interpreter, compilation and the compiler
- language elements,
- lexis, syntax analysis (parsing), semantics (applying language rules such as type mismatch)
- Python keywords, instructions
- indenting
- REPL (Read Evaluate Print Loop interactive), control-D to exit()
- comments. PROTIP: Text between triple-doublespace are actually string objects in the byte code
- literals: Boolean, integer, floating-point numbers, scientific notation, strings. b’data’ literals can be split().
- the print() function
- the input() function
- numeral systems (W: binary, octal, decimal, hexadecimal) W, *
- numeric operators: ** * / % // + – // is floor division. Py3: Division always returns a float. Num (mod) % 2 is 0 for odd, 1 for even
- string operators: * +
- assignments and shortcut operators
2: Data Types, Evaluations, and Basic I/O Operations (20% - 6 exam items)
- operators: unary and binary, priorities, and binding
- bitwise operators VIDEO: ~ & ^ | << >> (Mandelbrot)
- Boolean operators: not and or
- Boolean expressions (True/False)
- relational operators ( == != > >= < <= ), building complex Boolean expressions
-
accuracy of floating-point numbers 4.5e9 == 4.5 * (10 ** 9) == 4.5E9 == 4.5E+9
- basic input and output operations using the input(), print(), int(), float(), str(), len() functions
- formatting print() output with end= and sep= arguments
- type casting
- basic calculations
- simple strings: constructing, assigning, indexing, slicing comparing, immutability
>>> "{} {} cost ${}".format(6, "bananas", 1.74 * 6)<br />
'6 bananas cost $10.44'
2: Control Flow Control – Conditional Blocks and Loops (29% - 8 exam items)
2.1 – Make decisions and branch the flow with the if instruction
- conditional statements: if, if-else, if-elif, if-elif-else
- multiple conditional statements
- nesting loops and conditional statements
2.2 – Perform different types of iterations
- the pass instruction
- building loops: while, for, range(), in
- iterating through sequences
- expanding loops: while-else, for-else
- controlling loop execution: break, continue
3: Data Collections – Lists, Tuples, and Dictionaries (25% - 7 exam items)
3.1 – Collect and process data using lists
- simple lists: constructing vectors
- indexing and slicing
- the len() function
- lists methods: indexing, slicing, basic methods (append(), insert(), index()) and functions (len(), sorted(), etc.), del instruction, iterating lists with the for loop, initializing,
-
in and not in operators, list comprehension, copying and cloning
- lists in lists: matrices and cubes
3.2 – Collect and process data using tuples
- tuples: indexing, slicing, building, immutability
- tuples vs. lists: similarities and differences, lists inside tuples and tuples inside lists
3.3 Collect and process data using dictionaries
- dictionaries: building, indexing, adding and removing keys, iterating through dictionaries as well as their keys and values, checking key existence, keys(), items() and values() methods
3.4 - Operate with Strings
- strings ASCII, UNICODE, UTF-8 (rendered/transmitted as pairs of bytes in norsk.encode(“utf-8”)
- indexing, slicing, immutability
- escaping using the \ character
- quotes and apostrophes inside strings
- multiline strings
-
basic string functions & methods: upper(), lowe
- copying vs. cloning, string vs. string, string vs. non-string,
4: Functions and Exceptions (20% - 6 exam items)
4.1 – Decompose the code using functions
- defining and invoking your own functions and generators
- The return and yield keywords, returning results,
- the None keyword (instead of return 0)
- recursion
4.2 – Organize interaction between the function and its environment
- parameters vs. arguments,
- positional keyword and mixed argument passing,
- default parameter values
- converting generator objects into lists using the list() function
- name scopes, name hiding (shadowing), the global keyword
4.4 – Basics of Python Exception Handling
All instances in Python must be instances of a class that derives from BaseException. Before using a divide operator:
try:
a = 10/0
print (a)
except ArithmeticError:
print ("microbit-001: This raises an arithmetic exception.")
else:
print ("Success.")
- try-except / the try-except Exception
- ordering the except branches
- propagating exceptions through function boundaries
- delegating responsibility for handling exceptions
References about Exception Handling:
4.3 – Python Built-In Exceptions Hierarchy
locals()[‘builtins’]
Python inherits from the Exceptions class.
- BaseException
The BaseException class includes a with_traceback(tb) method which explicitly sets the new traceback information to the tb argument that was passed to it.
- Exception is most commonly inherited type.
- ArithmeticError when attempting to divide by zero, or when an arithmetic result would be too large for Python to accurately represent.
- AssertionError when assert statements fail
- FloatingPointError
- OverflowError
- ZeroDivisionError
- AssertionError
- Exception is most commonly inherited type.
- SystemExit
- KeyboardInterrupt when the user presses Ctrl+C or other key combination that causes an interrupt to the executing script
Abstract exceptions:
- ArithmeticError
- LookupError
- IndexError
- KeyError
- TypeError
- ValueError
Debugging using IDE
See key/value pairs without typing print statements in code, like an Xray machine:
- Click next to a line number at the left to set a Breakpoint.
- Click “RUN AND DEBUG” to see variables: Locals and Globals.
- To expand and contract, click “>” and “V” in front of items.
- “special variables” are dunder (double underline) variables.
- Under each “function variables” and special variables of their own. For a list, it’s append, clear, copy, etc.
- Under Globals are its special variable (such as file for the file path of the program) and class variables, plus an entry for each class defined in the code (such as unittest).
Pydantic
Pydantic at docs.pydantic.dev) is the most widely used data validation library for Python.
Use pydantic when you’re not in control of the data input.
Fast and extensible, Pydantic plays nicely with your linters/IDE/brain. Define how data should be in pure, canonical Python 3.8+; validate it with Pydantic. Its success means it suffers from feature creep. There’s a temptation to move other classes over to pydantic, just because pydantic also includes serialization.
It leans heavily on use of type hinting, which makes custom validation more complex than perhaps necessary.
So check if you can get away with dataclasses.
Use Python Code Scans
mypy
Static Application Security Testing (SAST) looks for weaknesses in code and vulnerable packages.
Dynamic Application Security Testing (DAST) looks for vulnerabilities that occur at runtime.
https://www.statworx.com/en/content-hub/blog/how-to-scan-your-code-and-dependencies-in-python/
A. PEP8 “lints” program code for violations of the PIP.
Other formaters: blake, ruff.
B. Bandit (open-sourced at https://github.com/PyCQA/bandit) scans python code for vulnerabilities. It decomposes the code into its abstract syntax tree and runs plugins against it to check for known weaknesses. Among other tests it performs checks on plain SQL code, which could provide an opening for SQL injections, passwords stored in code and hints about common openings for attacks such as use of the pickle library. Bandit is designed for use with CI/CD:
bandit -c bandit_yml.cfg /path/to/python/files
The bandit_yml.cfg configuration file contains YAML lines such as this to specify types of assertion to skip.
# bandit_cfg.yml
skips: ["B101"] # skips the assert check
Bandit throws an exit status of 1 whenever it encounters any issues, thus terminating the pipeline.
The report it generates include the number of issues separated by confidence and severity according to three levels: low, medium, and high.
C. safety checks for dependencies containing vulnerabilities (CVEs) identified.
https://pypi.org/project/scancode-toolkit/
D. Scancode ScanCode scans Python code for license, copyright, package and their documented dependencies and other interesting facts.
E. GitHub’s Advanced Security scans Python code based on CodeQL logic specifications.
https://7451111251303.gumroad.com/l/wotve
Time Complexity Big Oh notation
There is time complexity, data complexity, etc.
See https://readmex.com/TheAlgorithms/Python
Big-O notation summarizes Time Complexity analysis, which estimates how long it can take for an algorithm to complete based on its structure. That’s worst-case, before optimizations such as memoization.
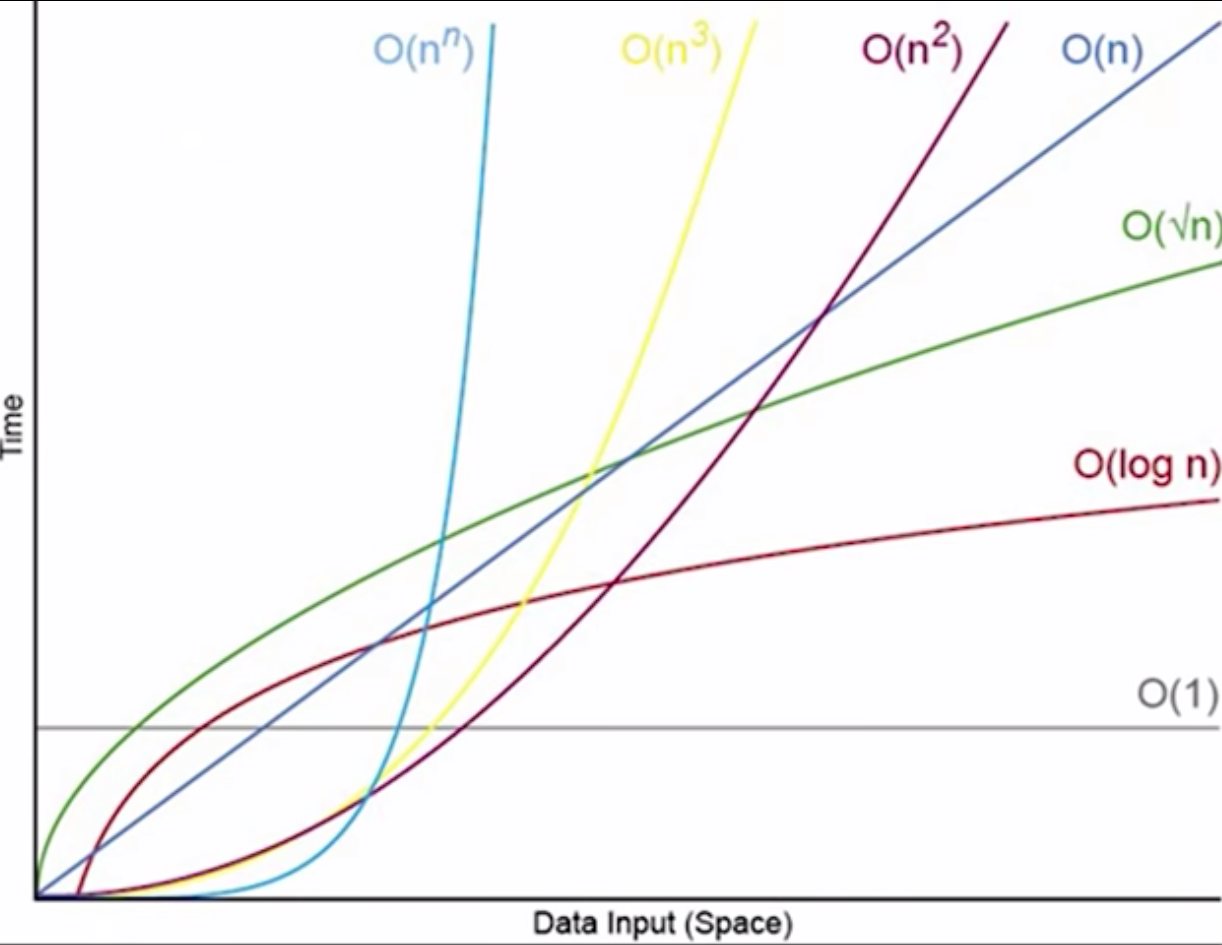
From https://bigocheatsheet.com, in the list of Big O values for sorting:
BigO References: VIDEO
- VIDEO Cheet Sheat & bootcamp from ZeroToMastery.io</a> Python Solutions:
- https://www.youtube.com/watch?v=x2CRZaN2xgM by ByteByteGo (the best)
- https://github.com/theja-m/Data-Structures-and-Algorithms
- https://github.com/VicodinAbuser/ZTM-DS-and-Algo-Python
- https://www.youtube.com/watch?v=v4cd1O4zkGw by HackerRank - rules
- https://www.youtube.com/watch?v=V6mKVRU1evU
- https://www.youtube.com/watch?v=zUUkiEllHG0
- https://www.youtube.com/watch?v=oJ5s2hs_cKk
- https://www.youtube.com/watch?v=itn09C2ZB9Y
- https://www.youtube.com/watch?v=jUy5N-3RAjo
- https://www.youtube.com/watch?v=kS_gr2_-ws8
- https://www.youtube.com/watch?v=QnRx6V8YQy0
-
https://www.youtube.com/watch?v=tNrNLoCqzco
- https://www.youtube.com/watch?v=TWIlXV1z3gk combinations of 77 items (asymptope) to put in backpack based on weight - genetic algorithm with mutation.
- https://www.youtube.com/watch?v=nhT56blfRpE Python code for genetic algorithm & https://www.youtube.com/watch?v=4XZoVQOt-0I
- https://www.youtube.com/watch?v=aOsET8KapQQ gen music with human rating
Let’s go from the most efficient (at the bottom-right) to the least efficient at the upper-left, where n is the number of input items in the list being processed:
-
O(1) or n0 is constant run time as more data (n) is processed. This happens when a lookup is done rather than calculating. Examples are the push, pop, lookup of an array; insert or remove a hash map/set.
Use of “memoization” is ideal, but is typically not possible for some algorithms.
0Use of Modulus would result in “O(n)” (linear) growth in time to run as the dataset grows.
- O(n) or (n1) linear time occurs the increase in list size (n) increases the number of steps in direct proportion to the input size. VIDEO: This happens when
- values within an array are summed together, in a nested loop through all elements.
- during an exhaustive search though every item. ``` nums = [1,2,3] sum(nums) # sum the array print(100 in nums) # search nums.insert(1, 100) # insert in the middle nums.remove(100) # remove from the middle
import heapq heapq.heapify(nums) # to build heap
# nested loop (monotonic stack or sliding window) ```
- O(log n) or log2n - logarithmic time VIDEO: occurs during binary search, (like ripping up portions of a phone book) where steps increase at a slower rate than input list size:
| List | Steps | | 1 | 1 | | 10 | 4 | | 100 | 7 | | 1000 | 10 | | .... | 35 | horizontal asymtope - O(n2) - n squared quadratic time VIDEO: occurs in a nested loop when steps increase in proportion to the input size squared (to the power of 2). A selection sort starts from the front of the list, and looks at each unordered item to find the next smallest value in the list and swapping it with the current value. This is also when the minimax algorithm is used.
| List | Steps | | 1 | 1 | | 10 | 45 | | 100 | 4950 | | 1000 | 499500 |The standard form, When graphed, a quadratic equation forms a parabola - a U-shaped curve used to illustrate trajectories of moving objects, areas of shapes, and in financial calculations. 𝑎𝑥2 + 𝑏𝑥 + 𝑐 = 0
-
nk - such as n3 and higher degree polynomials are called “Polynomial time” to group run times which do not increase faster than nk.
-
“Superpolynomial time” describes any run time that increase faster than nk, below:
-
O(nn) - exponential time occurs when a algorithm looks at every permutation of values, such as all possible value which brute-force guessing passwords. For example, 28 to the power of 8 is when guessing 8 positions of 28 alphanumatic characters. When 10 number values and special characters are added for 98 possible values, it’s 98 to the power of 8, a very large number. Such are considered “unreasonable” to make it harder to brute-force guess.
-
O(n!) factorial time VIDEO: where 5! = 5x4x3x2x1 - the product of all positive integers less than or equal to n. Factorials are used to represent permutations and combinations. Factorials determine the number of possible topping combinations - graph problems such as the “Traveling Salesman”.
Used to purposely create complex calculations, such as for encryption.
The asymptope is when a number reaches an extremely large number that is essentially infinite.
Depth-first trees would have steeper (logarithmic) Time Complexity.
References:
- KhanAcad explanation of run-time efficiency.
- https://www.youtube.com/watch?v=7VHG6Y2QmtM
GitHub repos with the highest stars:
- https://github.com/joeyajames/Python with YouTube explanations
- https://github.com/TheAlgorithms/Python
- https://github.com/geekcomputers/Python
- https://github.com/Show-Me-the-Code/python
- https://github.com/flypythoncom/python
Faster routes to machine code
By default, Python comes with the CPython interpreter (command cythonize) to generate machine-code. When speed is needed, such as in loops, custom C/C++ extensions are created. Additional speed is obtained by adding before nested loop code directives and decorators:
# cython: language_level=3, boundscheck=False, wraparound=False
import cython
@cython.locals(i=cython.int,j=cython.int,a=list[cython.int],b=list[cython.int])
VIDEO: benchmarks Numba, mypyc, Taichi (the fastest). Alternately, code compiled using Codon by Exaloop tool “41,212 times faster” than the standard Python interpreter.
Condon is a new python compiler that uses the LLVM framework to compile directly to machine code. Condon can also make use of the thousands of processors on a GPU to process matrix, graphical, and mathematical operations without using a library like numpy, scikit-learn, scipy, and game library pygame. However, Conda cannot use modules like typing functools such as wraps, which provides contextual information for decorators.
Lexis
From https://learning.oreilly.com/library/view/python-in-a/0596100469/ch04s01.html
The syntax of the Python programming language is the set of rules that defines how a Python program will be written and interpreted (by both the runtime system and by human readers). The Python language has many similarities to Perl, C, and Java. However, there are some definite differences between the languages. It supports multiple programming paradigms, including structured, object-oriented programming, and functional programming, and boasts a dynamic type system and automatic memory management.
Python’s syntax is simple and consistent, adhering to the principle that “There should be one— and preferably only one —obvious way to do it.” The language incorporates built-in data types and structures, control flow mechanisms, first-class functions, and modules for better code reusability and organization. Python also uses English keywords where other languages use punctuation, contributing to its uncluttered visual layout.
The language provides robust error handling through exceptions, and includes a debugger in the standard library for efficient problem-solving.
Python’s syntax, designed for readability and ease of use, makes it a popular choice among beginners and professionals alike.
Reserved Keywords
VIDEO: W: Here are the keywords Python has reserved for itself, so they can’t be used as custom identifiers (variables).
- _ (soft keyword)
- and
- as
- assert
- async
- await
- break - force escape from for/while loop
- case (soft keyword)
- class
- continue - force loop again next iteration
- def - define a custom function
- del - del list1[2] # delete 3rd list item, starting from 0.
- elif - else if
- else
- except
- False - boolean
- finally - of a try
- for = iterate through a loop
- from
- global = defines a variable global in scope
- if
- import = make the specified package available
- in
- is
- lambda - if/then/else in one line
- match (soft keyword)
- None - absence of value.
- nonlocal
- not
- or
- pass - (as in the game Bridge) instruction to do nothing (instead of return or yield with value)
- raise - raise NotImplementedError() throws an exception purposely
- return
- True - Boolean
- try - VIDEO
- while
- with
- yield - resumes after returning a value back to the caller to produce a series of values over time.
NOTE: match, case and _ were introduced as keywords in Python 3.10.
The list above can be retrieved (as an array) by this code after typing python for the REPL (Read Evaluate Print Loop) interactive prompt:
from keyword import kwlist, softkwlist
def display_keywords() -> None: 1usage
print('Keywords:') # not alphabetically
for i, kw in enumerage(kwlist, start=1):
print(f'{i:2}: {kw})
print('Software keywords')
for i, skw in enumerate(softwlist, start=1):
print(f'{i:2}: {skw}')
def main() -> None: 1usage
display_keywords()
if __name__ == '__main__':
main()
Soft keywords:
- _ (magic)
- cate
- match
- type (added by Python 3.12)
Press control+D to exit anytime.
Built-in Methods/Functions
WARNING: Do not create custom functions with these function names reserved for use only by the Python interpreter.
Know what they do. See https://docs.python.org/3/library/functions.html
- abs() = return absolute value
- any()
- all()
- ascii()
- bin()
- bool() = convert to boolean data type
- bytearray()
- callable()
- bytes()
- chr()
- compile()
- classmethod()
- complex()
- delattr()
- dict()
- dir()
- divmod()
- enumerate()
- staticmethod()
- filter()
- eval() = dynamically execute code
- float() = convert to floating point data type
- format()
- frozenset()
- getattr() = get attribute
- globals()
- exec()
- hasattr()
- help()
- hex() = hexadecimal counting
- hash()
- input() from human user
- id()
- isinstance() - checks if the object (first argument) is an instance or subclass of classinfo class (second argument). True/False
- int() = integer
- issubclass()
- iter()
- list() = function
- locals()
- len([1, 2, 3]) is 3.
- max() = maximum value
- min() = minimum value
- map()
- next()
-
memoryview()
- object()
- oct() = octa (8) counting
- ord()
- open()
- pow()
- print() = output to CLI terminal
-
property()
- range()
- repr()
- reversed()
-
round()
- set()
- setattr()
- slice() - extract substring
- sorted()
- str() = convert to string data type
-
sum()
- tuple() Function
- type() = display the type
- vars()
- zip() = combine two interable arrays
- import()
- super()
import
REMEMBER: import statements are at the top of code files.
DEFINITION: A built-in library (such as argparse, os, sys, random, etc.) is intrinsically contained in the interpreter, so is loaded with use of “pip”.
The Python import statement specifies each library which contains additional functions that our custom program wants to use.
DEFINITION:
- A library is a collection of functions that are grouped together.
- A built-in library (such as argparse, os, sys, random, etc.) the Python interpreter can load.
- A third-party package is one that is not built into Python. An example is import google.auth.
REMEMBER: When a is specified in an import statement, an error occurs if that package was not installed with a CLI pip command such as:
pip install google-auth
- DEFINITION: pip is a recursive acronym that stands for either "Pip Installs Packages" or "Pip Installs Python".
Many put a list of external packages in a requirements.txt file so that a single CLI command can be used to install all packages listed in a requirements.txt file:
pip install -r requirements.txt
By default, pip pulls external packages from its GitHub repository such as
https://pypi.org/project/google-auth/
To install a wheel defined in a GitHub repository:
pip install https://github.com/user_account/repository.whl
Each wheel folder contains pre-compiled Python packages contains a pyproject.toml if using modern packaging tools. Also, setup.py file should include all metadata and dependencies for the package. That’s after pip is installed with setuptools and wheel utility packages:
python -m pip install --upgrade pip setuptools wheel
The wheel is built in the dist folder using this command:
python -m pip wheel --no-deps -w dist .
Docs about pip wheel are at https://pip.pypa.io/en/stable/cli/pip_wheel/
To validate a wheel:
pip install check-wheel-contents
check-wheel-contents dist/
import custom utility library myutils.py
I grew tired of copying various custom utility functions I like to add to programs I write because when a change is made, I would have to update each file that uses it.
So I want to have all my custom programs reference my custom utility functions in a file called “myutils.py”. Such functions include:
- print_timestamp()
- print_info() to display information the function generated.
- print_debug() to display information that affects program logic.
- print_error() to display also alert the user of an error.
- print_warning() when a trigger is met to send a security alert to the operations team.
- etc.
pip pulls external packages from specified GitHub repository using the following CLI command format:
pip install git+https://github.com/user_account/repository.git
QUESTION: If you want to reference the many utility functions Hari Sekhon has created, use the CLI command:
pip install git+https://github.com/HariSekhon/pylib.git
Sample code to import Hari Sekhon’s utility functions from https://github.com/HariSekhon/pylib/blob/master/harisekhon/utils.py
try:
# pylint: disable=wrong-import-position
from harisekhon.utils import log, die
from harisekhon.utils import validate_host, validate_port, validate_regex
from harisekhon import CLI
except ImportError as _:
print(traceback.format_exc(), end='')
sys.exit(4)
QUESTION: How to import Hari Sekhon’s utility functions “using make”?
BEST PRACTICE: To reduce the memory your program uses, specify the specific functions you need from a library rather than letting the interpreter load all the functions in the library. For example, if your program only uses the log and die functions:
from harisekhon.utils import log, die
“myutils.py” must be in the same directory as the script.
REMEMBER: The Python import statement is not evaluated until the code is run.
The first thing that most tutorials cover is this:
print, printf, echo
PROTIP: Don’t just print out the value. Include the variable name, such as:
print("=== var1=",var1)
While Loop
CAUTION: What’s wrong with this sample code?
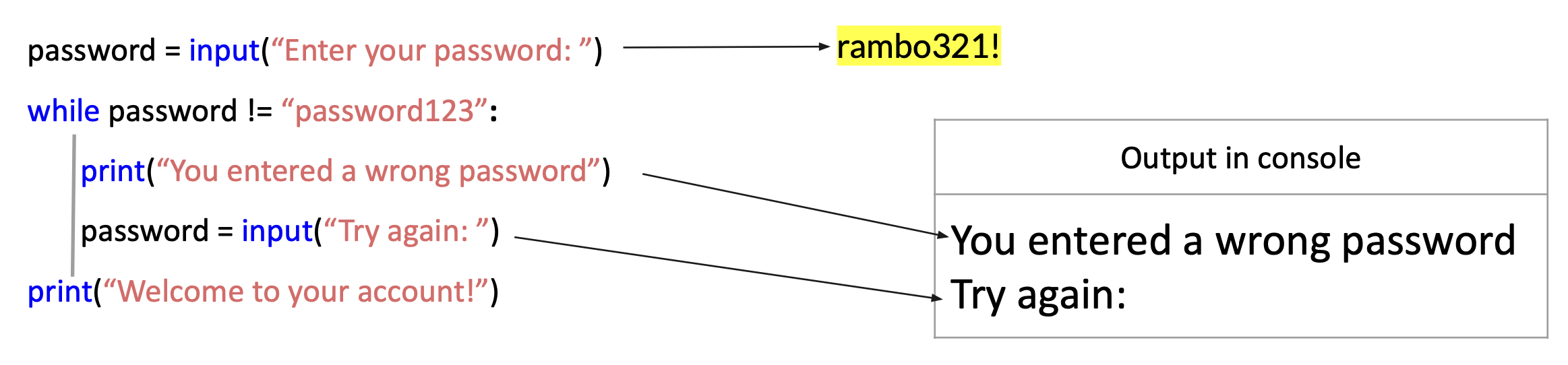
PROTIP: Passwords and other secrets should not be requested in an input() prompt because that would expose the passwords in CLI logs.
PROTIP: Passwords and other secrets should not be stored in programming code.
PROTIP: The way to verify passwords is not to store them as the raw password which the user typed in but as a hash of what the password the user typed in. The hash would also be created with a “salt” to ensure randomness. To verify whether the user provides the correct password, the program would add the salt to calculate the hash the user provides, then compare the two.
PROTIP: The user should be provided with a set limited number of tries. When exceeded, the user and IP address used should be locked out, entered in central (SIEM) security logs, and reported as a Security incident.
Magic underlines
VIDEO from idently.co: Underlines in numbers are ignored by Python:
n: int = 1_000_000_000
Specify command separator:
num: float = 1_000_000_000.342
print(f'{num:_.3f}')
Right-align 20 spaces:
print(f'{var:>20}')
Center align within 20 | characters with the cap character:
print(f'{var:|^0}:')
The : character at the end of the string is a pass-through.
A colon after a variable begins a formatting specification:
from datetime import datetime
now: datetime = datetime.now()
print(f'{now:%d.%m.%y(%H:%M:%D)})
Function return Not None
Returning 0 on error can be confused with the number 0 as a valid response.
So to avoid the confusion, return the Python reserved word “None”:
result = safe_square_root(4)
<strong>if result is not None:</strong> # happy path:
value = result.pop() # pop up from stack.
print(value)
else: # notice we're not checking for None.
# calling function does not need to handle error:
# an error occurred, but encapsulated to be forwarded and processed upstream:
print("unable to compute square root")
Function:
def safe_square_root(x):
try:
return [math.sqrt(x)] # in a stack.
except ValueError:
return None # using reserved word.
The parameter (x) is what is declared going into the function.
The value passed through when calling the function is called an argument.
Operators
DEFINITION: Walrun operator :=
Floor division Operators
This feature was added in Python 3.
11 // 5 uses “floor division” to return just the integer (integral part) of 2, discarding the remainder. This can be useful to efficiently solve the “Prefix Sums CountDiv” coding interview challenge: “Write a function … that, given three integers A, B and K, returns the number of integers within the range [A..B] that are divisible by K”:
def solution(a, b, k):
return 0 if b == 0 else int(b // k - (a - 1) // k)
Instead of a “brute force” approach which has linear time complexity — O(n), the solution using floor division is constant time - O(1).
Modulo operator
11 % 5 uses the (percent sign), the modulo operator to divide 11 by the quotient 5 in order to return 1 because two 5s can go into 11, leaving 1 left over, the remainder. Modulus is used in circular buffers and hashing algorithms.
def solution(A, K):
# A is the array.
# K is the increment to move.
result = [None] * len(A) # initialize result array for # items in array
for i in range(len(A)):
# Use % modulo operator to calculate new index position 0 - 9:
result[(i + K) % len(A)] = A[i]
print(f'i={i} A[i]={A[i]} K={K} result={result} ')
return result
print(solution([7, 2, 8, 3, 5], 2))
Modulu is also used in this
What Day and Time is it?
The ISO 8601 format contains 6-digit microseconds (“123456”) and a Time Zone offset (“-5.00” being five hours West of UTC):
- 2025-12-22T07:53:19.123456-05:00
# import datetime
start = datetime.datetime.now()
# do some stuff ...
end = datetime.datetime.now()
elapsed = end - start
print(elapsed)
# or
print(elapsed.seconds,":",elapsed.microseconds)
Some prefer to display local time with a Time Zone code from Python package pytz or zulu.
PROTIP: Servers within enterprises and military run in UTC time and Logs should be output in UTC time rather than local time,
- 2024-02-22T12:53:19.123456
datetime.datetime.now() provides microsecond precision:
References:
- https://www.geeksforgeeks.org/get-current-time-in-different-timezone-using-python/
Timezone handling
During Debian OS 12 install from iso file, a time zone is requested to be manually selected. After boot-up:
- Check the current timezone with bash timedatectl
- Set the timezone to UTC with bash sudo timedatectl set-timezone Etc/UTC Alternately, reconfigure the timezone data with bash sudo dpkg-reconfigure tzdata then select “None of the above” from the Continents list, then select “UTC” from the second list: Follow the prompts to navigate through the menus and select Etc or None of the above, then choose UTC.
NOTE: On macOS, timezone data are in a binary file at /etc/localtime.
Within Python, there are several ways to detect time zone:
from dateutil import tz
local_timezone = tz.tzlocal()
print("dateutil local_timezone=",local_timezone)
Use the dateutil library to read /etc/localtime and get the timezone-aware datetime object:
from datetime import datetime
local_now = datetime.now().astimezone()
local_timezone = local_now.tzinfo
print("zoneinfo local_timezone=",local_timezone)
from zoneinfo import ZoneInfo
from datetime import datetime
local_timezone = datetime.now(ZoneInfo("localtime")).tzinfo
print("zoneinfo local_timezone=",local_timezone)
Use the tzlocal library to obtain the IANA time zone name (e.g., ‘America/New_York’). But it varies across operating systems.
import tzlocal
local_timezone = tzlocal.get_localzone_name()
print("tzlocal local_timezone=",local_timezone)
Once a datetime has a tzinfo, the astimezone() strategy supplants new tzinfo
# astimezone() defaults to the local time zone when no argument is provided.
from datetime import datetime
local_now = datetime.now().astimezone()
local_timezone = local_now.tzinfo
print("astimezone local_timezone=",local_timezone)
Timing Attacks
A malicious use of precise microseconds timing code is used by Timing Attacks based on the time it takes for an application to authenticate a password to determine the algorithm used to process the password. In the case of Keyczar vulnerability found by Nate Lawson, a simple break-on-inequality algorithm was used to compare a candidate HMAC digest with the calculated digest. A value which shares no bytes in common with the secret digest returns immediately; a value which shares the first 15 bytes will return 15 compares later.
Similarly, PDF: entropy

PROTIP: Use the secrets.compare_digest module (introduced in Python 3.5) to check passwords and other private values. It uses a constant amount of time to process every request.
Functions hmac.compare_digest() and secrets.compare_digest() are designed to mitigate against timing attacks.
http://pypi.python.org/pypi/profilehooks
REMEMBER: Depth-First Seach (DFS) uses a stack, whereas Breadth-First Search (BFS) use a queue.
VIDEO: The Sliding Window
VIDEO: FullStack’s REACTO framework during coding interviews:
- Repeat the question
- Examples
- Approach
- Code
- Test
- Optimization
Run Duration calculations
Several packages, functions, and methods are available. They differ by:
- the type of duration they report: wall-clock time or CPU time
- how they treat time zone changes during the recording period
-
how much precision they report (down to microseconds)
-
Wall-clock time (aka clock time or wall time) is the total time elapsed you can measure with a stopwatch. It is the difference between the time at which a program finished its execution and the time at which the program started. It includes waiting time for resources.
- CPU Time is how much time the CPU was busy processing programming instructions, not including time waiting for other task to complete (like I/O operations).
We want both reported.
timeit.default_timer() is time.perf_counter() on Python 3.3+.
The same program run several times would report similar CPU time but varying wall-clock times due to differences in what else was taking up resources during the runs.
- time.time() returns wall-clock time.
- time.process_time() returns CPU execution time.
To time the difference between calculation strategies, new since Python 3.7 is PEP 564.
time.perf_counter() (abbreviation of performance counter) measures the elapsed time of short duration because it returns 82 nano-second resolution on Fedora 4.12. It is based on Wall-Clock Time which includes time elapsed during sleep and is system-wide. The reference point of the returned value is undefined, so that only the difference between the results of consecutive calls is valid. See https://docs.python.org/3/library/time.html#time.perf_counter
time.clock is no longer available since Python 3.8.
time.time() has a resolution of whole seconds. And in a measurement period between start and stop times, if the system time is disrupted (such as for daylight savings) its counting is disrupted. time.time() resolution will only become larger (worse) as years pass since every day adds 86,400,000,000,000 nanoseconds to the system clock, which increases the precision loss. It is called “non-monotonic” because falling back on daylight savings would cause it to report time going backwards:
start_time = time.time()
# your code
e = time.time() - start_time
time.strftime("%H:%M:%S", time.gmtime(e)) # for hours:minutes:seconds
print('{:02d}:{:02d}:{:02d}'.format(e // 3600, (e % 3600 // 60), e % 60))
timeit()
For more accurate wall-time capture, the timeit() functions disable the garbage collector.
timeit.timer() provides a nice output format of 0:00:01.946339 for almost 2 seconds.
- https://pynative.com/python-get-execution-time-of-program/
- https://docs.python.org/3/library/timeit.html
- https://www.guru99.com/timeit-python-examples.html
import timeit # built-in
# print addition of first 1 million numbers
def addition():
print('Addition:', sum(range(1000000)))
# run same code 5 times to get measurable data
n = 5
# calculate total execution time
result = timeit.timeit(stmt='addition()', globals=globals(), number=n)
# calculate the execution time
# get the average execution time
print(f"Execution time is {result / n} seconds")
timeit.timeit(stmt='pass', setup='pass', timer=<default timer>, number=1000000, globals=None)
# from timeit import default_timer as timer # from datetime import timedelta start = timer() # do some stuff ... end = timer() print(timedelta(seconds=end-start))
PEP-418 in Python 3.3 added three timers:
time.process_time() offers 1 nano-second resolution on Linux 4.12. It does not include time during sleep.
# import time t = time.process_time() # do some stuff ... elapsed_time = time.process_time() - t
time.monotonic() is used for measurements on the order of hours/days, when you don’t care about sub-second resolution. It has 81 ns resolution on Fedora 4.12. BTW “monotonic” = only goes forward. See https://docs.python.org/3/library/time.html#time.monotonic
References:
- https://stackoverflow.com/questions/7370801/how-to-measure-elapsed-time-in-python
- https://stackoverflow.com/questions/3620943/measuring-elapsed-time-with-the-time-module/47637891#47637891
- See https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes
- See https://www.codingeek.com/tutorials/python/datetime-strftime/
- use the .st_birthtime attribute of the result of a call to os.stat().
- Obtain pgm start to obtain run duration at end:
- See https://www.webucator.com/article/python-clocks-explained/
- for wall-clock time (includes any sleep).
Pickle objects
Pickling is the process of converting (serializing) a (especially complex) Python object (list, dict, set, tuple, matrix) into a byte stream used to transfer to another object, over the internet, or store in a database.
- dump writes result to a file
-
load objects from a file
- dumps in-memory object to a file
- loads from file to in-memory objects
https://www.youtube.com/watch?v=wO_gVvINtg0
minmax
The difference between API, Library, Package, Module, Script, Frameworks.
A library contains several modules which are separated by its use.
http://docs.python.org/3/reference/import.html
A module is a bunch of related code saved in a file with the extension .py. Code in a module can be functions, classes, or variables.
The most popular imports include system, time, random, datetime, argparse, re (regular expressions), math, xarray, polars (for computation), seaborn (charts with themes) on top of matplatlib, pytorch, pygame, result (exception handling), pydantic (data validation), missingno, sqlmodel (ORM fastapi), beautifulsoup, python-dotenv (key value pairs in environment variables).
Packages can also contain modules and other packages (subpackages).
Packages structure Python’s module namespace by using “dotted module names”.
The ___ VScode extension squences and reformats import statements to save memory. If the program only needs a single function, only that would be imported in.
Django, Flask, Bottle are frameworks - that provide the basic flow and architecture of the application.
def celsius_to_fahrenheit(celsius):
return (celsius * 9/5) + 32
try:
celsius = float(input("Enter temperature in Celsius: "))
fahrenheit = celsius_to_fahrenheit(celsius)
print(f"{celsius}°C is equal to {fahrenheit:.2f}°F")
f"{fahrenheit:.2f}"
round(fahrenheit, 2)
except ValueError:
print("Please enter a valid number for the temperature.")
Swapping
To swap values, here’s a straight-forward function:
def swap1(var1,var2):
var1,var2 = var2,var1
return var1, var2
>>> swap1(10,20) >>> 2 1
def swap2(x,y):
x = x ^ y
y = x ^ y
x = x ^ y
return x, y
>>> swap2(10,20) (20,10)
Sorting
Challenges:
Implement Binary Search and Quick Sort
Reduce Space Complexity with Dynamic programming
Techniques for calculation of nested loops is often used to shown how to reduce run times by using techniques that use more memory space. Rather than “brute-force” repeatitive computations as in the definition of how to calculate Fibonacci numbers, which by definition is based on numbers preceding it.
fib(5) = fib(4) + fib(3)
Fibonacci has the highest BigO because it uses recursive execution with Python generators. VIDEO
Memoization (sounds like memorization) is the technique of writing a function that remembers the results of previous computations.
Longest Increasing Subsequence (LIS)
That’s a technique of “Dynamic Programming” (See https://www.wikiwand.com/en/Dynamic_programming)
Dynamic programming is a catch phrase for solutions based on solving successively similar but smaller problems, using algorithmic tasks in which the solution of a bigger problem is relatively easy to find, if we have solutions for its sub-problems.
Avoid divide by zero errors
Use this in every division to ensure that a zero denominator results in falling into “else 0” rather than a “ZeroDivisionError” at run-time:
def weird_division(n, d):
# n=numerator, d=denominator.
return n / d if d else 0
Random
Flip a coin:
import random
if random.randint(0, 1) == 0:
print("heads!")
else:
print("tails!")
TODO: Roll a 6-sided die? See bomonike/memon
TODO: Roll a 20-sided die?
Environment Variable Cleansing
To read a file named “.env” at the $HOME folder, and obtain the value from “MY_EMAIL”:
import os
env_vars = !cat ~/.env
for var in env_vars:
key, value = var.split('=')
os.environ[key] = value
print(os.environ.get('MY_EMAIL')) # containing "johndoe@gmail.com"
This code is important because it keeps secrets in your $HOME folder, away from folders that get pushed up to GitHub.
There is the “load_dotenv” package that can do the above, but using native commands mean less exposure to potential attacks.
Remember that attackers can use directory traversal sequences (../) to fetch the sensitive files from the server.
Sanitize the user input using “shlex”
Object-oriented class functions
To use .maketrans() an d .translate()
- a.find(‘a’) returns the index where ‘a’ is found.
BTW not everyone is enamored with Object-Oriented Programming (OOP). Yegor Bugayenko in Russia recorded “The Pain of OOP” lectures “Algorithms hurt object thinking” May 2023 and #2 Static methods and attributes are evil, a repeat of his 11 March 2020: #1: Algorithms and Lecture #2: Static methods and attributes are evil. His 2016 ElegantObjects.org presents an object-oriented programming paradigm that “renounces traditional techniques like null, getters-and-setters, code in constructors, mutable objects, static methods, annotations, type casting, implementation inheritance, data objects, etc.”
Blob vs. File vs. Text
A “BLOB” (Binary Large OBject) is a data type that stores binary data such as mp4 videos, mp3 audio, pictures, pdf. So usually large – up to 2 TB (2,147,483,647 characters).
https://github.com/googleapis/google-cloud-python/issues/1216
https://towardsdatascience.com/image-processing-blob-detection-204dc6428dd
GUI
https://docs.python.org/3/using/ios.html
Not many develop iOS and iPad apps using Python vs. coding Swift, which is similar to Python. Learning Swift to develop an iOS application would be easier than figuring out how to develop an iOS application in Python.
But if you are hell-bent on it:
- Pythonista
- wxWidgets
- Kivy
- ReactNative JavaScript
- Xamarin (Microsoft) coding in C#, etc.
- beeware.org framework
-
VIDEO: Qt for cross-platform development in Python over C++. Nokia owned Qt and developed PySide for Python bindings. PySide2 arrived later than Riverbank’s PyQt5 under GPL (buy license to keep code close source).
PySide6 and PyQt5 released about the same time.
PySide6 is under LGPL with no sharing. In PySide6, every widget is part of two distinct hierarchies:
- the Python object hierarchy and
- the Qt layout hierarchy. How you respond or ignore events can affect how your UI behaves.
VIDEO: Qt Media player
create-gui-applications-pyside6.epub
https://github.com/mfitzp/books/tree/main/create-gui-applications/pyside6
More advanced developers integrate Python directly into an iOS project using a Python XCFramework.
Cloud
Azure storage
https://github.com/yokawasa/azure-functions-python-samples
https://chriskingdon.com/2020/11/24/the-definitive-guide-to-azure-functions-in-python-part-1/
https://chriskingdon.com/2020/11/30/the-definitive-guide-to-azure-functions-in-python-part-2-unit-testing/
https://github.com/Azure/azure-storage-python/blob/master/tests/blob/test_blob_storage_account.py
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-quickstart-blobs-python
Azure Blobs
NOTE: Update of azure-storage-blob deprecates blockblobservice.
VIDEO: https://pypi.org/project/azure-storage-blob/
https://www.educative.io/edpresso/how-to-download-files-from-azure-blob-storage-using-python
https://github.com/Azure/azure-sdk-for-python/issues/12744 exists() new feature
import asyncio
async def check():
from azure.storage.blob.aio import BlobClient
blob = BlobClient.from_connection_string(conn_str="my_connection_string", container_name="mycontainer", blob_name="myblob")
async with blob:
exists = await blob.exists()
print(exists)
Azure Streams
https://blog.siliconvalve.com/2020/10/29/reading-and-writing-binary-files-with-python-with-azure-functions-input-and-output-bindings/ Reading and writing binary files with Python with Azure Functions input and output bindings
Web Scraper
Beautiful Soup
Movie Recommender
A popular project is to combine from Kagle a historical database of movies and TV shows from several streaming sites:
- Disney+
- Netflix
- Hulu
- Amazon Prime
https://github.com/dataquestio/project-walkthroughs/blob/master/movie_recs/movie_recommendations.ipynb https://files.grouplens.org/datasets/movielens/ml-25m.zip
My rudimentry show-recommendations.py makes recommendations based on identifying atrributes of a single movie and showing others with the same attributes. https://www.youtube.com/watch?v=eyEabQRBMQA
It uses imports numpy and pandas for data handling.
Another advancement is to use the SurPRISE library (https://surpriselib.com/), named from the acronym Simple Python RecommendatIon System Engine. VIDEO
surprise -h
A module that was compiled using NumPy 1.x cannot be run in NumPy 2.0.0 as it may crash. To support both 1.x and 2.x versions of NumPy, modules must be compiled with NumPy 2.0. Some module may need to rebuild instead e.g. with ‘pybind11>=2.12’.
If you are a user of the module, the easiest solution will be to downgrade to ‘numpy<2’ or try to upgrade the affected module. We expect that some modules will need time to support NumPy 2.
An advancement is Movielens (https://grouplens.org/datasets/movielens/) https://grouplens.org/datasets/movielens/ The load_builtin() method will offer to download the movielens-100k dataset if it has not already been downloaded, and it will save it in the .surprise_data folder in your home directory (you can also choose to save it somewhere else).
Surprise is a “scikit” (https://projects.scipy.org/scikits.html) which enables you to build your own cross-validation recommendation algorithm as well as use ready-to-use prediction algorithms such as:
- baseline algorithms,
- neighborhood methods,
- similarity measures (cosine,
Matrix factorization-based algorithms are used for collaborative filtering within recommender systems. The algorithms aim decompose a large user-item interaction matrix into smaller matrices that capture latent factors. The four common matrix factorization algorithms are SVD, PMF, SVD++, NMF:
SVD (Singular Value Decomposition) decomposes the user-item matrix into three lower-dimensional matrices:
- U to represent user factors
- V^T to represent item factors
- Σ to contain singular values
When applied to collaborative filtering, SVD aims to minimize the sum of squared errors between predicted and actual ratings for observed entries in the rating matrix.
QUESTION: The prediction for a user-item pair is calculated as: r̂ui = μ + bu + bi + qi^T * pu Where μ is the overall mean rating, bu and bi are user and item biases, and qi and pu are item and user factor vectors.
SVD++ extends SVD to incorporate both implicit and explicit ratings and implicit feedback (e.g., which items a user has rated). The prediction formula for SVD++ is:
| r̂ui = μ + bu + bi + qi^T * (pu + | N(u) | ^(-1/2) * Σj∈N(u)yj) Where N(u) represents the set of items rated by user u, and yj are item factors that capture implicit feedback. |
PMF (Probabilistic Matrix Factorization) is a model-based technique that assumes ratings are generated from a Gaussian (normal) distribution. So it factorizes the user-item matrix R into two lower-dimensional matrices: U (user factors) and V (item factors). PMF is particularly effective for large, sparse datasets and scales linearly with the number of observations.
NMF (Non-negative Matrix Factorization) factorizes a non-negative matrix V into two non-negative matrices W and H
V ≈ W * H^T Where V is the user-item rating matrix, W represents user factors, and H represents item factors. The non-negativity constraint in NMF often leads to more interpretable and sparse decompositions compared to other techniques. Key advantages of NMF include:
Reduced prediction errors compared to techniques like SVD when non-negativity is imposed
Ability to work with compressed dimensional models, speeding up clustering and data organization Automatic extraction of sparse and significant features from non-negative data vectors
These matrix factorization algorithms have proven to be effective in capturing latent factors and similarities between users and items, making them powerful tools for building recommender systems. The choice of algorithm depends on the specific requirements of the application, such as dataset characteristics, computational resources, and desired interpretability of the results.
To evaluate the performance of regression models and recommender systemsusing Singular Value Decomposition (SVD):
Evaluating RMSE, MAE of algorithm SVD on 5 split(s).
Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Mean Std
RMSE 0.9311 0.9370 0.9320 0.9317 0.9391 0.9342 0.0032
MAE 0.7350 0.7375 0.7341 0.7342 0.7375 0.7357 0.0015
Fit time 6.53 7.11 7.23 7.15 3.99 6.40 1.23
Test time 0.26 0.26 0.25 0.15 0.13 0.21 0.06
Lower RMSE and MAE values indicate better predictive accuracy.
RMSE (Root Mean Square Error) is calculated as the square root of the average of squared differences between predicted and actual values. It gives higher weight to larger errors, making it more sensitive to outliers. The formula for RMSE is:
RMSE = √(Σ(predicted - actual)^2 / n)
MAE (Mean Absolute Error) is the average of the absolute differences between predicted and actual values. It treats all errors equally, regardless of their magnitude. The formula for MAE is:
| MAE = Σ | predicted - actual | / n |
RMSE is more sensitive to large errors, while MAE provides a more intuitive measure of average error magnitude.
GCP
https://gcloud.readthedocs.io/en/latest/storage-blobs.html
https://cloud.google.com/appengine/docs/standard/python/blobstore
OpenCV
 A mobile app that recognizes your hand pattern to play the Rock Paper Sissors plus Spock Lizard.
Use AI to guess what you will do next.
A mobile app that recognizes your hand pattern to play the Rock Paper Sissors plus Spock Lizard.
Use AI to guess what you will do next.
A macOS app that runs constantly to sound an alert if someone is looking over your shoulders.
https://learnopencv.com/blob-detection-using-opencv-python-c/
Scikit-Image
https://towardsdatascience.com/image-processing-with-python-blob-detection-using-scikit-image-5df9a8380ade
GIS
https://gsp.humboldt.edu/olm/Courses/GSP_318/11_B_91_Blob.html
String Handling
Regular Expressions
import re
- https://www.tutorialspoint.com/python/python_reg_expressions.htm
- https://www.udemy.com/course/python-quiz/learn/quiz/4649042#overview within quiz
Handle Strings safely
Python has four different ways to format strings.
Using f-strings to format (potentially malicious) user-supplied strings can be exploited:
from string import Template
greeting_template = Template("Hello World, my name is $name.")
greeting = greeting_template.substitute(name="Hayley")
So use a way that’s less flexible with types and doesn’t evaluate Python statements.
Data Types
0xa5 (two character bits) represents a hexdidecimal number
3.2e-12 expresses as a constant exponential value.
Largest Integer Value
2^63 - 1 is the largest integer value permitted by Python 2.
for a 64-bit address space. That’s not 2^64−1 because of the sign bit. Half of the values is negative and half is positive.
Practical analogy: Imagine 63 light switches. Each switch (bit) doubles the total possible combinations.
9,223,372,036,854,776,000 is the largest value in a 64-bit address space.
9,223,372,036,854,775,807.
~9 exabytes
But the limit was removed in Python 3. So there now is no explicitly defined limit. But the amount of available address space forms a practical limit depending on the machine Python runs on. Still 64 bit.
-
https://docs.python.org/3/tutorial/introduction.html#lists
Slicing strings
For flexibility with alternative languages such as Cyrillic (Russian) character set, return just the first 3 characters of a string:
letters = "abcdef" first_part = letters[:3]
Unicode Superscript & Subscript characters
# Specify Unicode characters:
# superscript
print("x\u00b2 + y\u00b2 = 2") # x² + y² = 2
# subscript
print(u'H\u2082SO\u2084') # H₂SO₄
Superscript
# super-sub-script.py converts to superscript:
def conv_superscript(x):
normal = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+-=()"
super_s = "ᴬᴮᶜᴰᴱᶠᴳᴴᴵᴶᴷᴸᴹᴺᴼᴾᴾᴿˢᵀᵁⱽᵂˣʸᶻᵃᵇᶜᵈᵉᶠᵍʰᶦʲᵏˡᵐⁿᵒᵖ۹ʳˢᵗᵘᵛʷˣʸᶻ⁰¹²³⁴⁵⁶⁷⁸⁹⁺⁻⁼⁽⁾"
res = x.maketrans(''.join(normal), ''.join(super_s))
return x.translate(res)
print(conv_superscript('Convert all this2'))
# Or you can simply copy the text
Internationalization & Localization (I18N & L18N)
- BLOG
- VIDEO: Internationalization and localization in Web Applications by James Cutajar
Internationalization, aka i18n for the 18 characters between i and n, is the process of adapting coding to support various linguistic and cultural settings:
- date and time zone calculations
- numbers and currency
- Pluralization
-
Install
pip install gettext
NOTE: pip is a recursive acronym that stands for either “Pip Installs Packages” or “Pip Installs Python”.
-
Create a folder for each locale in the ./locale folder.
-
Use Lokalise utility to manage translations through a GUI. It also has a CLI tool to automate the process of managing translations. https://lokalise.com/blog/lokalise-apiv2-in-practice/
locales/ ├── el │ └── LC_MESSAGES │ └── base.po └── en └── LC_MESSAGES └── base.po -
Add the library
import gettext # Set the local directory localedir = './locale' # Set up your magic function translate = gettext.translation('appname', localedir, fallback=True) _ = translate.gettext # Translate message print(_("Hello World"))See https://phrase.com/blog/posts/translate-python-gnu-gettext/
-
Store a master list of locales supported in a Portable Object Template (POT) file, also known as a translator:
#: src/main.py:12 msgid "Hello World" msgstr "Translation in different language">>> unicode_string = u"Fuu00dfbu00e4lle" >>> unicode_string Fußbälle >>> type(unicode_string) <type 'unicode'> >>> utf8_string = unicode_string.encode("utf-8") >>> utf8_string 'Fuxc3x9fbxc3xa4lle' >>> type(utf8_string) <type 'str'>
# ALTERNATIVE: TODO: http://babel.pocoo.org/en/latest/numbers.html
#from babel import numbers
# numbers.format_decimal(.2345, locale='en_US')
# Internationalization: http://babel.pocoo.org/en/latest/dates.html
# Requires: pip install Babel
# from babel import Locale
# NOTE: Babel generally recommends storing time in naive datetime, and treat them as UTC.
# from babel.dates import format_date, format_datetime, format_time
# d = date(2007, 4, 1)
# format_date(d, locale='en') # u'Apr 1, 2007'
# format_date(d, locale='de_DE') # u'01.04.2007'
Switch language in browsers
Ensure that your program works correctly when another human language (such as “es” for Spanish, “ko” for Korean, “de” for German, etc.) is configured by the user:
A. English was selected in browser’s Preferences, but the app displays another language.
B. Another language was selected in browser’s preferences, and the app displays that language.
To simulate selecting another language in the browser’s Preferences in Firefox:
FirefoxOptions options = new FirefoxOptions();
options.addPreference("intl.accept_languages", language);
driver = new FirefoxDriver(options);
Alternately, in Chrome:
HashMap<String, Object> chromePrefs = new HashMap<String, Object>();
chromePrefs.put("intl.accept_languages", language);
ChromeOptions options = new ChromeOptions();
options.setExperimentalOption("prefs", chromePrefs);
driver = new ChromeDriver(options);
Version management
-
To create a requirements.txt file containing the latest versions:
pip freeze > requirements.txt -
Identify whether CVEs have been filed against each module in requirements.txt:
sbom ???
If you’re writing a library that you intend to distribute and use in many places (or to be used by many people), the standard approach is to write a setup.py package manifest, and in the install_requires argument of setup() declare your dependencies. You should declare only direct dependencies, and declare the range of versions your library is compatible with.
If you’ve built something that you want to deploy, or otherwise reproduce as an environment somewhere else, the standard approach is to create a requirements file containing the full (direct and transitive) dependency tree, pinned to exact versions, with package hashes included. You can do this by writing a script that strings together several pip commands, or by using the pre-made “pip-compile” script from the pip-tools project.
This pyproject.toml file will work with modern versions of setuptools (61.0 and above). It replaces the need for a separate setup.py or setup.cfg file in many cases. However, if you need more complex build configurations or have custom build steps, you may still need to use a setup.py file alongside pyproject.toml.
Remember to adjust the content according to your specific project requirements. The pyproject.toml file is designed to be human-readable and writable, making it easier to manage your project’s metadata and build configuration.
PROTIP: I’ve found Poetry to be difficult to debug https://install.python-poetry.org:
brew install poetry
-
Verify:
poetry --versionExpected response like:
Poetry (version 1.8.3) -
Initialize to be prompted to create a pyproject.toml file:
poetry init -
Run based on the pyproject.toml
poetry add requests --no-interaction poetry update requests -
Run based on the pyproject.toml
poetry export -f requirements.txt --output requirements.txtInstead of
[build-system] requires = ["setuptools>=61.0"] build-backend = "setuptools.build_meta"
Excel handling using Dictionary object
Alternately, the Python library to work with Excel spreadsheets translates between Excel cell addresses (such as “A1”) and zero-based Python array tuple:
str = xl_rowcol_to_cell(0, 0, row_abs=True, col_abs=True) # $A$1
(row, col) = xl_cell_to_rowcol('A1') # (0, 0)
column = xl_col_to_name(1, True) # $B
However, if you want to avoid adding a dependency, this function defines a dictionary to convert an Excel column number to a number:*
def letter_to_number(letters):
letters = letters.lower()
dictionary = {'a':1,'b':2,'c':3,'d':4,'e':5,'f':6,'g':7,'h':8,'i':9,'j':10,'k':11,'l':12,'m':13,'n':14,'o':15,'p':16,'q':17,'r':18,'s':19,'t':20,'u':21,'v':22,'w':23,'x':24,'y':25,'z':26}
strlen = len(letters)
if strlen == 1:
number = dictionary[letters]
elif strlen == 2:
first_letter = letters[0]
first_number = dictionary[first_letter]
second_letter = letters[1]
second_number = dictionary[second_letter]
number = (first_number * 26) + second_number
elif strlen == 3:
first_letter = letters[0]
first_number = dictionary[first_letter]
second_letter = letters[1]
second_number = dictionary[second_letter]
third_letter = letters[2]
third_number = dictionary[third_letter]
number = (first_number * 26 * 26) + (second_number * 26) + third_number
return number
REMEMBER: Square brackets are used to reference by value.
Instead of defining a dictionary, you can use a property of the ASCII character set, in that the Latin alphabet begins from its 65th position for “A” and its 97th character for “a”, obtained using the ordinal function:
ord('a') # returns 97
ord('A') # returns 65
This returns ‘a’ :
chr(97)
More dictionaries:
# Eastern European countries: SyntaxError: invalid character in identifier
ee_countries={"Ukraine": "43.7M", "Russia": "143.8M", "Poland": "38.1M", "Romania": "19.5M", "Bulgaria": "6.9M", "Hungary": "9.6M", "Moldova": "4.1M"}
float(ee_countries["Moldova"].rstrip("M")) # 4.1
ee_countries.get("Moldova") # 4.1M
len(ee_countries.items()) # 7 are immutable in dictionary
min(ee_countries.items()) # ('Bulgaria', '6.9M') the smallest country
max(ee_countries.values()) # largest country = 9.6M ?
max(ee_countries.keys()) # largest key length = Ukraine
sorted(ee_countries.keys(),reverse=True) # ['Ukraine', 'Russia', 'Romania', 'Poland', 'Lithuania', 'Latvia', 'Hungary', 'Bulgaria']
del ee_countries["Estonia"]
ee_countries.pop["Bulgaria"]
ee_countries["Latvia"] = "1.9M"
ee_countries.update[['Lithuania', '2.8M'],['Belarus' , '9.4M']]
ee_countries.popitem() # remove item last added
len(ee_countries.items()) # 8 are immutable in dictionary
ee_countries["Bulgaria"]="7M"
ee2=ee_countries.copy()
ee_countries.clear() # remove all
print(ee_countries) # {} means empty
https://www.codesansar.com/python-programming-examples/sorting-dictionary-value.htm
File open() modes
The Python runtime does not enforce type annotations introduced with Python version 3.5. But type checkers, IDEs, linters, SASTs, and other tools can benefit from the developer being more explicit.
Use this type checker to discover when the parameter is outside the allowed set and warn you:
MODE = Literal['r', 'rb', 'w', 'wb']
def open_helper(file: str, mode: MODE) -> str:
...
open_helper('/some/path', 'r') # Passes type check
open_helper('/other/path', 'typo') # Error in type checker
BTW Literal[…] was introduced with version 3.8 and is not enforced by the runtime (you can pass whatever string you want in our example).
PROTIP: Be explicit about using text (vs. binary) mode.
with open("D:\\myfile.txt", "w") as myfile:
myfile.write("Hello")
| Character | Meaning |
|---|---|
| b | binary (text mode is default) |
| t | text mode (default) |
| r | read-only (the default) |
| + | open for updating (read and write) |
| w | write-only after truncating the file |
| a | append |
| a+ | opens a file for both appending and reading at the same time |
| x | open for exclusive creation, failing if file already exists |
| U | universal newlines mode (used to upgrade older code) |
myfile.write() returns the count of codepoints (characters in the string), not the number of bytes.
myfile.read(3) returns 3 line endings (\n) in string lines.
myfile.readlines() returns a list where each element of the list is a line in the file.
myfile.truncate(12) keeps the first 12 characters in the file and deletes the remainder of the file.
myfile.close() to save changes.
myfile.tell() tells the current position of the cursor.
File Copy commands
The shutil package provides fine-grained control for copying files:
import shutil
This table summarizes the differences among shutil commands:
| Dest. dir. | Copies metadata | Preserve permissions | Accepts file object | |
|---|---|---|---|---|
| shutil.copyfile | - | - | - | - |
| shutil.copyfileobj | - | - | - | Yes |
| shutil.copy | Yes | - | Yes | - |
| shutil.copy2 | Yes | Yes | Yes | - |
See https://docs.python.org/3/library/filesys.html
File Metadata
Metadata includes Last modified and Last accessed info (mtime and atime). Such information is maintained at the folder level.
For all commands, if the destination location is not writable, an IOError exception is raised.
-
To copy a file within the same folder as the source file:
shutil.copyfile(src, dst)
buffer cannot be when copying to another folder.
-
To copy a file within the same folder and buffer file-like objects (with a read or write method, such as StringIO):
shutil.copyfileobj(src, dst)
Notice both individual file copy commands do not copy over permissions from the source file. Both folder-level copy commands below carry over permissions.
CAUTION: folder-level copy commands do not buffer.
-
PROTIP: To copy a file to another folder and retain metadata:
file_src = 'source.txt' f_src = open(file_src, 'rb') file_dest = 'destination.txt' f_dest = open(file_dest, 'wb') shutil.copyfileobj(f_src, f_dest)
The destination needs to specify a full path.
-
To copy a file to another folder and NOT retain metadata:
shutil.copy2(src, "/usr", *, follow_symlinks=True)
-
You can use the operating system shell copy command, but there is the overhead of opening a pipe, system shell, or subprocess, plus poses a potential security risk.
# In Unix/Linux os.system('cp source.txt destination.txt') \# https://docs.python.org/3/library/os.html#os.system status = subprocess.call('cp source.txt destination.txt', shell=True) # In Windows os.system('copy source.txt destination.txt') status = subprocess.call('copy source.txt destination.txt', shell=True) \# https://docs.python.org/3/library/subprocess.html -
Pipe open has been deprecated. https://docs.python.org/3/library/os.html#os.popen
# In Unix/Linux os.popen('cp source.txt destination.txt') # In Windows os.popen('copy source.txt destination.txt')
Error Exception handling
Handle file not found exception : :
# if file doesn't exist in folder, create it:
import os
import sys
def make_at(path p, dir_name)
original_path = os.getcwd()
try:
os.chdir(path)
os.makedir(dir_name)
except OSError as e:
print(e, file=sys.stderr)
raise
finally: #clean-up no matter what:
os.chdir(original_path)
Operating system
There are platform-specific modules:
- Windows msvcrt (Visual C run-time)
- MacOS sys, tty, termios, etc.
To determine what operating system to wait for a keypress, use sys.platform, which has finer granularity than sys.name because it uses uname:
# https://docs.python.org/library/sys.html#sys.platform
from sys import platform
if platform == "linux" or platform == "linux2":
# linux
elif platform == "darwin":
# MacOS
elif platform == "win32":
# Windows
elif platform == "cygwin":
# Windows running cygwin Linux emulator
http://code.google.com/p/psutil/ to do more in-depth research.
PROTIP: This is an example of Python code issuing a Linux operating system command:
if run("which python3").find("venv") == -1:
# something when not executed from venv
SECURITY PROTIP: Avoid using the built-in Python function “eval” to execute a string. There are no controls to that operation, allowing malicious code to be executed without limits in the context of the user that loaded the interpreter (really dangerous):
import sys
import os
try:
eval("__import__('os').system('clear')", {})
#eval("__import__('os').system(cls')", {})
print "Module OS loaded by eval"
except Exception as e:
print repr(e)
Command generator
Create custom CLI commands by parsing a command help text into cli code that implements it.
Brilliant.
See docopt from https://github.com/docopt/docopt described at http://docopt.org
CLI code enhancement
Python’s built-in mechinism for coding Command-line menus, etc. is difficult to understand. So some have offered alternatives:
- cement - CLI Application Framework for Python.
- click - A package for creating beautiful command line interfaces in a composable way.
- cliff - A framework for creating command-line programs with multi-level commands.
- docopt - Pythonic command line arguments parser.
- python-fire - A library for creating command line interfaces from absolutely any Python object.
- python-prompt-toolkit - A library for building powerful interactive command lines.
Handling Arguments
For parsing parameters supplied by invoking a Python program, the command-line arguments and options/flags:
- python myprogram.py -v -LOG=info
The argparse package comes with Python 3.2+ (and the optparse package that comes with Python 2), it’s difficult to understand and limited in functionality.
https://www.geeksforgeeks.org/argparse-vs-docopt-vs-click-comparing-python-command-line-parsing-libraries/
Alternatives: to Argparse are Docopt, Click, Client, argh, and many more.
Instead, Dan Bader recommends the use of click.pocoo.org/6/why click custom package (from Armin Ronacher).
Click is a Command Line Interface Creation Kit for arbitrary nesting of commands, automatic help page generation. It supports lazy loading of subcommands at runtime. It comes with common helpers (getting terminal dimensions, ANSI colors, fetching direct keyboard input, screen clearing, finding config paths, launching apps and editors, etc.)
Click provides decorators which makes reading of code very easy.
The “@click.command()” :
\# cli.py
import click
@click.command()
def main():
print("I'm a beautiful CLI ✨")
if __name__ == "__main__":
main()
Python in the Cloud
On AWS:
Tutorials:
- Intro to Boto3
- https://linuxacademy.com/howtoguides/posts/show/topic/14209-automating-aws-with-python-and-boto3 has a whole video course
- Python, Boto3, and AWS S3: Demystified by Ralu Bolovan
- DataCamp’s intro to AWS and Boto3 VIDEO
- Johnny Chiver’s Beginner’s Guide makes use of Cloud9 in his main.py:
import boto3
s3_client = boto3.client('s3')
s3_client.create_bucket(Bucket="johnny-chivers-test-1-boto", CreateBucketConfiguration={'LocationConstraint':'eu-west-1'})
response = s3_client.list_buckets()
print(response)
- Sandip Das’s Boto3 with CI CD
- Automating AWS IAM user creation by Prashant Kakhera
- AWS has App Runner Overview
Hands-on lab
On Azure:
- Microsoft Azure Overview: Introduction series by Alex at Sigma Coding references https://github.com/areed1192/azure-sql-data-project covers Azure (Serverless) Functions in Python
- https://docs.microsoft.com/python/azure/
- https://azure.microsoft.com/resources/samples/?platform=python
- https://github.com/Azure/azure-sdk-for-python/wiki/Contributing-to-the-tests
- https://azure.microsoft.com/en-us/support/community/
- https://portal.azure.com/
- Sign in
- https://portal.azure.com/#view/Microsoft_Azure_Billing/SubscriptionsBlade
-
https://aka.ms/azsdk/python/all lists available packages.
pip install azure has been deprecated from https://github.com/Azure/azure-sdk-for-python/pulls
New Program Authorization
PROTIP: Each Azure services have different authenticate.
-
Install Azure CLI for MacOS:
brew install azure-cli
https://www.cbtnuggets.com/it-training/skills/python3-azure-python-sdk by Michael Levan https://www.youtube.com/watch?v=we1pcMRQwD8
from azure.cli.core import get_default_cli as azcli # Instead of > az vm list -g Dev2 azcli().invoke(['vm','list','-g', 'Dev2'])
###
Using Digital Blueprints with Terraform and Microsoft Azure
Sets: Day of week Set handling
set([3,2,3,1,5]) # auto-renumbers with duplicates removed
day_of_week_en = ["Sun","Mon","Tue","Wed","Thu","Fri","Sat"]
day_of_week_en.append("Luv")
days_in_week=len(day_of_week_en)
print(f"{days_in_week} days a week" )
print(day_of_week_en)
x=0
for index in range(8):
print("{0}={1}".format(day_of_week_en[x],x))
x += 1
Lists
Use a list instead for a collection of similar objects.
Prefix what to print with an asterisk so it is passed as separate values so a space is added in between each value.
li = [10, 20, 30, 40, 50] li = list(map(int, input().split())) print(*li)
Tuples
Values are passed to a function with a single variable. So to multiple values of various types to or from a function, we use a tuple - a fixed-sized collection of related items (akin to a “struct” in Java or “record”).
PROTIP: When adding a single value, include a comma at the end to avoid it being classified as a string:
-
REMEMBER: When storing a single value in a Tuple, the comma at the end makes it not be classified as a string:
mytuple=(50,) type(mytuple)
<class 'tuple'>
-
Store several items in a single variable:
person = ('john', 'doe', 40) (a, b, c) = person person a person[0::2] # every 2 from 2nd item = ('john', 40) person.index(40) # index of item containing 40 = 2
Range
range object and property-based unit testing.
myrange=range(3) type(myrange) myrange # range(0, 3) print(myrange) # range(0, 3) list(myrange) # [0, 1, 2] from zero myrange=range(1,5) list(myrange) # [1, 2, 3, 4] # excluding 5! myrange=range(3,15,2) list(myrange) # [3, 5, 7, 9, 11, 13] # skip every 2 list(myrange)[2] # 7 print( range(5,15,4)[::-1] ) # range(13, 1, -4)
<class ‘range’>
List comprehension
squares = [x * x for x in range(10)]
would output:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
Classes and Objects
- https://www.learnpython.org/en/Classes_and_Objects
- https://app.pluralsight.com/library/courses/core-python-classes-object-orientation
- The Playbook of code shown on 2 hr VIDEO: What Does It Take To Be An Expert At Python? by James Powell (@dontusethiscode) at the PyData conference.
Encapsulation is a software design practice of bundling the data and the methods that operate on that data.
Methods encode behavior (programmed logic) of an object and are represented by functions.
Attributes encode the state of an object and are represented by variables.
MEMONIC: Scopes: LEGB
- Local - Inside the current function
- Enclosing - Inside enclosing functions
- Global - At the top level of the module
- Built-in - In the special builtins module
Metaclasses
metaclasses: 18:50
metaclasses(explained): 40:40
Decorators
- VIDEO: Python Decorators 1: The Basics (in Jupyter notebook)
- VIDEO
- https://www.youtube.com/watch?v=yNzxXZfkLUA
- https://app.pluralsight.com/course-player?clipId=a5072421-b21f-4043-8164-e148e401492b
The string starting with “@” before a function definition
Decorators allow changes in behavior without changing the code.
Decorators take advantage of Python being live dynamically compiled.
There are limitations, though.
By default, functions within a class need to supply “self” as the first parameter.
class MyClass:
attribute = "class attribute"
...
def afunction(self,text_in):
cls.attribute = text_in
VIDEO: However, decorator @classmethod enable “cls” to be accepted as the first argument:
def afunction(self,text_in):
cls.attribute = text_in
The @classmethod is used for access to the class object to call other class methods or the constuctor.
There is also @staticmethod when access is not needed to class or instance objects.
Protocols
- Collection
- Container
- Hashtable
- Iterable
- Reversible
- Sequence
- Sized
Generators
- VIDEO
- https://www.youtube.com/watch?v=bD05uGo_sVI
- https://www.youtube.com/watch?v=vBH6GRJ1REM Python dataclasses will save you HOURS, also featuring attrs
generator: 1:04:30
dunders with Context Manager
“For repetitive set up and tear down, use Context Managers”. -VIDEO by Doug Mercer
When a client is used in Python code, it must be closed as well. Context manager is a language feature of Python that takes care of things when you enter and exit the context.
with open("myfile.txt", r) as f:
contents = f.read()
double underscores (“dunders”) before and after each name.
enter, exit,
init, repr, len, hash, add, sub,
and, reversed, contains, format, iter, call,
Magic methods getitem, len, etc. make you code look like it’s part of the library.
Make it Iterable.
context manager: 1:22:37
Secure coding
https://snyk.io/blog/python-security-best-practices-cheat-sheet/
-
Always sanitize external data
-
Scan your code
-
Be careful when downloading packages
-
Review your dependency licenses
-
Do not use the system standard version of Python
-
Use Python’s capability for virtual environments
-
Set DEBUG = False in production
-
Be careful with string formatting
-
(De)serialize very cautiously
-
Use Python type annotations
Insecure code in Pygoat
https://awesomeopensource.com/project/guardrailsio/awesome-python-security
https://github.com/mpirnat/lets-be-bad-guys from 2017
https://github.com/fportantier/vulpy from 2020 in Brazil
OWASP’s PyGoat is written using Python with Django web framework. Its code intentionally contains both traditional web application vulnerabilities (i.e. XSS, SQLi) and OWASP vulnerabilities The top 10 OWASP vulnerabilities in 2020 are:
• A1:2017-Injection
• A2:2017-Broken Authentication
• A3:2017-Sensitive Data Exposure
• A4:2017-XML External Entities (XXE)
• A5:2017-Broken Access Control
• A6:2017-Security Misconfiguration
• A7:2017-Cross-Site Scripting (XSS)
• A8:2017-Insecure Deserialization
• A9:2017-Using Components with Known Vulnerabilities
• A10:2017-Insufficient Logging & Monitoring
Instructions at https://github.com/adeyosemanputra/pygoat
-
Obtain the Docker image:
docker pull pygoat/pygoat docker run --rm -p 8000:8000 pygoat/pygoat
Watching for file changes with StatReloader Performing system checks... System check identified no issues (0 silenced). November 05, 2021 - 14:57:11 Django version 3.0.14, using settings 'pygoat.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C.
-
In the browser localhost:
http://127.0.0.1:8000
To learn how to code securely, PyGoat has an area where you can see the source code to determine where the mistake was made that caused the vulnerability and allows you to make changes to secure it.
https://owasp.org/www-pdf-archive/OWASP-AppSecEU08-Petukhov.pdf
https://rules.sonarsource.com/python/tag/owasp/RSPEC-4529 3400+ static analysis rules across 27 programming languages
Logging for Monitoring
- https://github.com/python/cpython/tree/3.6/Lib/logging
- https://realpython.com/python-logging-source-code/
- https://infosecwriteups.com/most-common-python-vulnerabilities-and-how-to-avoid-them-5bbd22e2c360
- https://docs.python.org/3/howto/logging.html#configuring-logging
-
It is estimated that it can take up to 200 days, and often longer, between attack and detection by the attacked. In the meantime, attackers can tamper with servers, corrupt databases, and steal confidential information.
“Insufficient Logging and Monitoring” is among the top 10 OWASP.
The vulnerability includes ineffective integration of security systems, which give attackers a way to pivot to other parts of the system to maintain persistent threats.
Prevent that by emitting a log entry for each activity such as: add, change/update, delete.
Use the Python logging module:
import logging
To emit each log entry, use the loggin method so that logs can be filtered by level. In order of severity:
logging.critical("CRITICAL - Can't ... Aborting!") # A serious error. The program itself may be unable to continue running. Displayed even in production runs.
logging.error("ERROR - Program cannot do it!") # A serious problem: the software is not been able to perform some function. Displayed even in production runs.
logging.warning("WARNING - unexpected!") # The software is still working as expected. But may be a problem in the near future (e.g. ‘disk space low’).
logging.info("INFO - version xxx") # Provides confirmation that things are working as expected.
logging.debug('DEBUG - detailed information such as each iteration in a loop used during troubleshooting at the lowest level of detail.')
At run-time, specify the highest level to display during that run:
python3 pylogging.py --log=INFO
- CRITICAL = 50
- FATAL = CRITICAL
- ERROR = 40
- WARNING = 30
- WARN = WARNING
- INFO = 20
- DEBUG = 10
- NOTSET = 0
CRITICAL, FATAL, and ERROR are always shown.
WARN (WARNING) is the default verbosity level. Set the default:
logging.basicConfig(level=logging.WARNING) logging.basicConfig(format='%(asctime)s %(levelname)s - %(message)s', datefmt='%H:%M:%S') #logging.basicConfig(level=logging.DEBUG,filename='example.log')</pre>
Also, provide a run-time option for outputing to a file:
logging.basicConfig(filename='app.log', filemode='w', format='%(name)s - %(levelname)s - %(message)s')
CAUTION: Be careful to not disclose sensitive information in logs. Encrypt plaintext.
The logging module also allows you to capture the full stack traces in an application.
-q (for -quiet) suppresses INFO headings.
-v (for -verbose) to display DEBUB messages.
-vv to display TRACE messages.
Use assert only during testing
- “Asserts and Assert Downsides to Defensive Programming in Python”
- https://www.linkedin.com/learning/unit-testing-in-python/why-pytest run in a Docker container from VSCode referencing https://github.com/coding-geographies/dockerized-pytest-course
PROTIP: By default, python executes with “debug” = “true” so asserts are processed by the Python interpreter. But in production when the program is run in optimized mode, “debug” = “true” so assert statements are ignored.
So avoid coding the sample code below which uses a comma that acts as an if/then:
def get_clients(user):
assert is_superuser(user), # user is not a member of superuser group
return db.lookup('clients')
In the above code, the user ends up with access to a resource with improper authentication controls.
Instead (to remediate), use a if-else logic to implement true and false conditions.
https://app.pluralsight.com/library/courses/using-unit-testing-python/table-of-contents
VIDEO: Use the hypothesis library
Concurrency Programming
https://app.pluralsight.com/library/courses/python-concurrency-getting-started
Bit-wise operators
https://app.pluralsight.com/course-player?clipId=5802d30b-69a9-4679-8594-53854739368a
https://techstudyslack.com/ a Slack for people studying tech
Stegnography
https://packetstormsecurity.com/files/165102/Stegano-0.10.1.html Stegano implements two methods of hiding: using the red portion of a pixel to hide ASCII messages, and using the Least Significant Bit (LSB) technique. It is possible to use a more advanced LSB method based on integers sets. The sets (Sieve of Eratosthenes, Fermat, Carmichael numbers, etc.) are used to select the pixels used to hide the information.
Parallel Computing
Multithreading, Multiprocessing, Concurrency & Parallel programming in Python for high performance.
Use multiple threads, processes, mutexes, barriers, waitgroups, queues, pipes, condition variables, deadlocks, and more.
https://www.udemy.com/course/parallel-computing-in-python/
On LinkedIn Learning: “Python Parallel and Concurrent Programming” 2h 11m Part 1 and Part 2 (using Python 3.7.3 on Windows PC machines) by Barron Stone and Olivia Chiu Stone Advanced
- A Mutex can only be acquired/released by the same thread.
A Semaphore can be acquired/released by different threads.
Vectors instead of loops
https://medium.com/codex/say-goodbye-to-loops-in-python-and-welcome-vectorization-e4df66615a52
ODBC
Java programs used JDBC to create databases within Salesforce, Microsoft Dynamics 365, Zoho CRM, etc.
To create and read/write such databases from within Python programs running under 32-bit and 64-bit Windows, macOS, Linux, use ODBC (Open Database Connect) API functions in:
- https://wiki.python.org/moin/ODBC
- https://www.progress.com/tutorials/odbc/connecting-to-odbc-databases-on-windows-from-python-using-turbodbc Turbodbc module for Windows
- Makes use of the Adventureworks sample SQL database Contoso Retail Data Warehouse run in Azure SQL Data Warehouse https://github.com/microsoft/sql-server-samples/tree/master/samples/databases/contoso-data-warehouse called instead of Visual Studio 2015 (or higher) with the latest SSDT (SQL Server Data Tools) installed
- wide-world-importers sample database?
Pyodbc by Michael Kleehammer:
- https://github.com/mkleehammer/pyodbc/
- https://learn.microsoft.com/en-us/sql/connect/python/pyodbc/python-sql-driver-pyodbc?view=sql-server-ver16
- Devart ODBC Driver for Python (pyodbc) library. See docs:
Functions:
- connect() to create a connection to the database
- cursor() to create a cursor from the connection
- execute() to execute a select statement
- fetchone() to retrieve rows from the query
Referenes
https://python.plainenglish.io/the-easiest-ways-to-generate-a-side-income-with-python-60104ad36998
https://learnpython.com/blog/9-best-python-online-resources-start-learning/
https://github.com/PacktPublishing/Python-for-Security-and-Networking https://learning.oreilly.com/library/view/python-for-security/9781837637553/ Python for Security and Networking - Third Edition by José Manuel Ortega covers the main modules we have in Python to encrypt and decrypt information, including pycryptome and cryptography. Covers extracting Geolocation and Metadata from Documents, Images, and Browsers, covers, main modules. Covers the pcapy and scapy modules to analyze network traffic and packet sniffing.
CS50P Harvard
0https://cs50.ai/chat
Videos from 15h47m47s of https://cs50.harvard.edu/python/2022:
- Introduction
- Comments, Functions, Variables
- Conditionals
- Loops
- Exceptions
- Libraries
- Unit Tests
- File I/O
- Regular Expressions
- Object-Oriented Programming
- Et Cetera
Cybrary.it
FREE: 2h57m by Joe Perry https://app.cybrary.it/browse/course/python
CS50 Python class at Project STEM
CS Python Fundamentals AFE
Unit 0: Welcome
Unit 1: Beginning in Computer Science
Unit 2: Number Calculations and Data: Division, Built-in Functions, Random Numbers,
Unit 3: Making Decisions: Simple Ifs, Logical Operators, Else, Elif, Alogorithm
Unit 4: Repetition and Loops: Loops, Count Variables, End Loop, Range, For Loops, Counting by Other Than 1, Modeling
Unit 5: Programming in EarSketch
Unit 6: Graphics: Color Code, Loops, X&Y Coordinates, Lines, Circles, Animation
Unit 7: Functions: Parameters, return, Tracing,
Unit 8: Lists
Unit 9: 2D Lists: Declaring, Loops, Algorithms, Animating
Unit 10: Programming in EarSketch
Unit 11: Internet: IP address, DNS, Packets & Routers, Web Pages, Cybersecurity, Net Neutrality,
Unit 12: Dictionaries (Extension): Methods, Iterating, Word Frequency Analysis
https://www.youtube.com/playlist?list=PLhQjrBD2T381WAHyx1pq-sBfykqMBI7V4 CS50x 2024 Lectures
https://www.youtube.com/watch?v=8wysIxzqgPI by neetcodeio referencing jointaro.com/r/neetcode
Problem Solving for Developers - A Beginner’s Guide
VIDEO: Python in 100 seconds:
Streamlit
https://www.youtube.com/watch?v=o8p7uQCGD0U Python Interactive Dashboard Development using Streamlit and Plotly by Programming Is Fun
https://www.youtube.com/watch?v=7yAw1nPareM
https://www.youtube.com/watch?v=_Um12_OlGgw Streamlit Elements You Should Know About in 2023 by Mısra Turp
https://www.youtube.com/watch?v=9n4Ch2Dgex0
Docstrings
Google Style Docstrings
Google style uses indentation to separate sections. The basic structure is:
```python def function(arg1, arg2): “"”Summary line.
Extended description of function.
Args:
arg1 (int): Description of arg1
arg2 (str): Description of arg2
Returns:
bool: Description of return value
Raises:
ValueError: Description of when this error is raised
Examples:
Examples should be written in doctest format and should illustrate how
to use the function.
>>> function(1, 'test')
True
"""
return True
Compilers
-
CPython is the standard and most widely used implementation of the Python programming language. It is both an interpreter and a compiler, providing a solid balance between performance and ease of use. CPython translates Python code into bytecode before executing it, which allows for excellent integration with C extensions and libraries.
-
Pyston is a fork of CPython, with additional optimizations primarily aimed at improving the performance of large applications. It uses JIT techniques similar to PyPy but focuses on maintaining maximal compatibility with CPython.
-
Nuitka is a Python-to-C++ compiler that translates Python code into optimized C++ executables. It can significantly improve the performance of Python applications by generating faster code while maintaining compatibility with the vast majority of Python libraries.
-
PyPy is renowned for its performance improvements over CPython, thanks to its Just-In-Time (JIT) compiler. It aims to execute Python code faster by dynamically compiling Python bytecodes to machine code at runtime. PyPy is particularly effective for long-running processes due to its optimization capabilities.
-
Jython compiles Python code to Java bytecode, allowing Python programs to run on the Java Virtual Machine (JVM). This makes it a great choice for integrating Python with Java, accessing Java frameworks, and using Java libraries in Python programs.
-
IronPython is tailored for compatibility with the .NET Framework, compiling Python code to .NET Common Intermediate Language (CIL). It enables developers to use Python scripts and libraries within the .NET framework and access .NET functionalities directly.
-
MicroPython is designed for use in microcontrollers and in constrained environments. It implements a subset of Python standards and includes specific libraries to optimize Python code to run on hardware with limited resources like RAM and processing power.
-
Brython (Browser Python) is an implementation of Python 3 for client-side web programming via a JavaScript framework. It allows Python code to run in browsers, utilizing web APIs as seamlessly as JavaScript.
-
Stackless Python enhances Python with support for microthreads, allowing for concurrent programming without traditional thread-related overhead. It’s particularly useful for applications requiring a large number of simultaneously active tasks, like game development or network servers.
QUESTION: What coding style would take advantage of compilers or hinder their use?
Resources
https://apps.apple.com/us/app/pythonista-3/id1085978097 https://www.youtube.com/watch?v=yO8w8PIn-uk
From https://tonylixu.medium.com/linux-basics-buffer-vs-cache-62ceb9f32f29
-
Buffers A small (about 20MB) temporary storage for holding raw disk blocks written to disks – used so that the OS kernel can optimize disk writes uniformly by merging multiple small writes into a more efficient single large write operation. -
Cache A temporary area in memory holding pages read from disk. Pages retained in the cache may be referenced again faster from memory without having to access the slow disk again.
https://www.monterail.com/blog/python-task-automation-examples#a:What-To-Do-with-Python?-Automation-Scripts-Ideas
Algorithms: Big O Time Complexity
https://guides.codepath.com/compsci/Big-O-Complexity-Analysis#o-log-n-logarithmic-complexity
AI tools to generate sports brackets is a good way to illustrate the concept of logarithmic time complexity because adding a new team to an already large bracket does not require the team to play all other teams
5.1.5 https://bjc.edc.org/bjc-r/cur/programming/5-algorithms/1-searching-lists/5-categorizing-algorithms.html?topic=nyc_bjc/5-algorithms.topic&course=bjc4nyc.html&novideo&noassignment
- An algorithm takes linear time the number of steps is proportional to the input size; doubling the input size doubles the time required.
- An algorithm takes sublinear time if the number of steps grows more slowly than the size.
- An algorithm takes constant time if it takes the same number of steps regardless of input size.
-
An algorithm takes quadratic time if the number of steps is proportional to the square of the input size.
- An algorithm takes polynomial time if the number of steps is less than or equal to a power of the size of the input, such as constant (n0), sublinear, linear (n1), quadratic (n2), or cubic (n3).
- An algorithm takes exponential time if the number of steps is proportional to an exponential function of the size of the input, such as 2n, 10n, etc., which is much slower than any polynomial.
Data Managements
The csv library is used for basic CSV file management.
The json library is used for basic JSON file management.
The pyyaml library is used for basic YAML file management.
The numpy library is used for math operations.
The pandas library is used for data management (at low volume).
The sqlite3 library is used for basic database management.
The pyarrow library is used for basic Arrow file management.
The pyodide library is used for ???
Visualization
The matplotlib library is the standard used for basic visualizations.
The seaborn library is a higher-level interface to matplotlib that provides a more concise and consistent API for creating visualizations.
Interactive visualizations using bokeh and plotly 3rd-party libraries.
See https://learning.oreilly.com/course/python-data-visualization/9780135426531/ 6-hour video course on OReilly: “Python Data Visualization: Create impactful visuals, animations and dashboards” by Bruno Goncalves Starting with pandas and matplotlib—two core Python libraries—you learn the basics of Python data pre-processing and visualization before moving on to more advanced packages. Seaborn, built on top of matplotlib, simplifies common tasks and enhances productivity. You will use jupyter notebooks to craft our visualizations.
More about Python
This is one of a series about Python:
- Python install on MacOS
- Python install on MacOS using Pyenv
- Python tutorials
- Python Examples
- Python coding notes
- Pulumi controls cloud using Python, etc.
- Test Python using Pytest BDD Selenium framework
- Test Python using Robot testing framework
- Python REST API programming using the Flask library
- Python coding for AWS Lambda Serverless programming
- Streamlit visualization framework powered by Python
- Web scraping using Scrapy, powered by Python
- Neo4j graph databases accessed from Python
2025-10-05 00:00:00 +0000 25-10-05 v015 + consolidation :2016-07-11-python-coding.md