

AWS data processing tools: Databases, Big Data, Data Warehouse, Data Lakehouse
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
- Competition in Cloud Databases
- Data Lifecycle
- Categories of tools
- Evolution in AWS Data Pipeline Tools
- Governance
- Compute
- Storage
- Observability
- Master Data
- Visualizations
- Streaming data
- Individual AWS Data Tools Alphabetically
- Which Query Service?
- AWS Data Exchange
- Apache Spark
- RDS
- Athena
- API Gateway
- Aurora
- S3
- Redshift
- Elasticache
- Timestream
- Kinesis
- CloudWatch
- CloudFront
- CloudTrail
- Map Reduce
- EMR
- AWS Glue
- DynamoDB
- DocumentDB
- SageMaker
- QuickSight
- AWS Batch
- AWS Lake Formation
- KMS
- Secrets Manager
- EC2
- Lambda
- EventBridge
- EKS
- DMS (Database Migration Service)
- Rekognition
- AWS Data Engineering certifications
- AWS Certified Database - Specialty
- AWS Certified Data Analytics - Specialty
- References
- Hands-on labs
- More on Amazon
Here are my notes reflecting what I’ve figured out so far about how developers and administrators can process data in the AWS cloud. I’m trying to present this in a logical sequence. But there are a lot of products that seem to do the same thing.
NOTE: Content here are my personal opinions, and not intended to represent any employer (past or present). “PROTIP:” here highlight information I haven’t seen elsewhere on the internet because it is hard-won, little-know but significant facts based on my personal research and experience.
Competition in Cloud Databases
In 2022 Gartner named AWS (Amazon Web Service), among all other cloud database vendors, the one with the best ability to execute with the most vision:
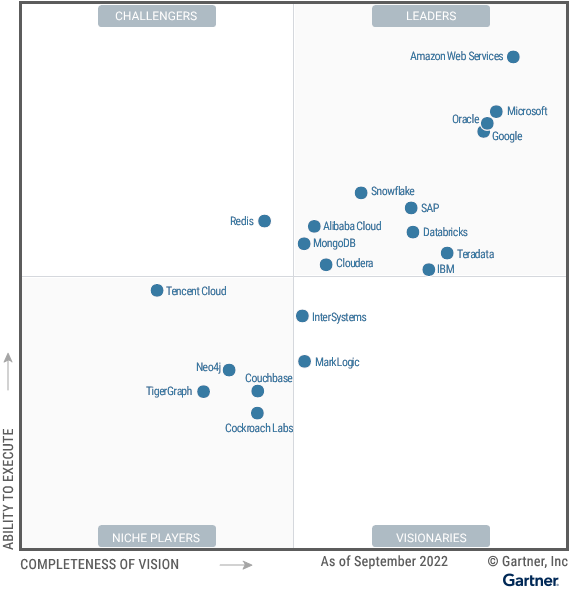
Amazon has over a dozen database products in its portfolio, providing many fully-managed “serverless” services for scaling each of the full gamut of open-source and licensed database technologies.
But some may argue that Snowflake and Databricks for their “Delta Lake” (using Parquet-structured data) removes the separation between OLTP and OLAP is now leading the field. Also see my notes on:
Below is an alphabetical list of third-party databases cloud customers can install in AWS like (some like they used to do on-prem):
- Apache Cassandra (NoSQL)
- Cockroach Labs (SQL)
- Cloudera EDH (Enteprise Data Hub) - Hadoop lakehouse based on Apache Iceberg SQL
- Couchbase (No-SQL)
- IBM
- InterSystems
- MarkLogic
- MariaDB
- MySQL
- MongoDB (No-SQL)
- Neo4j (graph database)
- Oracle database 12C
- PostgreSQL.org
- Redis
- SAP HANA
- Microsoft SQL Server
- Teradata EDW (Enterprise Data Warehouse)
- TigerGraph
(Listed separately are China-based offering)
Data Lifecycle
The data analytics lifecycle:
- Define
- Interpret
- Clean and Transform
- Enhance
- Analyze
- Visualize
Categories of tools
One AWS certification conceptually organizes data tools in these categories:
- Data Sources
- Data Injestion/Collection
- Storage and Data Management
- Processing
- Analytics
- Analysis
Each is detailed below:
Data Sources
- Amazon RDS (Relational Database Service) and Aurora
- Amazon DynamoDB (NoSQL)
Data Injection/Collection
- Database Migration Service (DMS)
- Simple Queue Service (SQS)
- Snowball
- AWS Internet of Things (IOT)
- MSK (Managed Stream for Kafka)
- AWS Direct Connect
Storage and Data Management:
- Simple Storage Service (S3)
- DynamoDB (cloud document database)
- Amazon Elasticsearch Service
Processing
- AWS Lambda
- AWS Glue - serverless bookmarks, DynamicFrame functions, job metrics, and etc. Troubleshooting Glue Jobs: what should you do if Glue throws an error.
- Amazon EMR
-
Elastic MapReduce, including Apache Spark, Hive, HBase, Presto, Zeppelin, Splunk, and Flume
- AWS Lake Formation
- AWS Step Functions for orchestrations
- AWS Data Pipeline
Analysis
- Managed Apache Flink (formerly Amazon Kinesis Data Analytics)
- Amazon ElasticSearch Service - Generally for log analysis, look for an ES solution along with Kibana
- Amazon Athena
- Amazon Redshift and Redshift Spectrum
-
Amazon SageMaker for Machine Learning & AI
- AWS TensorFlow
- AWS Cognito
Analytics & Visualization
- Quicksight
- Other Visualization Tools (not a managed service): Salesforce Tableau, D3.js, HighCharts, and a custom chart as a solution,
Monitoring & Security:
- IAM
- Cloud HSM (Hardware Security Module)
- STS (Security Token Service)
- HSM
- Amazon Inspector
Evolution in AWS Data Pipeline Tools
In this “world map” I show how, on one busy page, how AWS data services relate to each other for different roles. Red text indicates services for governance.
Amazon’s new official “flat” icons in my attempt at figuring out the interaction among the many AWS cloud technologies evolving from “Lift and Shift” to Serverless to Low-Code to Machine Learning and Generative Artificial Intelligence.
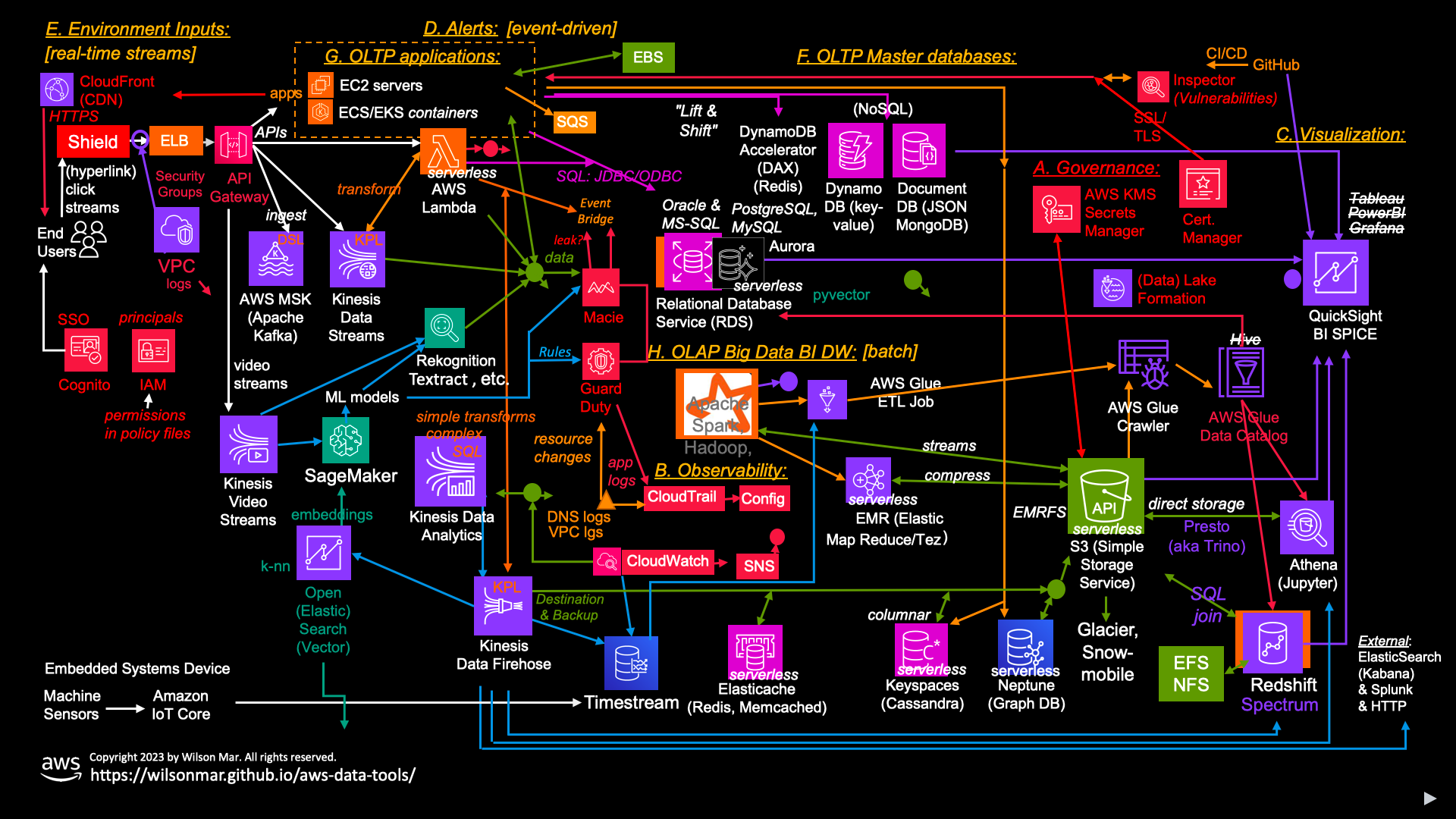
Click here for a full-screen view or buy the animated pptx.
(I’m working toward video of gradual reveal step-by-step like this)
Here we try to introduce AWS in a deeper way than marketing generalizations.
The number of services from AWS can be overwhelming. As busy as this diagram make seem, it’s still a subset of the 200 plus services Amazon’s offers. I created this “world map” to make sense of how AWS services relate to each other and differ from each other, in the sequence services are implemented, secured, and tested.
Elements of this “jigsaw puzzle” (PowerPoint file) can be removed if not relevant to you.
Let’s begin with a walk-through of just the categories of services. Before our system interacts with end-users connecting through public networks, we need A. Governance services to ensure the security of all other services created.
We need metrics, logs, and transaction traces to be collected centrally to enable an B. Observability capability that increasingly leverages Machine Learning and Artificial Intelligence to make predictions for proactive rather than reactive processes.
Insights from observability are obtained using C. Visualizations presenting graphics. Such analytics is the human interface to data and thus the basis for obtaining and judging value from the time and money spent on systems.
But there is a limit to how many charts any one person (or even a whole team) can absorb. So we are dependent on D. Alerts to know when to take action.
We are also dependent on E. Environment Inputs such as social media, weather, stock prices, etc.
Observability is most needed with E. OLTP applications, especially with legacy tech which require more manual effort than the serverless tech we also cover here.
Governance
Now let’s dive into the details of each of these categories, starting with Governance.
-
At the core of governance is the IAM (Identity and Access Management) Amazon service that controls access to all other services based on roles and attributes assigned to principals.
AUTOMATION is necessary within enterprises to create the many policy files that define fine-grained permissions to permit actions by each user, group, and role.
These are commonly managed in enterprises by a central SOC (Security Operations Center) that leading enterprises and managed services providers have organized to maintain a platform for vigilance over all other services. The SOC is often an expansion of the NOC (Network Operations Center) that has been around for decades working with on-premises servers and networks.
-
Lake Formation (service prefix: lakeformation) provides a way to centrally manage security settings and fine-grained permissions needed to permit access by AWS data lake services (Athena, Redshift, EMR).
Compute
When AWS was first created, it was a “lift and shift” of on-premises Windows servers running Java application programs using legacy storage to the cloud.
-

 EC2 (Elastic Compute Cloud) servers in Virtual Machines (VMs) in the AWS cloud.
EC2 (Elastic Compute Cloud) servers in Virtual Machines (VMs) in the AWS cloud. -
 containers managed by ECS (Elastic Container Service) and
containers managed by ECS (Elastic Container Service) and  EKS (Elastic Kubernetes Service) clusters in the AWS cloud.
EKS (Elastic Kubernetes Service) clusters in the AWS cloud.Storage
AWS continues to support legacy storage services accessed from within servers and containers:
-
EFS (Elastic File System) files and folders accessed as drives using the legacy NFS (Network File System) by legacy Windows and Linux servers;
-
EBS (Elastic Block Storage) accessed as boot volumes by EC2 servers running Windows and Linux servers, available in different sizes and performance levels (SSD, HDD, etc.);
-

 Many services (both modern and legacy) store their files in S3 (Simple Storage Service) (service prefix: S3) as <a target=”_blank href=”https://devblogs.microsoft.com/cse/2016/05/22/access-azure-blob-storage-from-your-apps-using-s3-api/”>objects/blobs</a> of various (proprietary) formats because they can be accessed serverlessly as API calls from programs.
Many services (both modern and legacy) store their files in S3 (Simple Storage Service) (service prefix: S3) as <a target=”_blank href=”https://devblogs.microsoft.com/cse/2016/05/22/access-azure-blob-storage-from-your-apps-using-s3-api/”>objects/blobs</a> of various (proprietary) formats because they can be accessed serverlessly as API calls from programs.Unlike legacy storage, data in S3 have High Availability (HA). Although each S3 object cannot be accessed from multiple regions, S3 data is replicated to several Availability Zones within a single region.
Snapshots can be taken of S3 objects and stored in S3 Glacier services (service prefix: Glacier) for long-term storage. Use Amazon’s Snowmobile service to manually move petabytes of data at a time to AWS.
All this makes S3 the data storage of choice among database services (Athena, EMR, and Redshift Spectrum, etc.). Green dots are used to avoid too many lines connecting with S3.
PROTIP: The format of data within S3 is proprietary to Amazon. Flexify.IO and S3Proxy using API were created to extend Azure Blob Storage to be compatible with S3. The Minio server is an open-source Golang-based S3-compatible object store that can be installed on-premises or in the cloud to expose local storage as S3 object storage.
-

 To protect the confidentiality of S3 objects, authentication and encryption mechanisms are based on cryptographic keys generated using the Amazon KMS (Key Management Service).
To protect the confidentiality of S3 objects, authentication and encryption mechanisms are based on cryptographic keys generated using the Amazon KMS (Key Management Service).The Key Management Service is used by AWS Secrets Manager (service prefix: secretsmanager) which automates the rotation and retrieval of credentials, API keys, and other secrets.
-
Developers of apps use CI/CD to automate scanning and deploy code from versioned source code in GitHub repositories. Included in CI/CD workflows are “static” code scanners that identify security vulnerabilities and suggest improvements.
-

 Amazon Inspector detects vulnerabilities running live in apps within EC2 servers and in Lambda Functions.
Amazon Inspector detects vulnerabilities running live in apps within EC2 servers and in Lambda Functions. -
Analysis of network latency has led some international enterprises to justify use of CloudFront to pre-load content to edge locations closer to users around the world. This is a form of CDN (Content Delivery Network) to reduce latency.
-
Amazon Cognito provides federated identity management, especially needed for mobile and web apps, so users can sign in directly with a user name and password, or through a federated third party for a SSO (Single Sign-On) to conveniently authenticate through Apple, Google, Azure, and social media such as Facebook, Twitter/X, LinkedIn, etc. Alternatives to Cognito include Okta, Auth0, etc.
-
Web services front-end software communicating with users on internet browsers</strong) (such as Safari, Google Chrome, and Microsoft Edge) need SSL/TLS certificates to encrypt communications. Those certificates are generated and obtained from the AWS Certificate Manager (service prefix: acm).
PROTIP: That is not the AWS Certificate Manager Private Certificate Authority (ACM PCA). [Terraform]
-
<img align=”right” width=”25” https://res.cloudinary.com/dcajqrroq/image/upload/v1693715513/aws-icons/Amazon-Shield.png”>Because click streams by human users can be emulated by automated bots in DDoS (Distributed Denial of Service) attacks to overwhelm servers, Amazon offers its Shield service (service prefix: shield). The “advanced” edition of Sheild adds 24x7 access to the AWS DDoS Response Team (DRT) and reduced fees from AWS usage spikes during attacks.
-
 Resources created within each Amazon account are created within a VPC (Virtual Private Cloud) segment.
Resources created within each Amazon account are created within a VPC (Virtual Private Cloud) segment. -
Firewall rules to control access to resources within a VPC are defined in Security Groups which Amazon may create.
AUTOMATION is needed to automatically delete Security Groups when the resources they protect are deleted.
-
Traffic allowed in by VPC enters through an external ELB (Elastic Load Balancer) that distributes traffic among multiple EC2 servers running the same software. This is a form of HA (High Availability) to ensure that if one server fails, another server can take over.
-

 The Amazon API Gateway service is used to track and throttle traffic based on tags that senders include in the HTTP header.
The Amazon API Gateway service is used to track and throttle traffic based on tags that senders include in the HTTP header.The API Gateway can feed REST API traffic to EC2 servers, ECS/EKS containers, or Lambda Functions. [Terraform]
-

 AWS Lambda (service prefix: lambda) runs functions written in Python, Node.js, Java, .NET C#, Erlang, Haskell, and other language run-times in the cloud without having to provision servers or containers. Thus, “serverless” (someone else’s computer hardware).
AWS Lambda (service prefix: lambda) runs functions written in Python, Node.js, Java, .NET C#, Erlang, Haskell, and other language run-times in the cloud without having to provision servers or containers. Thus, “serverless” (someone else’s computer hardware).Lambda functions are versatile. It can read and write to/from S3, DynamoDB, and other services.
But each function is limited in how much memory and CPU it can consume. If a function needs to run for longer than 15 minutes, it calls itself to continue.
AWS Lambda processes data in streams and queues to transform data from one format to another.
-
EventBridge is like the “Grand Central Terminal” for Lambda functions and other services to interact.
It can obtain keys from KMS, send SQL calls to databases, Send emails via SES (Simple Email Service), Send SMS text to mobile phones (via the Amazon Pinpoint service)
-

 EventBridge can be set to invoke on a schedule, such as to run the Amazon Macie (service prefix: macie2) web service to read data in S3 and apply Machine Learning models to identify keywords in the content. Notifications about potential leaks (anomalies) found are sent to EventBridge for further processing.
EventBridge can be set to invoke on a schedule, such as to run the Amazon Macie (service prefix: macie2) web service to read data in S3 and apply Machine Learning models to identify keywords in the content. Notifications about potential leaks (anomalies) found are sent to EventBridge for further processing.and pattern matching (aka managed and custom data identifiers in s3.tf)
- https://stackoverflow.com/questions/68346164/aws-macie-terraform-select-all-s3-buckets-in-account
- https://dev.to/aws-builders/protect-s3-buckets-with-aws-macie-16gm
- https://registry.terraform.io/modules/tedilabs/security/aws/latest/submodules/macie-account
- https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/macie2_classification_export_configuration
- https://github.com/aws-samples/aws-macie-customization-terraform-samples
- https://shisho.dev/dojo/providers/aws/Macie/aws-macie2-account/
- https://github.com/cloudposse/terraform-aws-macie
Amazon’s Machine Learning (ML) Marketplace sells pre-trained models for use in apps.
Also using Machine Learning models for pattern recognition are videos with sound.
-
 First, to ingest videos into S3, Amazon’s Kinesis Video Streams service (service prefix: kinesisvideo) is used. Being serverless, it scales without administrative effort.
First, to ingest videos into S3, Amazon’s Kinesis Video Streams service (service prefix: kinesisvideo) is used. Being serverless, it scales without administrative effort. -
Faces and objects in videos can be detected using Amazon’s Rekognition service (service prefix: Rekognition).
-
Amazon’s Textract service can be used to extract text from images.
-
Instead of using models created by Amazon, custom models can be created using Amazon’s SageMaker service (service prefix: SageMaker) running Tensorflow and other Machine Learning frameworks.
SageMaker Data Wrangler, a web UI-based service that integrates with SageMaker Studio for data scientists building machine learning pipelines that build, train, and deploy machine learning models. It comes with pre-configured data transformations to impute missing data with means or medians, one-hot encoding, and time series-specific transformers that are required for preparing data for machine learning. SageMaker Data Wrangler also provides a visual interface to create custom transformations using Python code. SageMaker Data Wrangler can be used to prepare data for training and inference with Amazon SageMaker, Amazon Redshift, Amazon Aurora, and Amazon Athena, as well as Snowflake.
The open-source version of Data Wrangler outside SageMaker Studio has now been renamed AWS SDK for Pandas.
AWS also provides AWS Glue DataBrew.
-
To take advantage of LLMs (Large Language Models), custom data can be integrated by reference to Embeddings (vectors) created by Amazon’s Open Search service, which uses a “K-nearest neighbor” algorithm to find the closest match to a query.
BTW there is also a Lookout for Metrics service.
Streams
To collect and process events real-time in a stream of data (such as logs,
-
 Amazon Kinesis Data Streams (service prefix: kinesis) is NOT serverless. It’s a messaging broker service to collect, process, and analyze – in real-time – continuous streams of data, writing messages to a “topic” from where it can be read or derived. It’s used for monitoring of fraud detection, trademark enforcement, and engagement/sentiment in social media platforms (Twitter/X, Instagram, Facebook, YouTube, LinkedIn, etc.), .
Amazon Kinesis Data Streams (service prefix: kinesis) is NOT serverless. It’s a messaging broker service to collect, process, and analyze – in real-time – continuous streams of data, writing messages to a “topic” from where it can be read or derived. It’s used for monitoring of fraud detection, trademark enforcement, and engagement/sentiment in social media platforms (Twitter/X, Instagram, Facebook, YouTube, LinkedIn, etc.), . -
 Amazon MSK (Managed Stream for Kafka) (service prefix: kafka) provides serverless APIs like Apache Kafka servers and their connectors, to transform data streams and tables.
Amazon MSK (Managed Stream for Kafka) (service prefix: kafka) provides serverless APIs like Apache Kafka servers and their connectors, to transform data streams and tables.MSK usually costs more than Kinesis. MSK can persist data forever. MSK can “fan out” with many nodes for simultaneous reading by consumers, whereas Kinesis can only be read by two consumers at a time.
Transformation processing by Kafka is defined in a a Java library either by its own (concise) DSL (Domain-Specific Language), Processor API, or KSQL (Kafka SQL) that embeds SQL in APIs.
Open-sourced by LinkedIn in 2010, Kafka can now be used with other AWS services such as Lambda, Kinesis, and Elasticsearch.
https://hevodata.com/learn/kafka-streams/
-
 Amazon Kinesis Data Firehose (service prefix: firehose) is a serverless (AWS-managed) service to deliver continuous streams of data (including video) to S3 buckets, other Amazon services, or any other HTTP endpoint destination (with or without transformation before send).
Amazon Kinesis Data Firehose (service prefix: firehose) is a serverless (AWS-managed) service to deliver continuous streams of data (including video) to S3 buckets, other Amazon services, or any other HTTP endpoint destination (with or without transformation before send).Kinesis Firehose can perform transformations on the fly specified in “Low-code” Blueprints within Lambda to do some transformations. This is why its performance is called “near real-time” (of 60 seconds+) rather than real-time (200+ milliseconds).
PROTIP: Firehose can be configured to deliver data to S3 either immediately or in batches of 1 to 15 minutes.
-
 Managed Apache Flink (formerly Amazon Kinesis Data Analytics) (service prefix: kinesisanalytics v2) processes complex SQL queries on incoming data streams on behalf of other Kinesis services. It can also reference data from S3 such as player scores for a leaderboard in an e-sports, election, or security app.
Managed Apache Flink (formerly Amazon Kinesis Data Analytics) (service prefix: kinesisanalytics v2) processes complex SQL queries on incoming data streams on behalf of other Kinesis services. It can also reference data from S3 such as player scores for a leaderboard in an e-sports, election, or security app.Once data is available in a target data source, it kicks off a AWS Glue ETL job to do further transform data for additional analytics and reporting.
-
 Amazon Timestream (service prefix: timestream) is a Time Series database designed to store a large amount of sensor data for IoT and DevOps application monitoring. It keeps recent data in memory and automatically moves historical data to a cost-optimized storage tier. It integrates with AWS IoT Core, Amazon Kinesis, Amazon MSK, open-source Telegraf, Amazon QuickSight, SageMaker.
Amazon Timestream (service prefix: timestream) is a Time Series database designed to store a large amount of sensor data for IoT and DevOps application monitoring. It keeps recent data in memory and automatically moves historical data to a cost-optimized storage tier. It integrates with AWS IoT Core, Amazon Kinesis, Amazon MSK, open-source Telegraf, Amazon QuickSight, SageMaker.Beacause Cloudwatch allows only 15 months of data retention, those who need to retain data longer at lower granularity send CloudWatch logs to one or more cloud services: Elastic, Splunk, Sumo Logic, Datadog, etc.
Timestream and CloudWatch are integrated to provide a single pane of glass for monitoring and analytics: Cloudwarch stream -> firehose -> data analytics -> Timestream.
https://docs.aws.amazon.com/timestream/latest/developerguide/what-is-timestream.html#what-is.use-cases Amazon TimeStream is a fast, scalable, and serverless time series database service for IoT and operational applications that makes it easy to store and analyze trillions of events per day up to 1,000 times faster and at as little as 1/10th the cost of relational databases.
https://www.reddit.com/r/aws/comments/j9nm1z/timestream_cloudwatch_positioning_counters_and/
https://docs.aws.amazon.com/timestream/latest/developerguide/Kinesis.html
https://docs.aws.amazon.com/timestream/latest/developerguide/ApacheFlink.html
https://docs.aws.amazon.com/timestream/latest/developerguide/creating-alarms.html
-
Kinesis provides to
 IoT Core a GUI to manage telemetry from robots and other devices.
IoT Core a GUI to manage telemetry from robots and other devices.To extract text and label images, recognize speaker in voice files, translate videos, and other AI-type capabilities, Amazon offers increasingly easier yet more sophisticated AI (Artificial Intelligence) services.
-
 Video, image, and voice (binary) files can be input into Amazon SageMaker to create ML (Machine Learning) Models, then used in SageMaker Studio UI for AI (Artificial Intelligence). Amazon’s Ground Truth service is specifically designed to label data for training ML models.
Video, image, and voice (binary) files can be input into Amazon SageMaker to create ML (Machine Learning) Models, then used in SageMaker Studio UI for AI (Artificial Intelligence). Amazon’s Ground Truth service is specifically designed to label data for training ML models. -
Because it’s expensive to create ML models, many now use Amazon’s pre-trained service:
 Rekognition for images,
Rekognition for images,Textract to extract text from documents and images,
 Lex for text,Polly for voice, or
Lex for text,Polly for voice, or buy (within SageMaker) custom models from Amazon’s Machine Learning (ML) Marketplace, or use a foundation model from Amazon’s Bedrock (service prefix: bedrock) partners for Generative AI work.
buy (within SageMaker) custom models from Amazon’s Machine Learning (ML) Marketplace, or use a foundation model from Amazon’s Bedrock (service prefix: bedrock) partners for Generative AI work. -
Amazon OpenSearch Service (service prefix: es) is a service managed by AWS based on a fork of (older) Elasticsearch 7.10.2 & Kibana 7.10 not supported by Elastic. Amazon contends that its vector engines can be used to add domain-specific embeddings as vector datastore to customize foundational Large Language Models used by Generative Artificial Intelligence apps.
Observability
-
 Amazon Security Hub (service prefix: securityhub) is enabled by default in all AWS accounts. It can be disabled, but not deleted. It provides a comprehensive view to centrally manage and mitigate security alerts.
Amazon Security Hub (service prefix: securityhub) is enabled by default in all AWS accounts. It can be disabled, but not deleted. It provides a comprehensive view to centrally manage and mitigate security alerts.It generates its own findings from its own automated and continuous
It checks against AWS best practices and industry standards, such as:
- Center for Internet Security (CIS) AWS Foundations Benchmark
- Payment Card Industry Data Security Standard (PCI DSS).
DEMO: Production configurations different than Test:
- Multi-account setup on AWS Organizations
- Cross-account & cross-region aggregation
- “Auto-enable accounts” to automatically enable Security Hub in new accounts
-
Integrate with AWS Chatbot to send finding alerts to Slack, Jira, ServiceNow, etc.
- Automate response & remediation with EventBridge, AWS Lambda functions
- Integrate with AWS Step Functions to orchestrate remediation workflows
- Integrate with AWS Service Catalog to create a product portfolio of remediation actions
- Integrate with AWS Security Hub custom actions to create custom remediation actions
-
Integrate with AWS Security Hub custom insights to create custom insights
- Enable CIS AWS Foundations Benchmark and PCI DSS standards
- Setup automatically update security and compliance checks managed by AWS when new AWS Config rules are released at Security Hub Controls Security Hub Controls are based on the CIS AWS Foundations Benchmark and the Payment Card Industry Data Security Standard (PCI DSS) v3.2.1.
It aggregates, organizes, and prioritizes alerts (findings) from AWS Partners (such as Palo Alto) and multiple AWS services:
-
 AWS CloudTrail (service prefix: securityhub) logs to S3 a record of every action to resources in each separate account (service prefix: cloudtrail-data). Each record allows for these questions to respond with corrective measures when security vulnerabilities are recognized.
AWS CloudTrail (service prefix: securityhub) logs to S3 a record of every action to resources in each separate account (service prefix: cloudtrail-data). Each record allows for these questions to respond with corrective measures when security vulnerabilities are recognized.Log category types:
- Management Events (configuration changes)
- Data Events
-
Insight on unusual Events
- Identify security issue: Was the change made by API or CLI or GUI?
- Which services were used & and unused?
- What actions were performed? read-only, read-write, delete, write-only?
- Who made the request? Source IP address (especially destructive actions)
- Instance ID and other parameters for those actions?
- Response elements returned by the AWS service?
PROTIP: Store CloudTrail logs for Security and Audit in a separate bucket than for Operations & Support.
Configure Prod differently than in Test.
- Create a trail to specify the S3 bucket to store logs.
- Enable log file validation which checks whether Log files were modified or deleted after the CloudTrail agent delivered them to the S3 bucket.
-
 Amazon Config is a SaaS service that reports on compliance to AWS resource rules. It’s used for audit, security analysis, change management, and operational troubleshooting. Rules include blacklists, requirements for tagging, encryption, and access control. DEMO.
Amazon Config is a SaaS service that reports on compliance to AWS resource rules. It’s used for audit, security analysis, change management, and operational troubleshooting. Rules include blacklists, requirements for tagging, encryption, and access control. DEMO.IaC users can use Config to check for compliance to rules before deploying changes. ?
PROTIP: All rules are run on every resource every time any resource is configured, so it can be pricy.
-
 Amazon GuardDuty is a SaaS threat detection service that uses Machine Learning to continuously monitor AWS accounts, resources, and workloads to detect anomalies such as malicious and unauthorized activity, or potentially unauthorized deployments that may indicate account compromise. GuardDuty also detects potentially compromised instances or reconnaissance by attackers.
Amazon GuardDuty is a SaaS threat detection service that uses Machine Learning to continuously monitor AWS accounts, resources, and workloads to detect anomalies such as malicious and unauthorized activity, or potentially unauthorized deployments that may indicate account compromise. GuardDuty also detects potentially compromised instances or reconnaissance by attackers.Threats are mitigated by initiating automated and manual responses defined in “Playbooks” used to resolve incidents.
Many of these responses are provided by AWS partners such as Splunk, CrowdStrike, Palo Alto Networks, etc.
AUTOMATION NEEDED: GuardDuty requires a Global Security Administrator to provide a CSV file of AWS accounts with matching email addresses. AWS emails to Personal AWS Health Dashboard.
Findings are sent to CloudWatch and EventBridge for further processing.
-
 Amazon CloudWatch logs (service prefix: cloudwatch logs)
Amazon CloudWatch logs (service prefix: cloudwatch logs) -
VPC logs,
-
VPC emits a log about each file processed. VPC Logs are typically sent to CloudWatch and EventBridge for further processing.
Master Data
Apps generate and update F. Master data – a central “source of truth” about products, customers, and inventory positions.
G. External environmental inputs.
-
Enterprises built H. Big Data to filter and aggregate data for “Business Intelligence” (BI) and “Data Warehousing” (DW) to make better decisions.
Historically, due to limitations in disk space and CPU, data was processed in [batch] mode. We then enabled [event-driven] capabilities. Now, systems can process data in real-time, as data arrives in continuous [streams].
Visualizations
Now let’s dive into visualizations and analytics.
Top-rated products in this category include Tableau (from Salesforce) (at $2,000/month), Microsoft’s PowerBI, and open-source Grafana.
-

 Within the AWS cloud, Data Analysts use the AWS QuickSight (service prefix: quicksight).
Within the AWS cloud, Data Analysts use the AWS QuickSight (service prefix: quicksight).For an additional monthly cost, rather than using a direct SQL query, data can be optionally be imported by QuickSight using its SPICE (Super-fast, Parallel, In-memory Calculation Engine). This is a public pool columnar in-memory storage for use by all users within each region to rapidly perform advanced calculations and serve data.
Amazon provides a “QuickSight mobile” app on iPhone and Android.
Types of data analysis
- Descriptive (what happened)
- Diagnostic (why did it happen) based on correlation and causation from drill-down
- Predictive (what is likely to happen)
- Prescriptive (do this) makes recommendations based on predictive analytics using data mining, statistics, modeling, machine learning, and artificial intelligence (AI) to make recommendations.
Grafana SaaS AWS Integration by OpsRamp
Managers working within enterprises depend on “Big Data” to aggregate data for “Business Intelligence” (BI) and “Data Warehousing” (DW) to make better decisions.
Monitoring and Alerts based on trends is how the system asks for human review and intervention.
-
QuickSight can access more data sources than shown on this diagram, such as text from GitHub, Twitter, and other APIs. QuickSight can create visualizations directly from many different sources.
Lambda can send, optionally through
 EventBridge scheduling,
EventBridge scheduling, SQS (Simple Queue Service) queues,
SQS (Simple Queue Service) queues, alerts in the form of emails via SES (Simple Email Service),
alerts in the form of emails via SES (Simple Email Service), SMS texts to mobile phones via AWS Pinpoint (service prefix: mobiletargeting )
SMS texts to mobile phones via AWS Pinpoint (service prefix: mobiletargeting ) messages to other AWS services via glue”,
messages to other AWS services via glue”,and 3rd-party HTTP services such as Slack.
Lambda functions can be triggered to fire dynamically by events from other AWS services.
But Lambda functions are limited on how large and frequent each can be.
-
Early apps used stored and retrieved data using relational SQL (Structured Query Language) to perform OLTP (Online Transaction Processing) of transactions (such as purchases and inventory) in relational databases.
Early databases also were installed inside EC2 servers, which required manual work to upgrade capacity, perhaps in more complex clusters.
-
Early approaches to bring databases to the cloud used what’s called “Lift and Shift” in …
-

 Amazon RDS (Relational Database Service) (service prefix: rds) supports a web data service (service prefix: rds-data) set up, operate, and scale a relational database in the AWS Cloud.
Amazon RDS (Relational Database Service) (service prefix: rds) supports a web data service (service prefix: rds-data) set up, operate, and scale a relational database in the AWS Cloud.With RDS, AWS takes care of the hardware and operating system patching across several regions.
-
But customer admins still need to install and upgrade a flavor of database software such as Oracle and Microsoft SQL Server.
Internally, applications reference each database in RDS using their DNS CNAME. RDS takes care of replication to a single secondary replica in the same region. But only the primary instance is updated. When RDS detects a need for failover, this multi-az instance approach switches DNS, which can take several minutes.
The multi-az cluster approach replicates to two replicas. Replicas can be readers, to relieve load on the one node which responds to write requests.
-
 Amazon Aurora brings to RDS SQL query compatibility with open-source relational database software MySQL and PostgreSQL. But Aurora adds shared storage that decouples storage from compute.
Amazon Aurora brings to RDS SQL query compatibility with open-source relational database software MySQL and PostgreSQL. But Aurora adds shared storage that decouples storage from compute.Internally, the serverless service operates differently than other RDS engines. Aurora provides a REST Data API.
Aurora can hold up to 128TB of data in a single database. Aurora can replicate to more than two replicas, each read by up to 15 separate readers from one reader endpoint. Aurora’s Multi-Master feature allows writes to be made to any replica, which are then replicated to other replicas. Aurora’s Backtrack features allow in-place rewind to a previous point in time.
Unlike RDS local storage, Aurora uses cluster volumes that are shared. Aurora can detect SSD disk failures and repair them automatically. Aurora can recover from a failure in less than 120 seconds, for an Availability SLA of 99.99% (“4 nines”).
-
AWS also manages two NoSQL databases accessible by QuickSight.
Unlike SQL, NoSQL databases have less complex queries and no joins like SQL. That enables them to be predictably faster for large data sets.
-

 The key-value store in AWS DynamoDB is a serverless service, so it automatically scale up and down to meet demand. So it’s used for workloads such as session stores or shopping carts.
The key-value store in AWS DynamoDB is a serverless service, so it automatically scale up and down to meet demand. So it’s used for workloads such as session stores or shopping carts.Internally, DynamoDB uses an array of (fast) SSDs to store petabytes of data in items of 400KB each. DynamoDB is a fully managed service, so AWS takes care of the hardware and operating system patching. However, Admins need to allocate Read and Write capacity Usage (RCU & WCU) based on the number of anticipated 4K items read and 1K items written per second (RPS and WPS). Use the DynamoDB Capacity Calculator to estimate the number of RCUs and WCUs needed for your workload.
Each item can have up to 256 attributes. Each attribute can be a scalar (string, number, binary, Boolean, or null) or a complex data type (list, map, or set).
PROTIP: Remember that, like S3, DynamoDB has regional scope. Each DynamoDB table cannot be accessed from other regions but can be accessed from across Availability Zones within the same region. ??? It can serve over 20 million requests per second without performance loss because it replicates (streams) activity across geographic regions. Within each region.
For fault tolerance, DynamoDB performs automatic synchronous replication across 3 AZs into Global Tables. Secondary indexes are also projected into indexes. The last write wins. Eventual consistency is the default (for performance), but strong consistency can be selected.
DynamoDB performs “continuous” backups to S3 automatically for “point-in-time” recovery up to 35 days back. All this enables AWS to commit to the highest Availability SLA of 99.999% (“6 nines”) for DynamoDB.
DynamoDB now supports Transactions, On-Demand Capacity, and .
-
 Amazon DocumentDB is a fully managed NoSQL database built for managing JSON data models. It offers a fully scalable, low-latency service to manage mission-critical MongoDB workloads. It automatically replicates six copies of your data across 3 availability zones to offer a 99.99% availability. Additionally, it can serve millions of requests per second, enabling developers to build highly available (and low-latency) applications.
Amazon DocumentDB is a fully managed NoSQL database built for managing JSON data models. It offers a fully scalable, low-latency service to manage mission-critical MongoDB workloads. It automatically replicates six copies of your data across 3 availability zones to offer a 99.99% availability. Additionally, it can serve millions of requests per second, enabling developers to build highly available (and low-latency) applications.AWS automatically replicates six copies of DocumentDB data across 3 Availability Zones to offer an Availability SLA of 99.99% (“4 nines”) for DocumentDB. VIDEO
PROTIP: DocumentDB requires more manual scaling than DynamoDB. DocumentDB Firestore (for licensing) is has been modified from open-source MongoDB. The number of instances for the cluster and the instance sizes need to be specified, so admins need to keep an eye on usage and performance. And although encryption in transit is enabled by default, encryption at rest is not enabled by default, and can only be configured using the AWS Console. Once enabled, encryption cannot be disabled.
-
 Instead of reaching DynamoDB directly, an AWS DAX (DynamoDB Accelerator) agent can be installed on client servers to reach an in-memory cache in front of DynamoDB, like Redis.
Instead of reaching DynamoDB directly, an AWS DAX (DynamoDB Accelerator) agent can be installed on client servers to reach an in-memory cache in front of DynamoDB, like Redis. -
 Amazon Keyspaces is a fully managed serverless database service to make it easier to scale open-source Apache Cassandra databases with minimal transition effort. Keyspaces is compatible with Cassandra Query Language API calls to its columnar database popular for storing chat logs, IoT, and gamer profiles.
Amazon Keyspaces is a fully managed serverless database service to make it easier to scale open-source Apache Cassandra databases with minimal transition effort. Keyspaces is compatible with Cassandra Query Language API calls to its columnar database popular for storing chat logs, IoT, and gamer profiles.Keyspaces provides encryption by default with continuous parallel backup for point-in-time recovery up to 35 days back. With replication across 3 AZs, AWS can guarantee 99.99% (4 nines) availability SLA.
Many apps are being built today using the most modern of databases:
-
Graph database have the flexibility to address the most complex of data relationships. It’s used for mapping knowledge graphs, social networking, recommendations, fraud detection, life sciences, and network/IT operations.
Datasets in Graph databases are highly connected, where relationships between elements are as important as the content data.
-
 Amazon Neptune (service prefix: neptune-db) is a serverless implementation of open-source Graph database software. It supports two graph data models and query languages:
Amazon Neptune (service prefix: neptune-db) is a serverless implementation of open-source Graph database software. It supports two graph data models and query languages:- Apache TinkerPop’s vertices and edges (added with properties and labels) traversed using the Gremlin property graph traversal language openCypher
- W3C’s RDF (Resource Description Language) triples and SPARQL declarative pattern matching query language
- Neptune does not support the popular but licensed Neo4j.
Neptune has a GUI that looks like RDS. As a fully managed service, AWS takes care of the hardware and operating system patching. Storage can grow automatically to 64 TB in 10 GB segments. However, Admins need to allocate Read and Write capacity Usage (RCU & WCU) based on the number of anticipated 4K items read and 1K items written per second (RPS and WPS). Use the DynamoDB Capacity Calculator to estimate the number of RCUs and WCUs needed for your own workload. Maximum memory in a serverless instance is 256 GB – Setting MaxCapacity to 128 NCUs (the highest supported setting) allows a Neptune Serverless instance to scale to 256 GB of memory, which is equivalent to that of an R6g.8XL provisioned instance type.
Announced in 2017, Since May 30, 2018, data in Neptune is replicated 6 times across 3 AZs on S3 disks offering 11 nines of durability, within a VPC that’s private by default. Replicas can support reads for performance. Failing database nodes are automatically detected and replaced. Its quorum system for read/write is latency tolerant.
Nepture requires that each request be signed using AWS Signature v4 libraries for Gremlin and SPARQL clients.
- https://aws.amazon.com/neptune/getting-started/
- https://docs.aws.amazon.com/neptune/latest/userguide/neptune-serverless.html#neptune-serverless-limitations
- https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/neptune_cluster
resource "aws_neptune_cluster" "example" { cluster_identifier = "neptune-cluster-development" engine = "neptune" engine_version = "1.2.0.1" neptune_cluster_parameter_group_name = "default.neptune1.2" skip_final_snapshot = true apply_immediately = true serverless_v2_scaling_configuration {} } resource "aws_neptune_cluster_instance" "example" { cluster_identifier = aws_neptune_cluster.example.cluster_identifier instance_class = "db.serverless" neptune_parameter_group_name = "default.neptune1.2" }immediately = true }Neptune Graphs can be analyzed within Amazon SageMaker Jupyter Notebooks.
Big Data
-
To address a way to process large amounts of data (“Big Data”) across many machines, the Apache open-source Hadoop framework was created in 2006. It stores data across many machines using its distributed file system (HDFS). Hadoop used Yarn to manage resources.
-
To process and analyze data (in parallel), Hadoop used a “MapReduce” approach developed by Google. Java and Python programs split each large dataset across a cluster for parallel analysis, fault tolerance, and scalability. The abstractions let the user focus on high-level logic.
Apache Hive was open-sourced in 2008 by Facebook to make SQL-like queries available to simplify complex Java MapReduce jobs on data stored using HDFS (Hadoop Distributed File System).
The Spark framework arrived in 2014 to add higher performance to Hadoop. Instead of batch MapReduce to process data in HDFS, Spark added real-time processing and in-memory compute with a more flexible API. Spark added use of local and Amazon S3 to store data and load data from HBase, Cassandra. In addition to Yarn, Spark supports Mesos, Kubernetes, machine learning, and graph processing.
Streaming data
-
AWS Presto (renamed Trino) is based on what Facebook open-sourced in 2014: a SQL query engine to access any size of data where it is stored, without needing to move data into a separate analytics system. Its connectors enable query of data in HDFS, S3, MySQL, PostgreSQL, Cassandra, MongoDB, Kafka, and Teradata. Query execution runs in-memory within a Hadoop cluster in parallel, so it can be fast.
-

 Amazon provides both Elastic Map Reduce and, since November 2021, Amazon EMR serverless to handle petabyte-scale analytics processing based on MapReduce and use of S3 buckets.
Amazon provides both Elastic Map Reduce and, since November 2021, Amazon EMR serverless to handle petabyte-scale analytics processing based on MapReduce and use of S3 buckets.Traditionally, OLAP was done using rigid, pre-defined structures such as a “star schema” to hold summarized data separately from the source OLTP data.
As the need for more ad hoc analysis grew, the need for a Data Lake emerged to store source data in its original form, without the need to transform it into a predefined schema. This some call “schema on read”.
AWS Glue ETL job creates a Crawler through S3 to use custom then built-in classifiers to build a Data Catalog of metadata. Glue can then be used to transform data into a schema for analysis. Glue can also be used to create ETL (Extract, Transform, Load) jobs to move data from one source to another.
-

 AWS Redshift (service prefix: redshift) is a cloud-based (but not serverless) service based on open-source PostgreSQL supporting an API (service prefix: redshift-data). So customer effort is needed to provision servers (with enhanced VPC).
AWS Redshift (service prefix: redshift) is a cloud-based (but not serverless) service based on open-source PostgreSQL supporting an API (service prefix: redshift-data). So customer effort is needed to provision servers (with enhanced VPC).AWS introduced Redshift Serverless (service prefix: redshift-serverless) during AWS re: Invent 2021.
“Red” in the name is because it is seeks to migrate users from the red logo of Oracle’s “Autonomous Data Warehouse”. Exadata, Like Oracle, Redshift stores columnar data in a cluster of nodes on EFS block storage used by operating systems and EC2 instances (rather than in S3 objects).
Redshift stores data in columns rather than rows. This enables millisecond response as it enables parallel query execution, especially when dealing with large tables.
It’s used to create star schemas in “data lakes” of petabyte-scale data warehouse for OLAP (Analytical Processing).
Redshift automates incremental encrypted backups into S3 every 8 hours, with retention for 1-35 days.
Redshift has “Analyze” operation which updates stats of tables in leader node (a ledger about which data is stored among partitions within a node). It improves Query performance
-
Amazon Redshift Spectrum extends Redshift to query from S3 without loading data, like using Presto with Hadoop. RedShift Spectrum can perform SQL joins with S3 objects and other foreign data in queries.
-
 Amazon Athena (service prefix: athena) is an AWS-managed SaaS offering. Athena’s console GUI offers a simplified Python Jupyter Notebook/strong> developer experience that supports ODBC/JDBC drivers (like Amazon DynamoDB) as well as REST API calls. So it’s good for small data sets.
Amazon Athena (service prefix: athena) is an AWS-managed SaaS offering. Athena’s console GUI offers a simplified Python Jupyter Notebook/strong> developer experience that supports ODBC/JDBC drivers (like Amazon DynamoDB) as well as REST API calls. So it’s good for small data sets.As a serverless provider, the Athena web service is always ready to query data. So it is used for infrequent or ad hoc data analysis such as any type of log data exported into S3, such as:
- Application Load Balancer
etc.
Athena can access the results of traditional EMR (Elastic MapReduce) jobs stored in S3 buckets. Athena can benefit from EMR’s direct, lower-level access to Spark Hadoop internals.
Engineers can utilize EMR’s integration with streaming applications such as Kinesis or Spark…
AWS provides for the transition from “Schema on write to “Schema on Read” using Athena.
Athena is advanced enough to perform from S3 buckets both legacy ETL (Extract, Transform, Load) processing AND modern ELT (Extract, Load, Transform) data structures stored into S3.
-
ETL (Extract, Transform, Load) is the traditional approach to arranging data for storage and analytics. This approach emerged at a time when disk space was more expensive and took time to obtain. ETL process removes data not needed in summaries in order to store less data. The resulting data (for OLAP) consists of a more rigid definition. Thus some call “schema on write”.
-
ELT (Extract, Load, Transform) is a more modern approach that uses more storage because data is stored in an unredacted form for transformation later, to enable retrospective analysis of attributes not considered previously.
Alternately, Data Analysts can run SQL queries on Presto data structures using Athena. without setting up EC2 servers (unlike Redshift and standard EMR). So Athena users only pay for data scanned ($5 per terabyte in most regions).
- Application Load Balancer
-
Many Athena users are migrating from EMR to use

 Amazon Glue ELT Jobs because Glue is serverless and thus easily scalable.
Amazon Glue ELT Jobs because Glue is serverless and thus easily scalable.EMR costs around $14-16 per day while AWS Glue is around $21 per day. But that difference is made up largely by avoiding the hassles of setup and the cost of “always on” EMR clusters.
ETL jobs are Scala or Python based. Glue can be used to create ETL (Extract, Transform, Load) jobs to move data from one source to another.
AWS Glue Crawler jobs scans S3 to create AWS Glue Catalogs housed in a Glue Schema Registry. The Glue Catalog for each region provides a central reference for metadata about all services. Catalog information includes location, ownership, schema, data types, and other properties changed over time, which can be used to create ETL jobs. VIDEO series 4
Glue can move data from producers and continously process (transform) data beofore moving to another data store, driving real-time metrics and analytics.
 Click image for full screen.
Click image for full screen.Recap
Click image for full-screen or buy the animated pptx.
Individual AWS Data Tools Alphabetically
Among the 200+ services that make up AWS, these cloud have the most with processing data (alphabetically):
- Athena
- Aurora
- EMR (Elastic Map Reduce)
- ElasticSearch
- Kinesis stream
- QuickSight
- Redshift
- RDS
- SageMaker
Which Query Service?
- https://www.cloudinfonow.com/amazon-athena-vs-amazon-emr-vs-amazon-redshift-vs-amazon-kinesis-vs-amazon-sagemaker-vs-amazon-elasticsearch/
- https://awsvideocatalog.com/analytics/athena/appnext-kinesis-emr-athena-redshift-choosing-the-right-tool-for-your-analytics-jobs-wEOm6aiN4ww/
-
https://medium.com/codex/amazon-redshift-vs-athena-vs-glue-comparison-6ecfb8e92349
-
https://www.linkedin.com/pulse/aws-glue-vs-datapipeline-emr-dms-batch-kinesis-what-ramamurthy/
- https://skyvia.com/etl-tools-comparison/aws-glue-vs-aws-data-pipeline
AWS Data Exchange
Amazon Data Exchange provides data products among Amazon’s marketplace to purchase data from various sources “3rd-party” to Amazon. Many datasets are free.
Apache Spark
- The ONLY PySpark Tutorial You Will Ever Need
- Computerphile
- https://www.youtube.com/watch?v=QLQsW8VbTN4
- https://www.youtube.com/watch?v=a_3Md9nV2Mk
RDS
QUESTION: RDS now has compatibility with other databases as well?
https://www.educative.io/collection/page/10370001/6628221817978880/5488262805454848/cloudlab Codelab: Getting Started with Amazon Relational Database Service (RDS)
https://github.com/terraform-aws-modules/terraform-aws-rds
Athena
https://www.educative.io/collection/page/10370001/6630323149078528/6214287382282240/cloudlab CLOUDLAB: Analyzing S3 Data and CloudTrail Logs Using Amazon Athena
API Gateway
Aurora
https://www.educative.io/cloudlabs/getting-started-with-amazon-aurora-database-engine Lab: Getting Started with Amazon Aurora Database Engine
https://github.com/terraform-aws-modules/terraform-aws-rds-aurora
Amazon Aurora PostgreSQL-Compatible Edition supports the pgvector extension to store embeddings from machine learning (ML) models in your database and to perform efficient similarity searches. Embeddings are numerical representations (vectors) created from generative AI that capture the semantic meaning of text or images input into a large language model (LLM). With pgvector, you can query embeddings in your Aurora PostgreSQL database to perform efficient semantic similarity searches of these data types, represented as vectors, combined with other tabular data in Aurora. This enables the use of generative AI and other AI/ML systems to build new content, enable hyper-personalization, create interactive experiences, and more.
PyVector on Aurora
https://repost.aws/questions/QUcSvXQXjlRFiiW9Heb5b7Eg/pgvector-for-aurora Discussion
https://aws.amazon.com/blogs/database/leverage-pgvector-and-amazon-aurora-postgresql-for-natural-language-processing-chatbots-and-sentiment-analysis/ uses a combination of pgvector, open-source foundation models (flan-t5-xxl for text generation and all-mpnet-base-v2 for embeddings), LangChain packages for interfacing with its components and Streamlit for building the bot front end.
https://www.youtube.com/watch?v=vKsqr_JcZm4 Sep 18, 2023 by Steve Dillie, AWS Solutions Architect In this session, learn how you can start using the pgvector extension with your Aurora PostgreSQL database.
https://pypi.org/project/pyvector/
https://github.com/pgvector/pgvector by Andrew Kane
https://github.com/topics/nearest-neighbor-search
S3
CONSOLE: https://s3.console.aws.amazon.com/s3/get-started?region=us-east-1
The pattern of S3 bucket URL static website endpoint:
- http://bucket-name.s3-website-Region.amazonaws.com
- http://bucket-name.s3-website.Region.amazonaws.com
Data in S3 is replicated across 3 AZs in a region.
It offers 11 nines durability of storage.
Cross-region replication is configurable for disaster recovery.
https://github.com/terraform-aws-modules/terraform-aws-s3-bucket
Redshift
![]()
![]() Redshift is an AWS-managed data warehouse, based on open-source PostgreSQL with JDBC & ODBC drivers with SQL.
Redshift is an AWS-managed data warehouse, based on open-source PostgreSQL with JDBC & ODBC drivers with SQL.
There are three variants of Redshift:
- Amazon Redshift Provisioned Clusters
- Redshift Spectrum
- Redshift Serverless
It’s not for blob data.
Redshift is designed for the fastest performance on the most complex BI SQL with multiple joins and subqueries. Amazon Redshift Spectrum is an optional service to query any kind of data (videos) stored in Amazon S3 buckets without first being loaded into the Redshift data warehouse. No additional charge for backup of provisioned storage and no data transfer charge for communication between Amazon S3 and Amazon Redshift.
Redshift uses machine learning and parallel processing of queries of columnar storage on very high-performance disk drives. It can also be expensive as it is always running.
Redshift mirrors data across a cluster, and automatically detects and replaces any failed node in its cluster. Failed nodes are read-only until replaced. An API is used to change number, type of nodes.
Redshift’s internal components include a leader node and multiple compute nodes that provide parallel data access in the same format as queries. The leader node has a single SQL endpoint. As queries are sent to the SQL endpoint, jobs are started in parallel on the compute nodes by the leader node to execute the query and return the results to the leader node. The leader gives the user results after combining results from all compute nodes.
Port number 5439 is the default port for the Redshift data source
https://www.educative.io/collection/page/10370001/4752686122270720/5745459222806528/cloudlab CLOUDLAB: Getting Started with Amazon Redshift
https://github.com/terraform-aws-modules/terraform-aws-redshift
Redshift stores in S3 snapshots for point-in-time backups.
Redshift has 3 node types defining mix of CPU, memory, storage capacity, and drive type:
-
DS2 - legacy, using HDD. not used much.
-
DC2 - Compute-intensive with local SSDs (for data warehouse) with compute together with storage. Launched in VPC. Has 2x the performance of DS2 and 1/2 the cost of DS2. Use for datasets under 1 TB (compressed), for best price and performance.
-
RA3 - managed storage with SSDs and HDDs (for data lake) with 3x the performance of DC2 and 1/2 the cost of DS2. RA3 nodes can be scaled up to 128 nodes. Used to scale compute separate from storage. Thus, the recommended type.
- Distribution KEY - distributes data into a slice based on key values in a column. Use for large tables that are joined to large tables.
- Distribution EVEN - distributes data evenly across all nodes using round-robin row-by-row distribution. Use for large tables. Each slice contains about the same number of rows.
- Distribution ALL - copies all data (same # of rows) to all nodes. Use for small tables that are joined to large tables.
- Distribution AUTO -
RedShift automatically assign compresssion type: REMEMBER:
- Sort keys, BOOLEAN, REAL, DOUBLE get RAW compression
- SMALLINT, INTEGER, BIGINT, DECIMAL, DATE, TIMESTAMP get AZ64 compression
- CHAR, VARCHAR, and TEXT get LZO compression
Example of a query:
create table ForeignKey_sample (
coll int NOT NULL [PRIMARY_KEY]
,col2 data
,col3 varchar(60)
,foreign key (col1) references PrimaryKey_sample (col1)) distkey(col1)
compount sortkey(col1, col2);
);
Redshift does not enforce unique primary and foreign key constraints even though it benefits from them. That’s because each query predicate can use any subset of the columns in a table, and the query optimizer can use the knowledge of the table’s constraints to optimize the query plan. EXPLAIN command shows the query plan.
COPY command most efficient way to load data into Redshift, reading in parallel from multiple files and loading in parallel into multiple slices.
Redshift Spectrum is an extension of Redshift that allows you to query data stored in S3 buckets directly without having to load it into Redshift first. It uses the same SQL syntax as Redshift. It’s useful for infrequently accessed data.
Elasticache
Elasticache is a fully managed implemenation of Redis, Memcached. And it makes use of in-memory data store, so it boasts sub-millisecond response time and millions of requests per second – at scale.
It supports Redis data structures such as lists, maps, sets, sorted sets with range queries, bitmaps, hyperloglogs, and geospatial indexes with radius queries. So it supports real-time analytics from caching, session management, gaming, geospatial services, and queuing.
Timestream
Timestream is a fully-managed time series database.
Kinesis
Here’s a hands-on, step-by-step tutorial on setting up a Kinesis stream to ingest logs (based on AWS docs & this)
- Get an AWS account with enough permissions.
-
Go to the Kinesis service (click among recents or at the top of the Amazon Management Console, in the search bar, search for “Kinesis” - “Real time data streaming”)
https://us-east-1.console.aws.amazon.com/kinesis/home?region=us-east-1#/home https://us-east-1.console.aws.amazon.com/kinesis/home?region=us-east-1#/dashboard
-
On another monitor:
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/kinesis_stream
- Set Region (us-east-1).
-
Notice there the types of Kinesis services:
-
Kinesis Data Streams - Collect streaming data with a data stream. This service allows for creating and managing real-time data streams from massive data sources. Kinesis Data Streams can handle large amounts of streaming data and can autonomously scale up or down as data volume varies.
-
Kinesis Data Firehose - Process and deliver streaming data with data delivery stream. This service captures, transforms, and loads streaming data into Amazon Web Services storage services such as S3, Redshift, and Elasticsearch. It can manage and send many data streams to AWS services.
-
Managed Apache Flink - Formerly Kinesis Data Analytics - Analyze streaming data with data analytics application. This service delivers real-time analytics on streaming data using SQL queries in a fully managed environment, allowing instant data insights and action. It has a separate dashboard, such as:
https://us-east-1.console.aws.amazon.com/flink/home?region=us-east-1#/dashboard
-
-
Select “Kinesis Data Streams”, then “Create data stream” orange button section.
https://us-east-1.console.aws.amazon.com/kinesis/home?region=us-east-1#/streams/create
resource "aws_kinesis_stream" "test_stream" { name = "terraform-kinesis-test" shard_count = 1 -
For “Data stream name”, follow naming conventions:
project-env-data-stream-type-name-sequence#
woohoo1-test-vid-shoo-001
Data stream types:
- vid = video
- logs
- etc.
-
For “Capacity mode” as “Provisioned” (under the “Data stream capacity” section)
stream_mode_details { stream_mode = "PROVISIONED" }PROTIP: Start with Provisioned: Use provisioned mode when you can reliably estimate throughput requirements of your data stream. With provisioned mode, your data stream’s capacity is fixed.
On-demand: Use this mode when your data stream’s throughput requirements are unpredictable and variable. With on-demand mode, your data stream’s capacity scales automatically. On-demand mode eliminates the requirement to manually provision and scale your data streams. With on-demand mode, your data streams automatically scale their write capacity
Capacity mode Write capacity Maximum Read capacity Provisioned 1 MiB/second &
1,000 records/second2 MiB/second On-demand 200 MiB/second &
1200,000 records/second400 MiB/second -
Set shard_count = “Provisioned shards” to “1.”
PROTIP: Each shard can support up to 5 GET requests per second. So track actual usage over time.
PROTIP: Payment is based on shard hours used and PUT i/o processed. Each shard can ingest 1 MB/sec and 1,000 PUT/sec.
PROTIP: Adjust this number later, as needed.
Total data stream capacity: Shard capacity is determined by the number of provisioned shards. Each shard ingests up to 1 MiB/second and 1,000 records/second and emits up to 2 MiB/second. If writes and reads exceed capacity, the application will receive throttles.
retention_period = 48
Kinesis can keep stream data from a default of 1 to a max configurable of 365 days. Kinesis is not for long-term storage. It is more suitable for streaming data processing rather than interactive analytics.
-
“Enable after creation” are:
- Server-side encryption (SSE) disabled
- Monitoring enhanced metrics disabled
- Tags disabled
shard_level_metrics = [ "IncomingBytes", "OutgoingBytes", ] tags = { Environment = "test" } } -
Click “Create data stream” to create the data stream.
IAM Roles
Two IAM roles are needed for the EC2 instance:
-
Go to the IAM service (In Amazon Management Console, search for “IAM” in the search bar, and click
-
Click “Roles” in the left-hand menu.
-
Click “Create role.”
-
Choose “AWS service” as the “Trusted entity type.”
-
Select “EC2” from the “Use case” and click “Next.”
-
Select the EC2RolePolicy policy and click “Next.”
-
Enter ec2_producer_role as the “Role name.”
-
Click “Create role.”
Create an IAM role for the consumer Lambda function:
-
Click “Create role.”
-
Choose “AWS service” as the “Trusted entity type.”
-
Select “Lambda” from the “Use case” and click “Next.”
-
Select AWSLambdaKinesisExecutionRole and LambdaRolePolicy policies and click “Next.”
-
Enter lambda_consumer_role as the “Role name.”
-
Click “Create role.”
Analyze
How this real-time data streaming service used for collecting, processing, and analyzing real-time data.
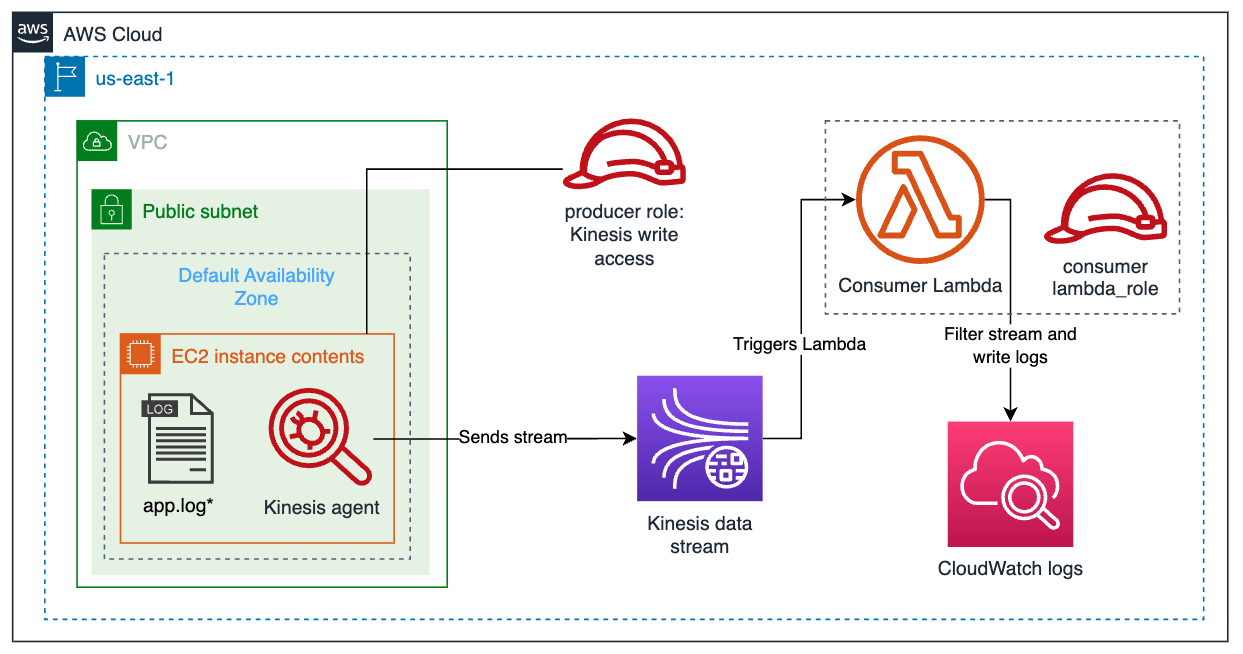
Each consumer can read streams at a different granularity.
VIDEO: Alternative to Kinesis Data Streams is …
- Input KPL (Kinesis Producer Library), agent, PUT API
-
Output KCL
- https://www.youtube.com/watch?v=ZW6wbUILlI0&t=41s
Kinesis Data Streams ingests continuous streams of data (to shards), replicated across three AZs in a Region. It uses a cursor in DynamoDB to restart failed apps at the exact position within the stream where failure occured.
- https://www.youtube.com/watch?v=vCRa3pymCzA
Kinesis Storm Sprout reads from a Kinesis stream into Apache Storm.
Kinesis Data Firehose can be adjusted via API calls for specified data rates (capacity). Duplicates can occur with Firehose.
Kinesis Data Analytics provisions capacity in Kinesis Processing Units (KPU) for memory and corresponding computing and networking capacity. Kinesis Data Analytics supports two runtime environments: Apache Flink and AWS Glue.
Kinesis Video Streams automatically provisions and elastically scales to millions of devices and scales down when devices are not transmitting.
- https://aws.amazon.com/kinesis/video-streams/pricing/

- https://www.youtube.com/watch?v=_bRTlb9b59Y by “Be a Better Dev”
- https://www.youtube.com/watch?v=b0ghP_WGYC8 by Enlear Academy
Johnny Chivers videos about Kinesis:
- setup from a Mac referencing
https://github.com/johnny-chivers/kinesisZeroToHero containing a CloudFormation yaml template.
CloudWatch
Amazon CloudWatch is a web service to monitor and manage various metrics, and configure alarm actions based on data from those metrics.
Amazon CloudWatch Logs is a web service for monitoring and troubleshooting your systems and applications from your existing system, application, and custom log files. You can send your existing log files to CloudWatch Logs and monitor these logs in near-real time.
https://github.com/terraform-aws-modules/terraform-aws-cloudwatch
CloudFront
https://github.com/terraform-aws-modules/terraform-aws-cloudfront
CloudTrail
AWS CloudTrail is a web service that records AWS API calls for your account and delivers log files to you. The recorded information includes the identity of the API caller, the time of the API call, the source IP address of the API caller, the request parameters, and the response elements that the AWS service returns.
Map Reduce
https://www.educative.io/answers/mapreduce
EMR
![]() Amazon EMR (Elastic Map Reduce) is a PaaS service - setup on a collection of EC2 instances called nodes running
“Big Data” utilities Hadoop, Spark, and Presto running in the AWS cloud.
Amazon EMR (Elastic Map Reduce) is a PaaS service - setup on a collection of EC2 instances called nodes running
“Big Data” utilities Hadoop, Spark, and Presto running in the AWS cloud.
- EMR automates the launch of compute and storage nodes powered by Amazon EC2 instances.
- Each EMR cluster has master, core, and task nodes. Each node is a EC2 (Elastic Compute Cloud) instance.
- Master node manages the cluster, running software components to coordinate the distribution of data and tasks across other nodes for processing.
- Core nodes have software components that run tasks and store data in the Hadoop Distributed File System (HDFS)
- Task node is made up of software components that only run tasks and do not store data in HDFS.
EMR can store data securely using customer encryption keys using an HDFS (Hadoop Distributed File System). EMR secures querying of data stored outside the cluster, such as in relational databases, S3, AWS Fargate K8s. EMR is often used for predictable data analysis tasks, typically on clusters maee available for extended periods of time. But it also supports Reserved Instances and Savings Plans for EC2 clusters and Savings Plans for Fargate, which can help lower cost. Only pay for when cluster is up.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-supported-instance-types.html
EMR is a managed Hadoop framework that provides a platform to run big data processing jobs at scale.
- Created in a private subnet within a VPC.
- There’s an EMR-managed Security Group for master, core/task, and manger? cluster in private subeta
- Additional security groups to control network access via NAT serv through a gateway
- Security groups can only be added on create.
-
Rules within a Security Group can be added, edited, and deleted after creation.
- EMR can use ENI to connect directly with EC2, Athena, EMR, Kenesis Firehose, Streams, RedShift, SageMaker, and VPC Endpoints.
- EMR clusters can be configured to use AWS Glue Data Catalog as the metastore for Apache Hive and Apache Spark.
ENI (Elastic Network Interface) connects with other AWS services. ENIs are virtual network interfaces that provide a primary private IP address, one or more secondary private IP addresses, and a MAC address to the nodes.
An S3 Gateway Endpoint is used to provide a secure and private connection between the EMR cluster and the S3 bucket. It allows traffic to flow directly between the EMR cluster and the S3 bucket without leaving the Amazon network
EMR v1.4.0 can use HDFS transparent encryption.
EMRFS on S3 for encryption at rest.
https://www.youtube.com/watch?v=_90YaA8IJ4A Migrate to Amazon EMR - Apache Spark and Hive
Data scientists can use EMR to run machine learning TensorFlow jobs.
https://www.youtube.com/watch?v=9Qq5K8e18Gw Migrate to Amazon EMR - Apache Spark and Hive - Cost Optimization
https://github.com/terraform-aws-modules/terraform-aws-emr
https://www.youtube.com/watch?v=ARzFq7DJpVQ
AWS Glue
![]() AWS Glue is a serverless data integration service that runs on top of Apache Spark for job scale-out execution
for users of analytics to find, prepare, move from 70+ data sources (SQL, not No-SQL).
AWS Glue is a serverless data integration service that runs on top of Apache Spark for job scale-out execution
for users of analytics to find, prepare, move from 70+ data sources (SQL, not No-SQL).
- Glue bulk imports Hive metastore into Glue Data Catalog
- Glue automatically provides job status to CloudWatch events triggering SNS notifications. With EMR you need to setup CloudWatch.
- Glue doesn’t handle heterogeneous ETL job types (which EMR does).
- Glue doesn’t handle streaming except for Spark Streaming.
For an hourly rate billed by the minute, Glue crawls through data and generates crawler Python code for ETL.
Glue creates a centralized Data Catalog which it can visually create, run, and monitor ETL (extract, transform, and load) and ELT pipelines for several workloads and types.
Query cataloged data using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
https://medium.com/@leahtarbuck/the-small-files-problem-in-aws-glue-49f68b6886a0
Johnny Chivers:
DynamoDB
https://github.com/topics/dynamodb?l=python
LAB: https://www.educative.io/cloudlabs/working-with-nosql-databases-a-beginner-s-guide-to-aws-dynamodb Working with NoSQL Databases: A Beginner’s Guide to AWS DynamoDB
https://github.com/pynamodb/PynamoDB
https://github.com/Remillardj/pyDBLoader
REMEMBER: Don’t use interleaved sort keys for columns that are montonically increasing values such as date/time stamps.
It’s managed via a REST API. Its SELECT operations are like SQL but not exactly.
So it’s for ports of apps from SQL relational databases that have joins.
Use S3 for storing blob data > 400 KB.
DAX (DynamoDB Accelerator) provides a cluster of cloud-based caching nodes that receives DynamoDB traffic through a client added on EC2 servers. Frequently-referenced DynamoDB data are held in-memory within 3-10 nodes to deliver up to a 10 times performance improvement. One of the nodes serves as the primary node for the cluster. Additional nodes (if present) serve as read replicas. All this without requiring developers to manage cache invalidation, data population, or cluster management.
DocumentDB
- https://dynobase.dev/dynamodb-vs-documentdb/
SageMaker
Amazon SageMaker is an AWS-managed service used to build, train, and deploy ML (Machine Learning) models. It has automatic Application Auto Scaling. Billing by the second, broken down by on-demand ML instances, ML storage, and fees for data processing in hosting instances. It has no maintenance windows or scheduled downtimes since its replication configured across three facilities in each AWS region to provide fault tolerance in the event of a server failure or Availability Zone outage.
QuickSight
![]()
DOCS Amazon QuickSight</a> is an AWS-managed SaaS interactive visual dashboard for displaying results from BI (Business Intelligence) ad hoc queries, not canned highly-formatted reports.
For an additional monthly cost, rather than using a direct SQL query, data can be optionally be imported into a dataset that uses SPICE (Super-fast, Parallel, In-memory Calculation Engine) allocated for use by all users within each region to rapidly perform advanced calculations and serve data. Internally, SPICE uses a combination of columnar storage in-memory.
QuickSight enables decision-makers to explore and interpret data from a variety of sources.
QuickSight offers these types of visualization:
- KPI values for a single metric of a single area or function (such as Net Promoter Score)
- Distributions of a metric (not over time) such as a scatter chart
- Relationship between two metrics (shown in a scatter chart or bubble chart of 3rd variable)
- Composition of a metric (shown using a pie chart or Tree Map, Stacked Area Chart)
- Comparisons
Each visualization is for a specific database.
Data analysts share Snapshots with others after preserving the configuration of an anlysis session, with that set of filters, parameters, controls, and sort order. Each snapshot reflects the data at the time of capture. Snapshots are not dynamically regenerated.
Enterprise Edition users can embed snapshots in a website. It’s not not like they can instead display a photo of the snapshot, because users can click on data points to drill down.
With QuickSight Enterprise edition, data stored in SPICE is encrypted at rest. Enterprise edition users also get Machine Learning and extra Enterprise security features (granular permissions, federated single-sign-on, row-level security, encryption at rest, on-prem VPC.
PROTIP: Access from QuickSight to Redshift need to be authorized.
AWS Batch
AWS Batch computing processes jobs without manual interaction.
https://github.com/terraform-aws-modules/terraform-aws-batch
AWS Lake Formation
![]()
AWS Lake Formation is used to create secure data lakes that centralize fine-grained access by role in AWS Glue ETL Data Catalog databases and tables, using familiar database-like grants for:
- Amazon Athena,
- Amazon Redshift Spectrum
- Amazon EMR for Apache Spark
- AWS Glue ETL
while making metadata available for wide-ranging analytics and machine learning (ML).
AWS Data Exchange to create a data mesh or meet other data sharing needs with no data movement. using services by Lake Formation include:
- Source crawl for content
- ETL and data prep
- Data catalog
QUESTION: Perhaps Lake Formation ensures that KMS (Key Management Service is used appropriatel?
KMS
https://github.com/terraform-aws-modules/terraform-aws-kms
Secrets Manager
AWS Secrets Manager provides key rotation, audit, and access control.
https://github.com/terraform-aws-modules/terraform-aws-secrets-manager
EC2
https://github.com/terraform-aws-modules/terraform-aws-ec2-instance
Lambda
https://github.com/terraform-aws-modules/terraform-aws-lambda
EventBridge
https://github.com/terraform-aws-modules/terraform-aws-eventbridge
EKS
https://github.com/terraform-aws-modules/terraform-aws-eks
DMS (Database Migration Service)
https://github.com/terraform-aws-modules/terraform-aws-dms
Rekognition
AWS has several offerings to make the creation and absorption of data streams easier and cheaper. ![]()
![]() Amazon Kinesis is a family of services that make it easy to collect, process, and analyze real-time, streaming data to get timely insights and react quickly to new information.
Amazon Kinesis is a family of services that make it easy to collect, process, and analyze real-time, streaming data to get timely insights and react quickly to new information.
Data API and Streams do not require a VPC to be setup to accept SQL commands. Integrates with EventBridge. Max 24 hr duration, 100 KB query size, 100 MB query result size. Auth using AWS Secretes Manager. FAQs. Commands: describe-statement, execute-statement, get-statement-result. troubleshooting and scenario-based questions, like how would you solve a ProvisionedThroughPutExceeded error, when should you merge or split shard, what encryption options are available, and how the Kinesis service integrates with other services.
https://medium.com/surfline-labs/intelligent-surf-cameras-fce6e7e3d03e describes an AI-powered surf camera at https://www.surfline.com/. It uses Amazon Kinesis Video Streams, Amazon Rekognition, and Amazon SageMaker to detect surfers and provide them with real-time surfing conditions and information.
AWS Data Engineering certifications
Among 12 certifications are 2 for data:
AWS Certified Database - Specialty
PDF (DBS-C01): $300 to answer 75%+ of 65 questions in 180-minute
AWS Certified Database - Specialty in these domains:
1. Workload-Specific Database Design 26%
1.1 Select appropriate database services for specific types of data and workloads.
- Differentiate between ACID vs. BASE workloads
- Explain appropriate uses of types of databases (e.g., relational, key-value, document, in-memory, graph, time series, ledger)
- Identify use cases for persisted data vs. ephemeral data
1.2 Determine strategies for disaster recovery and high availability.
- Select Region and Availability Zone placement to optimize database performance
- Determine implications of Regions and Availability Zones on disaster recovery/high availability strategies
- Differentiate use cases for read replicas and Multi-AZ deployments
1.3 Design database solutions for performance, compliance, and scalability.
- Recommend serverless vs. instance-based database architecture
- Evaluate requirements for scaling read replicas
- Define database caching solutions
- Evaluate the implications of partitioning, sharding, and indexing
- Determine appropriate instance types and storage options
- Determine auto-scaling capabilities for relational and NoSQL databases
- Determine the implications of Amazon DynamoDB adaptive capacity
- Determine data locality based on compliance requirements
1.4 Compare the costs of database solutions.
- Determine cost implications of Amazon DynamoDB capacity units, including on-demand vs. provisioned capacity
- Determine costs associated with instance types and automatic scaling
- Design for costs including high availability, backups, multi-Region, Multi-AZ, and storage type options
- Compare data access costs
2. Deployment and Migration 20%
2.1 Automate database solution deployments.
- Evaluate application requirements to determine components to deploy
- Choose appropriate deployment tools and services (e.g., AWS CloudFormation, AWS CLI)
2.2 Determine data preparation and migration strategies.
- Determine the data migration method (e.g., snapshots, replication, restore)
- Evaluate database migration tools and services (e.g., AWS DMS, native database tools)
- Prepare data sources and targets
- Determine schema conversion methods (e.g., AWS Schema Conversion Tool)
- Determine heterogeneous vs. homogeneous migration strategies
2.3 Execute and validate data migration.
- Design and script data migration
- Run data extraction and migration scripts
- Verify the successful load of data
3. Management and Operations 18%
3.1 Determine maintenance tasks and processes.
- Account for the AWS shared responsibility model for database services
- Determine appropriate maintenance window strategies
- Differentiate between major and minor engine upgrades
3.2 Determine backup and restore strategies.
- Identify the need for automatic and manual backups/snapshots
- Differentiate backup and restore strategies (e.g., full backup, point-in-time, encrypting backups cross-Region)
- Define retention policies
- Correlate the backup and restore to recovery point objective (RPO) and recovery time objective (RTO) requirements
3.3 Manage the operational environment of a database solution.
- Orchestrate the refresh of lower environments
- Implement configuration changes (e.g., in Amazon RDS option/parameter groups or Amazon DynamoDB indexing changes)
- Automate operational tasks
- Take action based on AWS Trusted Advisor reports
4. Monitoring and Troubleshooting 18%
4.1 Determine monitoring and alerting strategies.
- Evaluate monitoring tools (e.g., Amazon CloudWatch, Amazon RDS Performance Insights, database native)
- Determine appropriate parameters and thresholds for alert conditions
- Use tools to notify users when thresholds are breached (e.g., Amazon SNS, Amazon SQS, Amazon CloudWatch dashboards)
4.2 Troubleshoot and resolve common database issues.
- Identify, evaluate, and respond to categories of failures (e.g., troubleshoot connectivity; instance, storage, and partitioning issues)
- Automate responses when possible
4.3 Optimize database performance.
- Troubleshoot database performance issues
- Identify appropriate AWS tools and services for database optimization
- Evaluate the configuration, schema design, queries, and infrastructure to improve performance
5. Database Security 18%
5.1 Encrypt data at rest and in transit
- Encrypt data in relational and NoSQL databases
- Apply SSL connectivity to databases
- Implement key management (e.g., AWS KMS, AWS CloudHSM)
5.2 Evaluate auditing solutions
- Determine auditing strategies for structural/schema changes (e.g., DDL)
- Determine auditing strategies for data changes (e.g., DML)
- Determine auditing strategies for data access (e.g., queries)
- Determine auditing strategies for infrastructure changes (e.g., AWS CloudTrail)
- Enable the export of database logs to Amazon CloudWatch Logs
5.3 Determine access control and authentication mechanisms
- Recommend authentication controls for users and roles (e.g., IAM, native credentials, Active Directory)
- Recommend authorization controls for users (e.g., policies)
5.4 Recognize potential security vulnerabilities within database solutions
- Determine security group rules and NACLs for database access
- Identify relevant VPC configurations (e.g., VPC endpoints, public vs. private subnets, demilitarized zone)
- Determine appropriate storage methods for sensitive data
AWS Certified Data Analytics - Specialty
PDF (DAS-C01): $300, 75%+ of 65 questions in 180 minute
AWS Certified Data Analytics - Specialty
- https://docs.aws.amazon.com/whitepapers/latest/big-data-analytics-options/welcome.html
- https://d1.awsstatic.com/whitepapers/Migration/migrating-applications-to-aws.pdf
- https://towardsdatascience.com/becoming-an-aws-certified-data-analytics-new-april-2020-4a3ef0d9f23a
- https://portal.tutorialsdojo.com/courses/aws-certified-data-analytics-specialty-practice-exams/
Tips
https://medium.com/@athlatif/how-to-prepare-for-aws-certified-data-analytics-specialty-exam-das-c01-ebbfdd237e5e
- avoid using EMR when the question asks for “cost-effective” and “easy to manage” solutions.
- Quicksight can’t visualize data in real-time or near real-time, use OpenSearch and Kibana to achieve this.
- Kinesis data streams can’t write to S3 or Redshift directly, use Kinesis firehouse instead.
- Copy command is used to copy data to Redshift, Unload command is used to copy data from Redshift.
- Athena can’t query S3 Glacier you need to use Glacier select.
- The recommended file format is always ORC or parquet.
1. Collection 18%
1.1 Determine the operational characteristics of the collection system
- Evaluate that the data loss is within tolerance limits in the event of failures
- Evaluate costs associated with data acquisition, transfer, and provisioning from various sources into the collection system (e.g., networking, bandwidth, ETL/data migration costs)
- Assess the failure scenarios that the collection system may undergo, and take remediation actions based on impact
- Determine data persistence at various points of data capture
- Identify the latency characteristics of the collection system
1.2 Select a collection system that handles the frequency, volume, and source of data
- Describe and characterize the volume and flow characteristics of incoming data (streaming, transactional, batch)
- Match flow characteristics of data to potential solutions
- Assess the tradeoffs between various ingestion services taking into account scalability, cost, fault tolerance, latency, etc. https://www.youtube.com/watch?v=8jPB3PLI7bA
- Explain the throughput capability of a variety of different types of data collection and identify bottlenecks
- Choose a collection solution that satisfies connectivity constraints of the source data system
1.3 Select a collection system that addresses the key properties of data, such as order, format, and compression
- Describe how to capture data changes at the source
- Discuss data structure and format, compression applied, and encryption requirements
- Distinguish the impact of out-of-order delivery of data, duplicate delivery of data, and the tradeoffs between at-most-once, exactly-once, and at-least-once processing
- Describe how to transform and filter data during the collection process
2. Storage and Data Management 22%
2.1 Determine the operational characteristics of the storage solution for analytics
- Determine the appropriate storage service(s) on the basis of cost vs. performance
- Understand the durability, reliability, and latency characteristics of the storage solution based on requirements
- Determine the requirements of a system for strong vs. eventual consistency of the storage system
- Determine the appropriate storage solution to address data freshness requirements
2.2 Determine data access and retrieval patterns
- Determine the appropriate storage solution based on update patterns (e.g., bulk, transactional, micro batching)
- Determine the appropriate storage solution based on access patterns (e.g., sequential vs. random access, continuous usage vs.ad hoc)
- Determine the appropriate storage solution to address change characteristics of data (append-only changes vs. updates)
- Determine the appropriate storage solution for long-term storage vs. transient storage
- Determine the appropriate storage solution for structured vs. semi-structured data
- Determine the appropriate storage solution to address query latency requirements
2.3 Select appropriate data layout, schema, structure, and format
- Determine appropriate mechanisms to address schema evolution requirements
- Select the storage format for the task
- Select the compression/encoding strategies for the chosen storage format
- Select the data sorting and distribution strategies and the storage layout for efficient data access
- Explain the cost and performance implications of different data distributions, layouts, and formats (e.g., size and number of files)
- Implement data formatting and partitioning schemes for data-optimized analysis
2.4 Define data lifecycle based on usage patterns and business requirements
- Determine the strategy to address data lifecycle requirements
- Apply the lifecycle and data retention policies to different storage solutions
2.5 Determine the appropriate system for cataloging data and managing metadata
- Evaluate mechanisms for discovery of new and updated data sources
- Evaluate mechanisms for creating and updating data catalogs and metadata
- Explain mechanisms for searching and retrieving data catalogs and metadata
- Explain mechanisms for tagging and classifying data
3. Processing 24%
3.1 Determine appropriate data processing solution requirements
- Understand data preparation and usage requirements
- Understand different types of data sources and targets
- Evaluate performance and orchestration needs
- Evaluate appropriate services for cost, scalability, and availability
3.2 Design a solution for transforming and preparing data for analysis
- Apply appropriate ETL/ELT techniques for batch and real-time workloads
- Implement failover, scaling, and replication mechanisms
- Implement techniques to address concurrency needs
- Implement techniques to improve cost-optimization efficiencies
- Apply orchestration workflows
- Aggregate and enrich data for downstream consumption
3.3 Automate and operationalize data processing solutions
- Implement automated techniques for repeatable workflows
- Apply methods to identify and recover from processing failures
- Deploy logging and monitoring solutions to enable auditing and traceability
4. Analysis and Visualization 18%
4.1 Determine the operational characteristics of the analysis and visualization solution
- Determine costs associated with analysis and visualization
- Determine scalability associated with analysis
- Determine failover recovery and fault tolerance within the RPO/RTO
- Determine the availability characteristics of an analysis tool
- Evaluate dynamic, interactive, and static presentations of data
- Translate performance requirements to an appropriate visualization approach (pre-compute and consume static data vs. consume dynamic data)
4.2 Select the appropriate data analysis solution for a given scenario
- Evaluate and compare analysis solutions
- Select the right type of analysis based on the customer use case (streaming, interactive, collaborative, operational)
4.3 Select the appropriate data visualization solution for a given scenario
- Evaluate output capabilities for a given analysis solution (metrics, KPIs, tabular, API)
- Choose the appropriate method for data delivery (e.g., web, mobile, email, collaborative notebooks)
- Choose and define the appropriate data refresh schedule
- Choose appropriate tools for different data freshness requirements (e.g., Amazon Elasticsearch Service vs. Amazon QuickSight vs. Amazon EMR notebooks)
- Understand the capabilities of visualization tools for interactive use cases (e.g., drill down, drill through and pivot)
- Implement the appropriate data access mechanism (e.g., in memory vs. direct access)
- Implement an integrated solution from multiple heterogeneous data sources
5. Security 18%
5.1 Select appropriate authentication and authorization mechanisms
- Implement appropriate authentication methods (e.g., federated access, SSO, IAM)
- Implement appropriate authorization methods (e.g., policies, ACL, table/column level permissions)
- Implement appropriate access control mechanisms (e.g., security groups, role-based control)
5.2 Apply data protection and encryption techniques
- Determine data encryption and masking needs
- Apply different encryption approaches (server-side encryption, client-side encryption, AWS KMS, AWS CloudHSM)
- Implement at-rest and in-transit encryption mechanisms
- Implement data obfuscation and masking techniques
- Apply basic principles of key rotation and secrets management
5.3 Apply data governance and compliance controls
- Determine data governance and compliance requirements
- Understand and configure access and audit logging across data analytics services
- Implement appropriate controls to meet compliance requirements
courses
On LinkedIn: Prepare for the AWS Certified Data Analytics - Speciality (DAS-CO1) Certification by Noah Gift shows how things are done rather than on theory.
6 courses on Pluralsight (by different authors):
-
Collecting Data on AWS by Fernando Medina Corey 2h 18m
-
Storing Data on AWS by Fernando Medina Corey 2h 51m
-
Processing Data on AWS by Dan Tofan 1h 57m
-
Analyzing Data on AWS by Clarke Bishop 2h 12m
-
Visualizing Data on AWS by Mohammed Osman 34m
-
Securing Data Analytics Pipelines on AWS by Saravanan Dhandapani 1h 9m
Labs:
-
Calculate Read/Write Capacity Requirements For Using DynamoDB
-
Coursera 5 course by Whizlabs 5-7 hours each. No instructor name. Provides mainly theory.
-
https://aws.amazon.com/blogs/big-data/how-to-delete-user-data-in-an-aws-data-lake/
References
https://www.wikiwand.com/en/Timeline_of_Amazon_Web_Services
https://www.youtube.com/watch?v=tykcCf-Zz1M Top AWS Services A Data Engineer Should Know
- What is Data Pipeline
-
https://www.youtube.com/watch?v=7Xstz6Qo-pM Glue vs EMR
- Data Wrangling on AWS by Navnit Shukla, Sankar M, Sam Palani on Packt Publishing July 2023
Hands-on labs
https://cloudacademy.com/learning-paths/aws-certified-data-analytics-specialty-das-c01-certification-preparation-for-aws-1804/
https://registry.terraform.io/namespaces/terraform-aws-modules
https://www.educative.io/cloudlabs
https://www.montclair.edu/newscenter/2022/10/31/study-finds-hate-speech-on-twitter-increased-following-elon-musk-takeover/
https://github.com/mydatastack/google-analytics-to-s3
More on Amazon
This is one of a series about Amazon:
- AWS Cloud Services Comparisons
- AWS Well-Architected Cloud
- AWS Cloud Services
- AWS IAM
- AWS CLI
- AWS On-boarding (GUI, CLI, API)
- AWS Security
- AWS Data Tools
- AWS DevOps (CodeCommit, CodePipeline, CodeDeploy)
- AWS server deployment options
- AWS CDK
- Build load-balanced servers in AWS EC2
- AWS Networking
- AWS Xray
- IoT on AWS
- AWS Lambda
- AWS Lambda