

Obtain storage and database skills to pass DP-900, DP-100, DP-203, DP-300 exams
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
- Database models
- Database Activities
- SQL Language
- File formats
- Evolution
- End-to-end Projects
- Azure Storage products
- SQL Server Management Studio (SSMS)
- Azure Data Studio
- Azure’s SQL database products
- Azure Data Lake Storage Gen2 Storage
- Other Azure services:
- DP-900 Azure Data Fundamentals
- DP-100 Azure Data Scientist Associate
- DP-203: Azure Data Engineer Associate
- DP-300 Azure Data Administrator Associate
- DP-500: Azure Enterprise Data Analyst Associate
- RBAC Permissions
- Data Wrangling
- Data transformations
- SQL Server (IaaS in VM)
- Azure SQL (PaaS)
- Create SQL database using Portal GUI
- Data Flows
- Data Lifecycle
- ACID Properties in Transactional data
- Cosmos DB
- Databricks
- HDInsight
- MongoDB
- SQL Server Management Studio (SSMS)
- ADF (Azure Data Factory)
- Azure Synapse Analytics
- ADF
- Azure Synapse Analytics
- Connectors
- PowerBI
- Microsoft Graph
- Social community
- Resources
- More about Azure
This is a hands-on step-by-step tutorial I would give to a developer or administrator getting up and running managing data in the Azure cloud.
This are my notes to study for specific data-related Azure certification exams:
- DP-900: Azure Data Fundamentals
- DP-100: Azure Data Scientist Associate
- DP-203: Azure Data Engineer Associate (replaces DP-200 & DP-201)
- DP-300: Azure Database Administrator Associate
- DP-420: Azure Cosmos DB Developer Specialty
- DP-500: Azure Enterprise Data Analyst Associate
- DP-600: Fabric Analytic Engineer Associate
These replace certifications about Microsoft on-prem. technologies SQL-Server and SSIS retired Jan 31, 2021: z
Datasets have been renamed to “semantic models”.
NOTE: Content here are my personal opinions, and not intended to represent any employer (past or present). “PROTIP:” here highlight information I haven’t seen elsewhere on the internet because it is hard-won, little-know but significant facts based on my personal research and experience.
Data is a valuable asset to organizations.
“Data is the oil of the 21st century, and analytics is the combustion engine.” – Peter Sondergaard, Gartner Research Sr VP.
DEFINITIONS: A data lake holds raw data. A data warehouse holds structured information.
Database models
Over time, data has been organized in different ways to better suit different ways to access data for reports and dashboards:
Traditionally, limitations in CPU and memory size required different database structures for different purposes. For OLTP (Online Transaction Processing), data is stored for fast ingestion in rows with columns.

The types of databases are: Key-value -> Column -> Document -> Relational (SQL) -> Graph < Deltalake
| Types: | Key-value | Column | Document | Relational | Graph | Deltalake |
|---|---|---|---|---|---|---|
| Complexity | low | low | low | moderate | high | high |
| Performance | high | high | high | tuned | variable | high |
| Scalability | high | high | high / variable | high | variable | high |
| Flexibility | high | moderate | high | high | high | high |
Not listed are Vector databases used to hold embeddings in AI/ML LLMs.
A competitor to Delta metadata layer on top of Parquet is Apache Iceberg, used by Snowflake, Cloudera, and Google’s BigLake.
Python’s pandas library was built using numpy as a backend for dataframe libraries. So one of the major limitations in pandas is in-memory processing for larger datasets. However, pandas 2.0 includes Apache Arrow for in-memory columnar handling by PyArrow, which is based on the C++ implementation of Arrow, and therefore, fast.
Database Activities
Not every activity can be done by each data store:
- Copy (source/sink)
- Mapping Data Flow (source/sink)
- Lookup
- Get Metadata
- Delete
- Manage private endpoint
SQL Language
My notes about the SQL language is here.
Synapse SQL is a distributed version of T-SQL, with extensions for streaming and machine learning (T-SQL PREDICT function).
File formats
Unstructured:
- Binary blobs (pdf, jpg, png, mp3, mp4, etc.)
- Containers: (with Blob index tags metadata)
- Block (ADLSGen2 hierarchical namespace, NFS, SFTP)
- Page (random additions)
- Append (for logs)
- Tables (row-based entities)
- Queues (FIFO = First In First Out) messages
- Files (SMB = Server Message Block)
Semi-structured:
- Delimited text format (CSV)
- XML format
- Excel (proprietary and XML)
- JSON format
Structured:
- Common Data Model (CDM) format Dataverse
Within Apache Spark, Hadoop “Big data” evolved from the underlying format of files used to store data:
- RCFile (Record Columnar File) is a data placement structure designed to provide a fast serialized columnar data format for Hadoop. It was created at Facebook. It is a flat file format that is optimized for large flat table scans. It is not a block-based file format like ORC or Parquet. It is a row-based file format.
- ORC (Optimized Row Columnar) stores Hive data efficiently
- Avro (row-based)
-
Apache’s Parquet file format is freely licensed by the Linux Foundation DeltaLake adopted by Apache Spark and Azure Synapse. PROTIP: Parquet generally performs better than CSV because it provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. It is called a “columnar” storage format similar to other columnar-storage file formats available in Hadoop (RCFile and ORC). So it is compatible with most data processing frameworks in the Hadoop environment.
- Delta format
Evolution
Wide availability of fast internet and public clouds providing a lot of fast data storage and compute has enabled a revolution in how data can be stored and accessed.
-
“Distributed database” can now span multiple regional data centers (horizontally scalable), yet globally immediately consistent. Released in 2017 (Microsoft Azure Cosmos DB, Postgres Citus, Google Cloud Spanner)
-
“Deltalake” is a revolution because instead of arranging data in tables or graphs data for easier access, data is stored in Parquet format used by Azure Data Lake Storage Gen2, Hadoop, Databricks, Snowflake
References:
- https://www.upsolver.com/blog/apache-parquet-why-use
- https://docs.azure.com/en-us/azure/architecture/browse/#databases
On Windows VMs, Benchmark your disks using the DISKSP tool
OLAP Analytics
For OLAP (Online Analytical Processing), large amounts of data are stored in a “star schema” in data warehouses (separate from databases for OLTP) for access to by date and other dimensions.

-
Descriptive analytics describe what has happened based on historical data such as report of sales.
- Key Performance Indicators (KPI)
- Return on Investment (ROI)
- Balanced Scorecard (BSC) financials
- Mean Time to Repair (MTTR)
- etc.
-
Diagnostic analytics diagnose why it happened (causes) based on drill-downs to see relative contribution to sales by region, by product, by salesperson. Find anomalies.
-
Predictive analytics predict what might happen based regression of historical data revealing trends.
-
Prescriptive analytics prescribe (recommend) what to do based forecasts on the what might happen.
- Projections such as weather reports give the likelihood of events (such as rain) based on historical patterns.
- Optimization is used to find the best solution to a problem.
- Simulation is used to predict the impact of a decision.
- Heuristics are used to find a solution that is “good enough” but not necessarily the best.
-
Cognitive analytics cogitate about what if these happen by analyzing the possible consequences of various courses of action based on inferences - beyond decision trees.
- Self-driving vehicles calculate what to do based on predictions about all the objects that might move around it.
- Generative AI (GAN) to create new images, videos, text, and audio use “Transformers” to understand the context of words based on the likelihood of words appearing together.
- “Reinforcement learning” to learn from experience.
- “war games”
End-to-end Projects
First look at traditional SQL “relational” databases.
Azure Storage products
- STAR VIDEO: by John Savill
Microsoft has these offerings in the storage category:
- Archive Storage - Industry leading price point for storing rarely accessed data [DOCS]
- Avere vFXT for Azure - Run high-performance, file-based workloads in the cloud [DOCS]
- Azure Backup - Simplify data protection and protect against ransomware [DOCS]
- Azure confidential ledger - Tamperproof, unstructured data store hosted in trusted execution environments (TEEs) and backed by cryptographically verifiable evidence [DOCS]
- Azure Container Storage - Manage persistent volumes for stateful container applications [DOCS]
- Azure Data Lake Storage - Massively scalable, secure data lake functionality built on Azure Blob Storage [DOCS]
- Azure Data Share - A simple and safe service for sharing big data with external organizations [DOCS]
- Azure Elastic SAN (Preview) - Elastic SAN is a cloud-native Storage Area Network (SAN) service built on Azure. Gain access to an end-to-end experience like your on-premises SAN. [DOCS]
- Azure Files - Simple, secure and serverless enterprise-grade cloud file shares using SMB v3 protocol [DOCS]
- Azure FXT Edge Filer - Hybrid storage optimization solution for HPC environments [DOCS]
- Azure HPC Cache - File caching for high-performance computing (HPC) [DOCS]
- Azure Managed Lustre - A fully managed, cloud-based parallel file system that enables customers to run their high-performance computing (HPC) workloads in the cloud [DOCS]
- Azure NetApp Files - Enterprise-grade Azure file shares, powered by NetApp [DOCS]
- Blob Storage - REST-based object storage for unstructured data [DOCS]
- Data Box - Appliances and solutions for offline data transfer to Azure [DOCS]
- Disk Storage - High-performance, highly durable block storage for Azure Virtual Machines [DOCS]
- Queue Storage - Effectively scale apps according to traffic [DOCS]
- Storage - Durable, highly available, and massively scalable cloud storage [DOCS]
- Storage Explorer - View and interact with Azure Storage resources [DOCS]
- StorSimple - Lower costs with an enterprise hybrid cloud storage solution [DOCS]
DEMO: Create Blob and File storage
https://www.techtarget.com/searchstorage/tutorial/How-to-create-an-Azure-Data-Lake-Storage-Gen2-account
https://www.techtarget.com/searchstorage/tip/Compare-Azure-Blob-Storage-vs-Data-Lake
- Create a storage account. REMEMBER: Name must be 24 characters or less.
- For Performance: when selecting Premium (SSD) for low latency:
- “File shares: Best for enterprise or high-performance applications that need to scale”, and scenarios that require a fully SMB-compatible file system.
- “Block blobs: Best for high transaction rates or low storage latency”, storing large amounts of text or binary data, storing data for streaming and storing data for backup and restore scenarios.
- “Page blobs: Best for random read/write operations” and frequent read/write operations in small ranges.
- “Append blobs
Factor: Block blobs Page blobs Append blobs Usage: binary streaming, backups infrequent change frequent random read/write logging Max size: 4.7 TB 8 TB 195 GB Max block: 100 MB 512 pages ? Max blob: 50,000 blocks virtual 4 MB Redundancy
-
For Redundancy: (to achieve disaster recovery): [DOCS]
-
LRS = Locally Redundant Storage (HDD): “Lowest-cost option with basic protection against server rack and drive failures. Recommended for non-critical scenarios.” Data is replicated three times within a single facility in a single region.
-
LRS premium (Premium SSD) : “Lowest-cost option with basic protection against server rack and drive failures. Recommended for non-critical scenarios.”
Data is replicated three times within a single facility in a single region. -
ZRS = Zone-redundant storage : “Intermediate option with protection against datacenter-level failures. Recommended for high availability scenarios.”
Data is replicated synchronously across three Azure availability zones in a single region. -
GRS = Geo-redundant storage : “Intermediate option with failover capabilities in a secondary region. Recommended for backup scenarios.”
Data is replicated synchronously across three Azure availability zones in a single region, and then asynchronously to a paired region. -
GZRS = Geo-zone-redundant storage : “Optimal data protection solution that includes the offerings of both GRS and ZRS. Recommended for critical data workloads.”
Data is replicated synchronously across three Azure availability zones in a single region, and then asynchronously to a paired region that is geographically distant from the primary region. -
RA-GRS = Read-Access Geo-Redundant Storage : GRS plus read access to the secondary region. Recommended for scenarios requiring read access in the secondary region.
Data is replicated synchronously across three Azure availability zones in a single region, and then asynchronously to a paired region that is geographically distant from the primary region. -
RA-ZGRS = Read-Access Geo-Zone-Redundant Storage : GZRS plus read access to the secondary region. Recommended for scenarios requiring read access in the secondary region.
“Data is replicated synchronously across three Azure availability zones in a single region, and then asynchronously to a paired region that is geographically distant from the primary region. This is the Highest-cost option with the highest level of availability and durability.
-
-
If “Read-access geo-redundant storage (RA-GRS)” is selected, also check “Make read access to data available in the event of regional unavailability”
PROTIP:
 PRICING for data storage is based on several factors. But the basic cost of the first 50 TB of LRS Hot Hierarchical Gen2 storage, by Region/Location, in $/GB/Month USD. According to my calculations (in an Excel file) on Dec 8, 2023:
PRICING for data storage is based on several factors. But the basic cost of the first 50 TB of LRS Hot Hierarchical Gen2 storage, by Region/Location, in $/GB/Month USD. According to my calculations (in an Excel file) on Dec 8, 2023:Brazil Southeast (in red) is the most expensive – 2.35 times the cost of the cheapest region (shown in dark green).
That’s before adding costs for reservations, time lengths, Data egress fees, etc. which can be substantial and dramatically impact the storage budget.
SQL Server Management Studio (SSMS)
SSMS is integrated to visualize and work with Azure SQL, including SQL Server in virtual machines, SQL managed instances, and SQL databases. When necessary, SSMS shows only options that work for a specific Azure service.
https://docs.azure.com/en-us/sql/ssms/download-sql-server-management-studio-ssms Installer
Azure Data Studio
Azure Data Studio is an open-source, cross-platform client GUI tool for querying and working with various Azure data sources, including SQL Server and Azure SQL. Its “notebooks” allows mixing runnable code cells and formatted text in one place.


https://docs.azure.com/en-us/sql/azure-data-studio/download-Azure-data-studio
Azure’s SQL database products
-
With a Subscription, search for Azure service “SQL” at the top of the page to see that there are many services offered directly and from the Marketplace:
-
HANDS-ON: Select “Azure SQL”, which is an “umbrella” service offering different ways Azure provides SQL software [DOCS]
A. “SQL virtual machines” (VMs) to lift-and-shift of SQL Server machines (along with Microsoft licenses) from on-prem. data centers. “High availability” (with automatic backups) is an option to enable Disaster Recovery (DR). Here you manage (potentially obsolete) SQL Server and OS-level settings/configurations. [DOCS]
- SQL Server 2022 Enterprise on Windows Server 2022?
- SQL Server 2019 Enterprise on Windows Server 2019 (and earlier 2014, 2017)?
B. “SQL managed instances” are managed by Microsoft to provide always-up-to-date OSs managed by Azure. Used for “Arc” running Azure on customer on-prem. data centers. [DOCS]
C. Azure “SQL databases” are totally managed by Microsoft in its Azure cloud as serverless hyperscale infrastructure designed to be fault-tolerant and highly available [DOCS] The different “SQL database” options:
- Single (SQL) database
- Elastic pool to manage and scale multiple databases with varying and unpredictable usage patterns, sharing a single set of resources (at a prescribed budget). [DOCS] NOTE: Dedicated SQL pools (formerly SQL DW)
- Database server

- on-prem “SQL Server stretch databases” stretches (migrates in the background) cold SQL data to the Azure cloud Deprecated in SQL Server 2022 (16.x) and Azure SQL Database
Among Marketplace services:
- Azure Synapse Analytics
- SQL server (logical server)?
- Web App + Database?
Open-source SQL Managed database service (for app developers) not shown on the menu but listed in
- Azure Databases page.
-
offerings in the databases category:
- Azure Database for MySQL - One of the earliest open-sourced databases. Acquired by Sun then Oracle. It’s a pure relational database, easy to setup, use, and maintain. Has multiple storage engines (InnoDB and MyIsam) [DOCS]
- Azure Database for MariaDB - a fork of MySQL [DOCS]
- Azure Database for PostgreSQL - evaloved from the Ingres project at UCLA. The most advanced open-source object-relational database with single storage engine. It supports full text search, table inheritance, triggers, rows, data types, etc. [DOCS]
Other choices not shown on the menu:
- Azure Databricks?
- Azure SQL Edge - Small-footprint, edge-optimized data engine with built-in AI [DOCS]
- Table Storage - NoSQL key-value store using semi-structured datasets [DOCS]
- Postgres Citus is an open-source extension that transforms Postgres into a hyperscale distributed database. It scales out PostgreSQL across multiple nodes using sharding and replication beyond 100 GB for SaaS apps that need to scale for multi-tenants and real-time analytics. It’s not a good fit for transactional workloads, apps that require complex SQL queries or require a lot of data transformations.
Non-SQL databases not shown on the menu:
- Azure Cache for Redis - Power applications with high-throughput, low-latency data access [DOCS]
- Azure confidential ledger - Tamperproof, unstructured data store hosted in trusted execution environments (TEEs) and backed by cryptographically verifiable evidence [DOCS]
- Azure Cosmos DB - Fast NoSQL database with open APIs for any scale [DOCS]
- Azure Database Migration Service - Simplify on-premises database migration to the cloud [DOCS]
- Azure Managed Instance for Apache Cassandra - Automate deployment and scaling for managed open-source Apache Cassandra datacenters [DOCS]
-
Select a Resource group.
-
Click “Accept offer” of first 100,000 vCore seconds and 32GB of data & 32GB of backup storage free per month for lifetime of the subscription.
https://learn.microsoft.com/en-us/azure/azure-sql/database/free-offer?view=azuresql
-
Compose Database name with a data.
-
Compose Server name with a date suffix to make it unique, such as:
wow-westus-231207a.database.windows.net
- Select the Location.
- Select Authentication method.
-
Set Microsoft Entra admin. Click Select.
Connection Policy
-
On the Create SQL Database page, select Next :Networking >, and on the Networking page, in the Network connectivity section, select Public endpoint. Then select Yes for both options in the Firewall rules section to allow access to your database server from Azure services and your current client IP address.
- “Redirect” within the Azure network
- “Proxy” (through a gateway via port 1443) for access outside the Azure network - Allow access from any IP address
Server Firewall rules can also be set using T-SQL:
EXECUTE sp_set_database_firewall_rule N'OnlyAllowServer','0.0.0.4','0.0.0.4';
Defender
“Microsoft Defender” is a suite of “unified” offerings to discover and classify sensitive data, protect data and respond to data risks in Azure SQL Database and Azure Synapse Analytics. It’s a unified solution that includes Azure SQL Database Advanced Threat Protection (ATP) and Azure SQL Database Vulnerability Assessment (VA). It’s built into Azure SQL Database and Azure Synapse Analytics, enabled by default. It’s also available for Azure SQL Managed Instance and SQL Server on Azure Virtual Machines. [DOCS]
-
Select Next: Security > and set the Enable Microsoft Defender for SQL option to “Not now” during testing.
-
Select Next: Additional Settings > and on the Additional settings tab, set the Use existing data option to Sample (this will create a sample database that you can explore later).
PROTIP: Note the Admin Object/App ID GUID.
-
Click OK to create the database. Click “Review + Create”. Click “Create”.
In the Deployment page, notice the resources created with the various IDs on the right pane.
- Click “Go to resource”.
 Click for full screen
Click for full screenAzure Data Lake Storage Gen2 Storage
Gen2 has the concept of having a single format to hold various “layers” in a new “Medallion architecture” defined by Databricks:
-
The Bronze layer contains raw data layer as loaded “as is” from the source, such as ADF. Thus, this is also called a “Landing Zone”. This layer provides a historical archive of source (cold storage), data lineage, auditability, and reprocessing if needed without rereading the data from the source system.
-
The Silver layer contains filtered, cleaned, and augmented data that ends up having a clean schema after traditional ETL processing.
-
The Gold layer contains curated business-level aggregated data, such as what was in “Kimball-style star schema” analytics data warehouses ready to be read by OLAP, Business Intelligence (BI) and Machine Learning/AI models to make predictions.

Other Azure services:
- Azure Data Factory (ADF)
- Stream Analytics
- A Data Lakehouse holds raw data after ingestion. Gen2 big data analytics with Hadoop compatible access built on Azure Blob storage with a superset of POSIX permissions
- A Data Lake House (like Databricks) makes use of Spark data warehouse
1-day course DP-601T00—A: Implementing a Lakehouse with Microsoft Fabric
DP-900 Azure Data Fundamentals
$99 DP-900 Microsoft Azure Data Fundamentals exam page provides free tutorials to answer 40-60 multiple-choice questions (no cases) in 180-minutes (3 hours).
LEARN: Core data concepts (15-20%)
- Describe ways to represent data:
- Describe features of structured data
- Describe features of semi-structured
- Describe features of unstructured data
- Identify options for data storage:
- Describe common formats for data files
- Describe types of databases
- Describe common data workloads:
- Describe features of transactional workloads
- Describe features of analytical workloads
- Identify roles and responsibilities for data workloads
- Describe responsibilities for database administrators
- Describe responsibilities for data engineers
- Describe responsibilities for data analysts
LEARN: Explore relational data in Azure (25-30%)
- Describe relational concepts:
- Identify features of relational data
- Describe normalization and why it is used
- Identify common structured query language (SQL) statements
- Identify common database objects
- Describe relational Azure data services:
- Describe the Azure SQL family of products including Azure SQL Database, Azure SQL Managed Instance, and SQL Server on Azure Virtual Machines
- Identify Azure database services for open-source database systems
LEARN: Explore non-relational data in Azure (25-30%)
- Describe capabilities of Azure storage:
- Describe Azure Blob storage
- Describe Azure File storage
- Describe Azure Table storage
Describe capabilities and features of Azure Cosmos DB
- Identify use cases for Azure Cosmos DB
- Describe Azure Cosmos DB APIs
LEARN: VIDEO: Explore analytics in Azure (25-30%)
- Describe common elements of large-scale analytics:
- Describe considerations for data ingestion and processing
- Describe options for analytical data stores
- Describe Azure services for data warehousing, including Azure Synapse Analytics, Azure Databricks, Azure HDInsight, and Azure Data Factory
- Describe consideration for real-time data analytics:
- Describe the difference between batch and streaming data
- Describe technologies for real-time analytics including Azure Stream Analytics, Azure Synapse Data Explorer, and Spark Structured Streaming
- Describe data visualization in Microsoft Power BI:
- Identify capabilities of Power BI
- Describe features of data models in Power BI
- Identify appropriate visualizations for data
NOTE: Underlying data models can be viewed and modified for Interactive Reports, but not with Dashboards.
For dashboards, the PowerBI cloud service is at https://app.powerbi.com/home
-
A Power BI dashboard is a single-page “canvas” that tells a story through visualizations.
-
A dashboard contains several tiles, each a snapshot of data, pinned to the dashboard, created from a report dataset, dashboard, Q&A box, Excel, SQL Server Reporting Services (SSRS), or a streaming dataset.
$1599 1-day (8 hour) course SC-900T00–A: Microsoft Security, Compliance, and Identity Fundamentals provides live training with labs at https://learn.microsoft.com/en-us/collections/0kjyh8rn5gdrjj and https://microsoftlearning.github.io/DP-900T00A-Azure-Data-Fundamentals/ and assets downloaded from: https://github.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals to Explore…
- Azure SQL Database
- Azure Database for PostgreSQL
- Azure Cosmos DB
- Data analytics in Azure with Azure Synapse Analytics
- Azure Stream Analytics
- Spark Streaming in Azure Synapse Analytics
- Azure Synapse Data Explorer
- Real-time analytics in Microsoft Fabric
- Fundamentals of data visualization with Power BI
The Skillpipe associated with the one-day Azure live course DP-900T00 roughly covers the above topics using github.com/azureLearning/DP-900T00A-Azure-Data-Fundamentals/tree/master/Instructions which redirects to a free “Azure Learn Sandbox” Directory in Azure:
01-Provision-Azure-relational-database-services.md (4 hours) Databases (Community Edition):
- Azure SQL Database
- Azure Database for PostgreSQL
- Azure Database for MySQL
02-Use-SQL-to-query-Azure-SQL-Database.md
03-Provision-non-relational-Azure-data-services.md
04-Upload-download-and-query-data-in-a-non-relational-data-store.md
PROTIP: BTW Left out of the ESI list is Azure Databricks, a cloud-scale platform for data analytics and machine learning. Microsoft’s live class DP-090 “Implementing a Machine Learning Solution with Microsoft Azure Databricks” shows how to use Azure Databricks to explore, prepare, and model data; and integrate Databricks machine learning processes with Azure Machine Learning.
Sample DP-900 Exams:
- Pearson’s sample test on OReilly.com provides filtering of questions by domain
- $14.99 Udemy
- https://www.whizlabs.com/azure-Azure-certification-dp-900/
- by Clearcat.net
- by The Tech BlackBoard
Other Tutorials:
At Pluralsight: Microsoft Azure Data Fundamentals (DP-900)
-
Getting Started with Azure Data Workloads by Henry Been (henrybeen.nl)

-
Data Literacy: Essentials of Azure Data Factory by Emilio Melo Apr 7, 2021
-
Data Literacy: Essentials of Azure HDInsight by Niraj Joshi Mar 22, 2021
-
Data Literacy: Essentials of Azure Databricks by Dayo Bamikole Apr 26, 2021
-
Data Literacy: Essentials of Azure Synapse Analytics By Mohit Batra June 14, 2021
CloudAcademy: https://cloudacademy.com/exam/landing/37208/ has Knowledge checks.
On LinkedIn Learning:
- 3 courses over 3 hours by Gregor Suttie, Adam Wilbert, Keith Atherton
On OReilly.com:
-
Video Course with Practice Questions by Fnu Eshant Garg, from Packt March 2022 uses https://github.com/PacktPublishing/DP-900-Microsoft-Azure-Data-Fundamentals-Video-Course-Ques
-
live crash course by Emilio Melo
-
“Cloud and Azure Overview” section in Azure Overview: Introduction for Beginners (video)
-
Professional Azure SQL Database Administration (video, 4h 58m)
-
Create an Azure SQL Data Warehouse in Minutes (video, 1h 22m)
-
Information Management Using Azure Data Factory (video, 1h 16m)
On YouTube:
- 1.3-hr “Full course” from Piyush 2021
- 2.5-hour Full Course from Susanth Sutheesh
- 4-hour from Andrew Brown (CloudSkills.io) - with some struggling
- 2-hour “Full Class” from Tech Tutorials with Piyush Sachdeva
-
2-hour Study Cram from John Savill
- 34 min. “Actual Exam Questions” from CertyIQ
- 2-hour “Exam Dumps” from Clearcat.net
-
2:29 Real Exam Questions for each part from The Tech BlackBoard
- Channel list of Adam Marczak
DP-100 Azure Data Scientist Associate
Earn the DP-100 “Azure Certified: Azure Data Fundamentals” certification by passing the one $99 exam. Describe …
4-day course DP-100T01–A: Designing and implementing a data science solution on Azure
PROTIP: FREE LEARNING PATH: Build AI solutions with Azure Machine Learning is 9 hr 51 min. It has hands-on exercises which references https://github.com/MicrosoftLearning/mslearn-dp100
DP-203: Azure Data Engineer Associate
NOTE: DP-203 replaces DP-200 & DP-201.
To be an Azure Certified: Azure Data Engineer Associate, pass the single DP-203 exam, which covers the following products:
- Azure Synapse Analytics
- Azure Data Factory
- Azure Stream Analytics
- Azure Event Hubs
- Azure Data Lake Storage
- Azure Databricks
The 4-day course DP-203T00–A: Data Engineering on Microsoft Azure makes use of lab instructions in English at aka.ms/dp203labs = microsoftlearning.github.io/dp-203-azure-data-engineer:
- Explore Azure Synapse Analytics Lab
- Query files using a serverless SQL pool Suggested demo
- Transform data using a serverless SQL pool Lab
- Analyze data in a lake database Suggested demo
- Analyze data in a data lake with Spark Suggested demo
- Transform data using Spark in Synapse Analytics Lab
- Use Delta Lake in Azure Synapse Analytics Lab
- Explore a relational data warehouse Suggested demo
- Load Data into a Relational Data Warehouse Lab
- Build a data pipeline in Azure Synapse Analytics Lab
- Use an Apache Spark notebook in a pipeline Lab
- Use Azure Synapse Link for Azure Cosmos DB Lab
- Use Azure Synapse Link for SQL Suggested demo
- Get started with Azure Stream Analytics Suggested demo
- Ingest realtime data with Azure Stream Analytics and Azure Synapse Analytics Lab
- Create a realtime report with Azure Stream Analytics and Microsoft Power BI Suggested demo
- Use Microsoft Purview with Azure Synapse Analytics Lab
- Explore Azure Databricks Suggested demo
- Use Spark in Azure Databricks Lab
- Use Delta Lake in Azure Databricks Optional demo
- Use a SQL Warehouse in Azure Databricks Optional demo
- Automate an Azure Databricks Notebook with Azure Data Factory Suggested demo
Microsoft’s $99 DP-203 exam page include free tutorials.
- LEARN: Design Azure data storage solutions (40-45%)
- LEARN: Design data processing solutions (25-30%)
- LEARN: Design for data security and compliance (25-30%)
Crash Course Jan. 16, 2024 by Tim Warner
DP-300 Azure Data Administrator Associate
To be an Azure Certified: Azure Database Administrator Associate, pass the single DP-300.
The 4-day course DP-300T00–A: Administering Microsoft Azure SQL Solutions references (free) lab instructions in English at aka.ms/dp300labs = https://microsoftlearning.github.io/dp-300-database-administrator/. Modules and Exercise:
- Setup your own environment
Plan and Implement Data Platform Resources- Lab 1 - Provision SQL Server on an Azure Virtual Machine
- Lab 2 - Provision an Azure SQL Database
Implement a Secure Environment for a Database Service: - Lab 3 - Authorize access to Azure SQL Database with Azure Active Directory
- Lab 4 - Configure Azure SQL Database firewall rules
- Lab 5 - Enable Microsoft Defender for SQL and Data classification
Monitor and optimize operational resources in Azure SQL: - Lab 6 - Isolate performance problems through monitoring
- Lab 7 - Detect and correct fragmentation issues
Optimize query performance in Azure SQL: - Lab 8 - Identify and resolve blocking issues
- Lab 9 - Identify database design issues
- Lab 10 - Isolate problem areas in poorly performing queries in a SQL Database
Automate database tasks for Azure SQL: - Lab 11 - Deploy Azure SQL Database using Azure Resource Manager template
- Lab 12 - Create a CPU status alert for a SQL Server
- Lab 13 - Deploy an automation runbook to automatically rebuild indexes
Plan and implement a high availability and disaster recovery solution: - Lab 14 - Configure geo-replication for Azure SQL Database
- Lab 15 - Backup to URL and Restore from URL MicrosoftLearning/dp-300-database-administrator
References:
-
Lab 1: Using the Azure Portal and SQL Server Management Studio - explore the Azure Portal and use it to create an Azure VM with SQL Server 2019 installed. Connect to the virtual machine through RDP (Remote Desktop Protocol) and restore a database using SSMS (SQL Server Management Studio).
-
DP-300_02_lab - Lab 2 - Deploying PaaS databases - configure and subsequently implement security in the Azure Portal and within the AdventureWorks database. configure basic resources needed to deploy an Azure SQL Database with a Virtual Network Endpoint. Connectivity to the SQL Database will be validated using Azure Data Studio from the lab VM. Finally, an Azure Database for PostgreSQL will be created.
-
Plan and implement data platform resources (LEARN)
-
Implement a secure environment for a database service (INTRO, LEARN, Lab 3)
-
Monitor and optimize operational resources (LEARN, Lab 4) - scope out deliverables for a digital transformation project within AdventureWorks. Examining the Azure portal as well as other tools, determine how to utilize native tools to identify and resolve performance related issues. Identify fragmentation within the database as well as learn steps to resolve the issue appropriately.
-
Optimize query performance (LEARN, Lab 5) - evaluate a database design for problems with normalization, data type selection and index design. Run queries with suboptimal performance, examine the query plans, and attempt to make improvements within the AdventureWorks2017 database.
-
Perform automation of tasks (LEARN, Lab 6) - take the information gained in the lessons to configure and subsequently implement automate processes within AdventureWorks.
-
Plan and implement a High Availability and Disaster Recovery (HADR) environment (LEARN, Lab 7) - execute two main tasks: make Azure SQL Database geo-redundant, and backup to and restore from a URL which uses Azure.
-
Perform administration by using T-SQL
DP-500: Azure Enterprise Data Analyst Associate
Microsoft’s $165 DP-500 Azure Enterprise Data Analyst Associate exam page provides free tutorials to get advanced Power BI skills, including managing data repositories and data processing in the cloud and on-premises, along with using Power Query and Data Analysis Expressions (DAX). You should also be proficient in consuming data from Azure Synapse Analytics and should have experience querying relational databases, analyzing data by using Transact-SQL (T-SQL), and visualizing data.
The 4-day course DP-500T00–A: references (free) labs using these files.
- Setup your own environment on Windows 11:
- Microsoft Edge
- Git
- SQL Server Management Studio
- Power BI Desktop (April 2023)
- Power BI Report Builder
- Model, query, and explore data in Azure Synapse
- Query files using a serverless SQL pool
- Analyze data in a data lake with Spark
- Explore a relational data warehouse
- Prepare data for tabular models in Power BI
- Create a star schema model
- Create a dataflow
- Design and build tabular models
- Work with model relationships
- Create calculation groups
- Create a composite model
- Enforce model security
- Optimize enterprise-scale tabular models:
- Improve performance with hybrid tables
- Improve query performance with dual storage mode
- Improve query performance with aggregations
- Use tools to optimize Power BI performance
- Implement advanced data visualization techniques by using Power BI:
- Monitor data in real time
- Manage the analytics development lifecycle:
- Create reusable Power BI assets
RBAC Permissions
SQL DB Contributor:
- manage SQL database
- can’t manage their security-related policies or their parent SQL servers
SQL Managed Instance Contributor:
- manage SQL-managed instances and required network configuration
- can’t give access to others
SQL Security Manager:
- manage security-related policies of SQL servers and databases
- no access to SQL servers
NOTE: SQL Security Manager is not available for SQL-Managed instances.
Data Wrangling
The process of transforming and mapping data from a “raw” form to another format, to make it more appropriate and valuable for a variety of downstream purposes such as analytics. AKA “data munging”.
- Discovery - of domain-specific details
- Structuring - for ease of work
- Cleaning - remove outliers and duplicates, special characters, change null values, standardize formatting.
- Enriching - with relevant context obtained from additional sources.
- Validating - authenticate the reliability, quality, and safety of the data
- Publishing - in a datastore for use downstream.
Data transformations
- Filter and Sort rows
- Pivot and Unpivot
- Merge and Append queries
- Split and Conditional split
- Replace values and Remove duplicates
- Add, Rename, Reorder, or Delete columns
- Rank and Percentage calculator
- Top N and Bottom N
SQL Server (IaaS in VM)
Traditionally, SQL Server 2019 software run within a single Azure VM (IaaS) instance. This is still the approach for large (64TB) SQL databases.
Create Instance
- Among services, search for “SQL”. Select “Azure SQL”.
- Click “Create Azure SQL resource”.
- Among “SQL databases”, select “Single database”.
- Select Subscription.
- Resource group: “Create new” and enter “sql-rg”.
- For Database name,
- For Server, click “Create new” for the sub-form.
- For Server name, include a project and date.
- For Server admin login, generate one and save it in a password manager.
- For Location, see my notes (to avoid cross-region networking charges).
-
Click OK to dismiss the sub-form.
- For “Want to use SQL elastic pool?”, select “No”.
- For Compute + storage, select “Configure database” if you don’t the default “Gen5, 2 vCores, 32 GB”.
- Make the selections according to my notes about Service Tiers. Click “Apply”.
-
Click “Networking” tab. Select Connectivity method “No Access”. It’s safer to make it a Public endpoint later.
- Click “Additional settings” tab.
- For “Use existing data”, click “Sample” during this demo for “AdventureWorksLT”.
-
For “Collation”, select “SQL_Latin1_General_CP1_CI_AS”.
- CLick “Tags” tab.
- Click “Review + create” tab to start Deployment.
Connect to server
SQL agent jobs back up directly to a URL linked to Azure blob storage. Azure provides the option to use redundancy options to ensure that backup files are stored safely across the geographic landscape:
Additionally, as part of the Azure SQL VM service provider, you can have your backups automatically managed by the platform.
SQL Server provides access to the underlying OS, but that also means you need to keep that OS updated. Additionally, the SQL Server IaaS Agent Extension reduces your administrative overhead:
- SQL Server automated backup
- SQL Server automated patching
- Azure Key Vault integration
When used in conjunction with Azure managed storage, a single Azure Virtual Machine provides three nines (99.9%) of high availability. That a downtime of no more than 8.77 hours each year.
In addition to Availability Groups for Virtual Machines for disaster recovery, SQL Server has two major options for high availability:
- Always On availability groups and
- Failover Cluster Instances.

References:
- https://github.com/azure/sqlworkshops-sql2019workshop to learn about the latest innovations available in SQL Server 2019
Always On availability groups (AG)
Always On availability groups are implemented between two to nine SQL Server instances running on Azure virtual machines or across Azure or an on-premises data center.
Database transactions are committed to the primary replica, and then the transactions are sent to all secondary replicas.
Transactions are sent in either synchronously or asynchronously availability mode, based on physical distance between servers.
- If the workload requires the lowest possible latency or the secondary replicas are geographically spread apart, asynchronous availability mode is recommended.
- If the replicas are within the same Azure region and the applications can withstand some level of latency, synchronous commit mode should be considered. Synchronous mode ensures that each transaction is committed to one or more secondaries before allowing the application to continue.
Always On availability groups provide both high availability and disaster recovery, because a single availability group can support both synchronous and asynchronous availability modes. The unit of failover for an availability group is a group of databases, and not the entire instance.
SQL Server Failover Cluster instances
If you need to protect the entire instance, you could use a SQL Server Failover Cluster Instance (FCI), which provides high availability for an entire instance, in a single region. A FCI doesn’t provide disaster recovery without being combined with another feature like availability groups or log shipping. FCIs also require shared storage that can be provided on Azure by using shared file storage or using Storage Spaces Direct on Windows Server.
For Azure workloads, availability groups are the preferred solution for newer deployments, because the shared storage require of FCIs increases the complexity of deployments. However, for migrations from on-premises solutions, an FCI may be required for application support.
Azure SQL (PaaS)
VIDEO: Azure SQL for beginners
“Azure SQL Services” (for the cloud) was announced with Windows Azure in 2008.
In 2010, the “Azure SQL” PaaS was announced as a “cloud database offering that Azure provides as part of the Azure cloud computing platform. Unlike other editions of SQL Server, you do not need to provision hardware for, install or patch Azure SQL; Azure maintains the platform for you. You also do not need to architect a database installation for scalability, high availability, or disaster recovery as these features are provided automatically by the service.”
PaaS SQL is versionless.
In 2014 announced elastic database pools, vCore choices, business-critical deployments, hyperscale, and serverless architectures.
Service Tiers
Tiers for performance and availability using vCore pricing model:
Resource types:
- Single Azure SQL Database
- SQL Database / SQL Managed Instance
- SQL Database / SQL Managed Instance pools
| Service Tier | Max. Size | Latency | Avail. SLA |
|---|---|---|---|
| General Purpose | 4TB (8TB for Managed Instance) | 5-10 ms | 99.99% |
| Business Critical | 4TB | 1-2 ms (SSD) | 99.995% in 4-node ZRS cluster |
| Hyperscale | 100TB+ | instant backups | scales |
With Azure SQL Database, the SQL Managed Instance handles up to 8TB databases.
Hyperscale scales up and down quickly.
“Azure Database for MySQL, PostgreSQL” also supports MariaDB.
Data Migration Assistant can recognize when SQL Server Stretch Database migrates on-prem. cold table rows to Azure (to avoid buying more on-prem. storage). On-prem. backups can then bypass cold table rows (and run quicker).
Elastic Pool doesn’t work in Hyperscale.
Azure SQL Pricing
https://docs.azure.com/en-us/azure/sql-database/sql-database-service-tiers-dtu
The DTU (Database Transaction Unit) model isn’t available in Azure SQL Managed Instance.
DOCS: Instead of DTU, which has a bundled measure for pricing compute, storage, and IO resources, the vCore-based pricing model has independent charges for compute, storage, and I/O.
The vCore model also allows use of Azure Hybrid Benefit for SQL Server and/or reserved capacity (pay in advance) to save money. Neither of these options is available in the DTU model.
With the Serverless Compute Tier, if there is no activity, it pauses the database and halts compute charges.
SQL Database achieves HA with “Always ON Availability Groups” tech from SQL Server, which makes Failover automatic (but takes 30 seconds).
Up to 4 replicas can become the primary, as long as secondaries have the same user authentication config. and firewall rules as the primary.
Backups by transaction log occur every 5-10 minutes. Backups are saved for 7 days by default (Basic plan), up to 35 days under Standard/Premium. Long-term Retention can be up to 10 years. Lowest RPO is one hour of data loss for RTO of up to 12 hours for geo-replication.
References:
- https://www.oreilly.com/library/view/pro-sql-server/9781484241288/ introduces SQL Server on Linux. In the process, it walks through topics that are fundamental to SQL Server.
Create SQL database using Portal GUI
LAB: Explore Azure SQL Database
-
In the portal, get the SQL databases blade after pressing G+\ or clicking the Home (3 line icon) at the top-left of the Portal.
-
”+ Create” to “Create SQL database”. The menu:
Basics Networking Security Additional settings Tags Review+Create
- Resource group:
- Database name: up to 128 characters, unique on same server.
- Server:
-
Want to use SQL elastic pool? Leave default: “No”.
Elastic pools have multiple Azure SQL Database instances share the same resources (memory, storage, processing). Elastic pools provide a simple and cost effective solution for managing the performance of multiple databases within a fixed budget. An elastic pool provides compute (eDTUs) and storage resources that are shared between all the databases it contains.
Databases within a pool only use the resources they need, when they need them, within configurable limits. The price of a pool is based only on the amount of resources configured and is independent of the number of databases it contains.
PROTIP: That means databases are charged for allocations, not usage.
- Compute + storage
Data Flows
For answers needed today and tomorrow …
Batch jobs - REMEMBER:
-
ETL = Extract, Transform, Load into SQL star databases with usage “schema on write” for faster read
-
ELT = Extract, Load, Transform = data saved as-is into NoSQL (document) databases with usage “schema on read” for greater scale and exploration<br /VIDEO Create a ELT job from Azure SQL to Blog Storage, using Data Factory, Author & Monitor.
-
Hybrid - data ingested on-prem, transformed in the cloud
Stream Processing (real-time)
Data Lifecycle
Pipelines:
- Collection of data
- Preparation of collected data
- Ingestion of data into storage
- Processing or transformation of data into a usable form
- Analysis of transformed data
ACID Properties in Transactional data
See https://www.sciencedirect.com/topics/computer-science/acid-properties
Atomicity - each transaction is treated as a single unit, which is successful completely or failed completely. The server would refuse transactions until the previous one has committed. Failed intermediate changes are backed-off (undone).
Consistency - transactions can only take the data in the database from one valid state to another. In a service: Azure Cosmos DB account page, levels:
- STRONG = reads are guaranteed to see the most recent write within a single region.
- BOUNDED STALENESS = for any read regions (along with a write region) - for applications featuring group collaboration and sharing, stock ticker, publish-subscribe/queueing etc.
- SESSION = (the most widely used) It provides write latencies, availability and read throughput comparable to that of eventual consistency but also provides the consistency guarantees that suit the needs of applications written to operate in the context of a user.
- CONSISTENT PREFIX = guarantees that reads never see out-of-order writes with throughput comparable to that of eventual consistency.
- EVENTUAL = (the least consistent) useful in applications that can tolerate staleness in the data being read, where a client may get older values for a limited time.
Isolation - concurrent execution of transactions leave the database in the same state.
Durability - once a transaction has been committed, it remains committed.
Cosmos DB
VIDEO: “Microsoft Azure Cosmos DB is a fully managed API service to provide a scale-out, operational database fabric that suits read-heavy apps, workloads that need to scale geographically and use cases where the application requires multiple data models”
- http://www.cosmosdb.com/
- https://twitter.com/AzureCosmosDB
- https://devblogs.microsoft.com/cosmosdb/tag/microsoft-fabric/
- https://learn.microsoft.com/en-us/answers/tags/187/azure-cosmos-db
- https://www.linkedin.com/company/azure-cosmos-db/
- https://www.linkedin.com/company/azure-cosmos/about/
- TRY FREE 30 days for NoSQL, MongoDB, Cassandra, PostgreSQL
- https://datamonkeysite.com/2023/05/27/first-impression-of-microsoft-fabric/
- https://www.linkedin.com/company/alpaqastudio/
- https://devblogs.microsoft.com/cosmosdb/announcing-azure-cosmos-db-mirroring-in-microsoft-fabric-private-preview/
- Oreilly: Getting Started with Microsoft Cosmos DB Using C#: Cloud Database Support for .NET Applications (video, 1h 2m)
Tutoriala:
BLOG: Cosmos began in 2010 as “Project Florence” to provide a globally distributed database service for Microsoft’s internal use. It was released to the public
The predecessor to Cosmos was announced in 2015 as “Azure DocumentDB” (like AWS), a NoSQL database that stores data in JSON documents for querying using SQL commands. To this day “Microsoft.DocumentDB” is the name of the Cosmos resource provider.
In 2017, Azure Cosmos DB is announced with global regions and multiple data models. read/write SLA announced for mission-critical app throughput, consistency, 99.999% availability, and < 10-ms latency.
VIDEO Creating and accessing different data models.
Cosmos DB Database Models
-
Search for service “Cosmos” for a list of services:
DEFINITION: “RU” = Request Units = 1KB of data read or written per second, when Provisioned throughput is selected.
-
PROTIP: Choose one data model:
-
Azure Cosmos DB for NoSQL - Azure Cosmos DB’s core, or native API for working with documents. Supports fast, flexible development with familiar SQL query language and client libraries for .NET, JavaScript, Python, and Java.
-
Azure Cosmos DB for PostgreSQL - Fully-managed relational database service for PostgreSQL with distributed query execution, powered by the Citus open source extension. Build new apps on single or multi-node clusters—with support for JSONB, geospatial, rich indexing, and high-performance scale-out.
-
Azure Cosmos DB for MongoDB - Fully managed database service for apps written for MongoDB. Recommended if you have existing MongoDB workloads that you plan to migrate to Azure Cosmos DB.
-
Azure Cosmos DB for Apache Cassandra - Fully managed Cassandra database service for apps written for Apache Cassandra. Recommended if you have existing Cassandra workloads that you plan to migrate to Azure Cosmos DB.
-
Azure Cosmos DB for Table - Fully managed database service for apps written for Azure Table storage. Recommended if you have existing Azure Table storage workloads that you plan to migrate to Azure Cosmos DB.
-
Azure Cosmos DB for Apache Gremlin - Fully managed graph database service using the Gremlin query language, based on Apache TinkerPop project. Recommended for new workloads that need to store relationships between data.

-
- Click “+ Create” to create a new Cosmos DB account. In the Basics tab:
-
For Resource Group, PROTIP: Add a date to the end of the name to make it unique.
Cosmos DB Accounts
-
For Account Name (to be used as part of the DNS address for requests to the service)
PROTIP: This should be globally unique account name. The portal will check the name in real time. Account names are limited to 44 characters, and can only contain lowercase letters, numbers, and the hyphen (-) character. The account name must start with a letter and must end with a letter or number. The account name must be unique within Azure. If the name is already in use, you’ll need to try a different name.
- For Capacity mode, Learn more. Estimate costs.
- leave the default “Provisioned throughput” for workloads with sustained traffic requiring predictable performance, billed by Request Units per second (RU/s) provisioned. Unlimited storage per container.
- “Serverless” for automatic scaling for workloads with intermittent and unpredictable bursts/spikes and dips in traffic. Maximum 1 TB storage per container. Billed by RUs/second consumed.
-
Check “Apply” to Apply Free Tier Discount. With Azure Cosmos DB free tier, you will get the first 1000 RU/s and 25 GB of storage for free in an account. You can enable free tier on up to one account per subscription. Estimated $64/month discount per account.”
-
For “Limit total account throughput”, leave checked “Limit the total amount of throughput that can be provisioned on this account”
This limit will prevent unexpected charges related to provisioned throughput. You can update or remove this limit after your account is created.
- Click “Next: Global Distribution” to specify Disaster Recovery options:
- “Geo-Redundancy”
- “Multi-region writes”
- “Availability Zones” (if available for the Location/Region chosen above).
- Click “Networking” tab to specify Firewall and Virtual Network options:
- “Allow access from” - “Selected networks” (default) or “All networks”
- “Virtual networks” - “Add existing virtual network” (default) or “Create new virtual network”
- “Firewall rules” - “Add existing rule” (default) or “Create new rule”
- Click “Backup Policy” tab to specify backup options:
- “Backup policy” - “Periodic” is the default. but requires contacting Microsoft support for restore.
PROTIP: “Continuous (7 days)” and “Continuous (30 days)” is the default for Serverless. - “Backup interval (minutes)” - 240 (30-1440) is the default
- “Backup retention” - 8 Hours is the default
- “Copies of data retained” - 2
- “Backup policy” - “Periodic” is the default. but requires contacting Microsoft support for restore.
- Click “Encryption” tab to specify encryption options:
- “Server-managed key” is the default.
- “Server-managed key” is the default.
- Click “Tags” tab to specify Key “CreatedBy” tag with your email as the Value for “Azure Cosmos DB account” billing and management.
-
Click “Review + Create”. Click “Create”.
Terraform
Alternately, look at my notes about using Terraform because many companies now require that skill to ensure consistency across environments, security, etc.
Discussions:
- https://www.reddit.com/r/Terraform/comments/y7htsm/azure_cosmos_db_for_postgresql/
- https://devops.stackexchange.com/questions/16667/cosmosdb-account-virtual-network-rule-for-each
Tutorials:
- https://www.sqlservercentral.com/articles/database-deployment-with-terraform-modules
- https://digital.interhyp.de/2021/09/30/three-simple-steps-to-securely-scaffold-and-deploy-a-cosmosdb-into-azure-with-terraform/
- https://blog.entek.org.uk/notes/2021/09/23/getting-started-with-terraform.html
- https://devpress.csdn.net/mongodb/62f20efac6770329307f5e2a.html
- https://build5nines.com/terraform-create-azure-cosmos-db-database-and-container/
- https://shisho.dev/dojo/providers/azurerm/CosmosDB_DocumentDB/azurerm-cosmosdb-sql-container/
- https://docs.w3cub.com/terraform/providers/azurerm/d/cosmosdb_account
- https://sbulav.github.io/terraform/terraform-azure-cosmosdb/
- https://jamescook.dev/terraform-cosmosdb-7-day-continuous-backups
- https://faun.pub/terraform-series-scalable-webapp-using-azure-cosmosdb-fb4b56f6d2af
- https://hub.steampipe.io/mods/turbot/terraform_azure_compliance/controls/benchmark.cosmosdb
- http://man.hubwiz.com/docset/Terraform.docset/Contents/Resources/Documents/docs/providers/azurerm/r/cosmosdb_account.html
- https://www.tenable.com/policies/[type]/AC_AZURE_0227
Warnings:
- https://docs.bridgecrew.io/docs/bc_azr_storage_4
- https://gsl.dome9.com/D9.AZU.CRY.29.html
- https://ngeor.com/2018/11/04/terraform-secrets-part-2-randomize-it.html
Courses:
- https://www.pluralsight.com/resources/blog/cloud/deploy-a-simple-application-in-azure-using-terraform
Microsoft:
- https://learn.microsoft.com/en-us/azure/cosmos-db/nosql/samples-terraform
- https://www.infoq.com/news/2023/03/azure-cosmosdb-mongodb-vcore/
https://github.com/Azure/terraform-azurerm-cosmosdb
https://dev.to/krpmuruga/terraform-with-azure-cosmosdb-example-34c7
- https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/cosmosdb_account
- https://discuss.hashicorp.com/t/azure-cosmos-support-for-compulsory-role-based-authentication-as-the-only-method/29201
Cosmos DB Containers
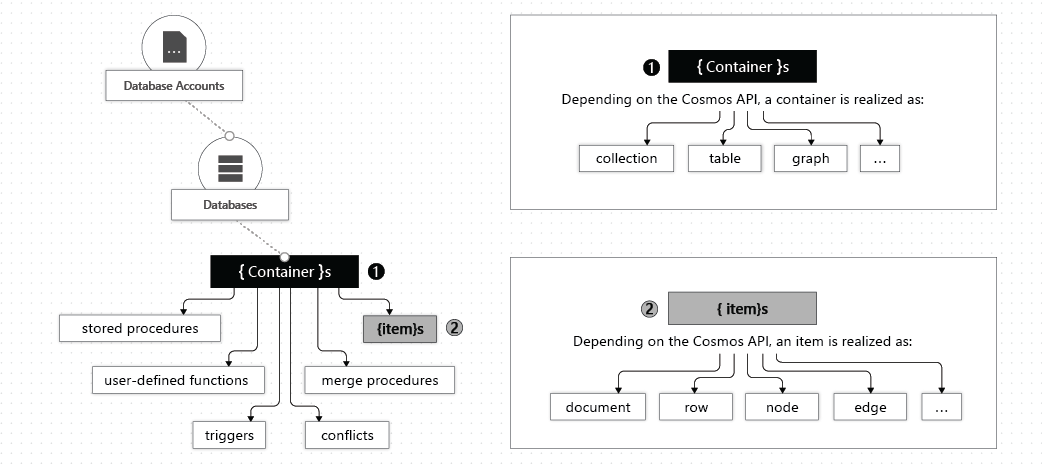
Entity model: Accout -> Database -> Container -> Item
- Click “Go to resource” to Choose a platform.
-
Click language .NET (C#), Xamarin (mobile), Java, Node.js, or Python.
Data Explorer
-
Instead of clicking “Create ‘items’ container”, click “Data Explorer” to create a new container.
REMEMBER: Data Explorer is a web-based UI for managing Azure Cosmos DB data. It provides a tree view of all the resources in your account, including databases, containers, and items. You can use Data Explorer to create, read, update, and delete (CRUD) items, stored procedures, triggers, and user-defined functions (UDFs). You can also use Data Explorer to query your data using SQL syntax.
-
REMEMBER: Click “+ New Container” to select “New database”.
Expose Connection
Cosmos DB workflow
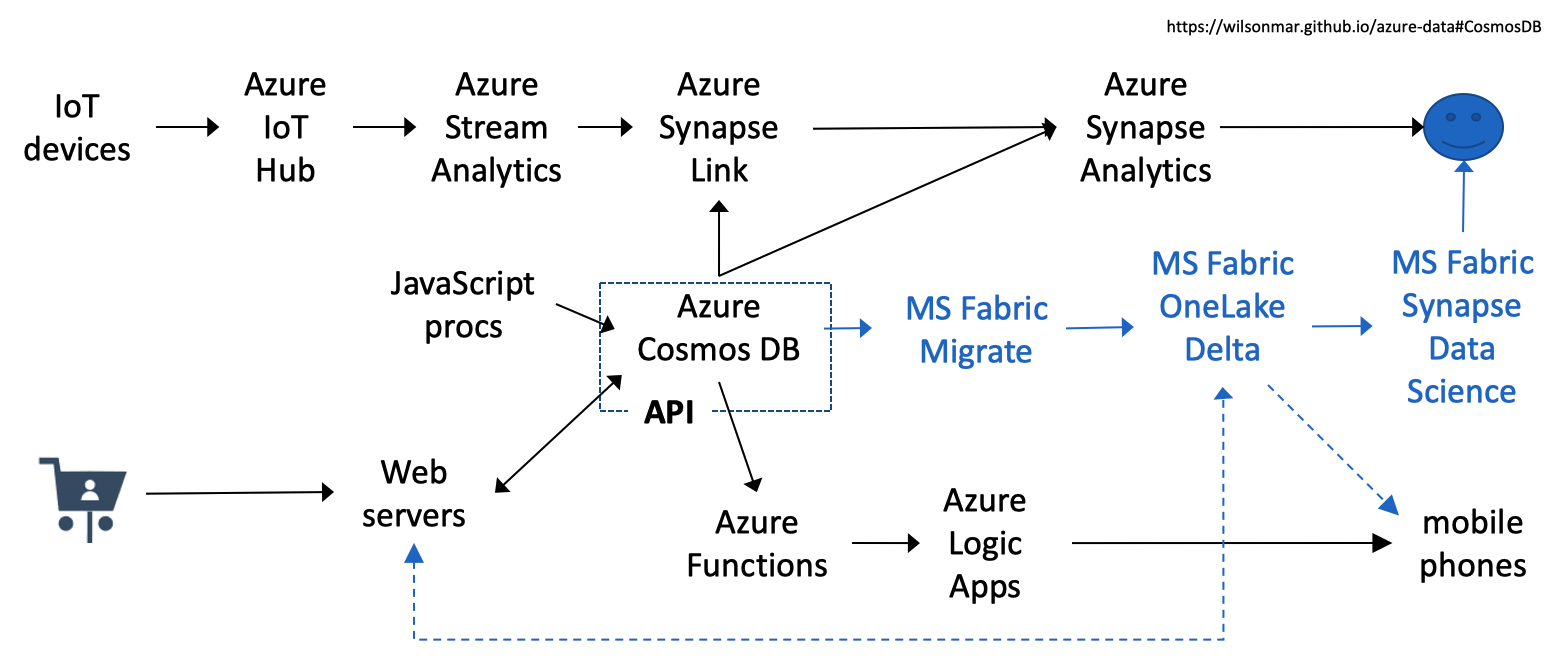
My diagram above (available on GumRoad) shows the various services accessing the API of whatever model is defined in your Cosmos DB within the Azure cloud.
Azure Synapse Link applies Transactional And Analytical Processing (HTAP) capability by enabling near real-time analytics over operational data in Azure Cosmos DB. Streaming operational data is loaded directly into rows within a Cosmos DB Analytical Store instead of ETL jobs. Operational row data is auto-synced to NoSQL, MongoDB, or Gremlin, which Azure Synapse Analytics reads for real-time insights.
Knowlege Graph
RDBMS Graph DB Table Vertex Column Property Relation Edge Mirror for Fabric
BLOG: Data within Cosmos DB instances can be accessed by Fabric apps after being mirrored (for a price).
PROTIP: Cosmos DB is really a legacy technology in regards to Microsoft Fabric.
After migration of data, existing apps (such as Azure Functions) would need to be modified to use Fabric APIs instead of the Cosmos DB API.
indexing
Cosmos DB can automatically generate a database index without the user putting together a schema upfront. However, developers still need to select the consistency model, the level of scalability, and the appropriate API for data storage. With Cosmos DB, developers can pick and choose which fields should have strong consistency.
Azure Synapase Link for Azure Cosmos DB
DP-420: Azure Cosmos DB Developer Associate
No pre-requisite exams to get the “Microsoft Certified: Azure Cosmos DB Developer Specialty” certification (Developer Associate) by passing the $165 DP-420 “Designing and Implementing Cloud-Native Applications using Microsoft Azure Cosmos DB” exam. Skills:
- Design and implement data models (35–40%)
-
Design and implement data distribution (5–10%)
- Integrate an Azure Cosmos DB solution (5–10%)
- Optimize an Azure Cosmos DB solution (15–20%)
- Maintain an Azure Cosmos DB solution (25–30%)
Microsoft’s Study Guide, as of November 2, 2023 adds details to the above, which DOES NOT MATCH the outline of what is covered live during the $1599 4-day course DP-420T00–A: Designing and Implementing Cloud-Native Applications Using Microsoft Azure Cosmos DB.
-
PROTIP: Learn concepts and terminology by going through these modules at the bottom of Microsoft’s exam page,
-
Perform the hands-on labs detailed here generated from these files and using https://github.com/microsoftlearning/dp-420-cosmos-db-dev
MODULE 1. LEARN: Get started with Azure Cosmos DB for NoSQL
- Create lab resource group
- Setup lab environment
- Enable resource providers
- HANDS-ON: Create an Azure Cosmos DB for NoSQL account. Use Data Explorer to create new items and issue basic queries.
MODULE 2. LEARN: Plan and implement Azure Cosmos DB for NoSQL
- Configure throughput for Azure Cosmos DB For NoSQL with the Azure portal
- Migrate existing data using Azure Data Factory
MODULE 3. LEARN: Connect to Azure Cosmos DB for NoSQL with the SDK
- Connect to Azure Cosmos DB for NoSQL with the .NET SDK at https://github.com/microsoftlearning/dp-420-cosmos-db-dev
- Configure the Azure Cosmos DB for NoSQL SDK for offline development (using the Windows Azure Cosmos DB Emulator)
MODULE 4. LEARN: Access and manage data with the Azure Cosmos DB for NoSQL SDKs - Create and update documents with the Azure Cosmos DB for NoSQL SDK - navigate to the Keys pane connection details and credentials necessary to connect to the account from the SDK. Specifically: URI endpoint value
- Batch multiple point operations together with the Azure Cosmos DB for NoSQL SDK
- Move multiple documents in bulk with the Azure Cosmos DB for NoSQL SDK
MODULE 5. LEARN: Execute queries in Azure Cosmos DB for NoSQL - Execute a query with the Azure Cosmos DB for NoSQL SDK
- Paginate cross-product query results with the Azure Cosmos DB for NoSQL SDK
MODULE 6. LEARN: Define and implement an indexing strategy for Azure Cosmos DB for NoSQL
- Review the default index policy for an Azure Cosmos DB for NoSQL container with the portal
- Review the default index policy for an Azure Cosmos DB for NoSQL container with the portal
MODULE 7. LEARN: Integrate Azure Cosmos DB for NoSQL with Azure services
- Process change feed events using the Azure Cosmos DB for NoSQL SDK
- Process Azure Cosmos DB for NoSQL data using Azure Functions
- Search data using Azure Cognitive Search and Azure Cosmos DB for NoSQL
MODULE 8. LEARN: Implement a data modeling and partitioning strategy for Azure Cosmos DB for NoSQL LEARN - Measure performance for customer entities
- Cost of denormalizing data and aggregates and using the change feed for referential integrity
MODULE 9. LEARN: Design and implement a replication strategy for Azure Cosmos DB for NoSQL - Connect to different regions with the Azure Cosmos DB for NoSQL SDK - using dotnet build
- Configure consistency models in the portal and the Azure Cosmos DB for NoSQL SDK
- Connect to a multi-region write account with the Azure Cosmos DB for NoSQL SDK
MODULE 10. LEARN: Optimize query and operation performance in Azure Cosmos DB for NoSQL
- Optimize an Azure Cosmos DB for NoSQL container’s indexing policy for common operations
- Optimize an Azure Cosmos DB for NoSQL container’s index policy for a specific query
MODULE 11. LEARN: Monitor and troubleshoot an Azure Cosmos DB for NoSQL solution - Use Azure Monitor to analyze an Azure Cosmos DB for NoSQL account https://devblogs.microsoft.com/cosmosdb/announcing-azure-cosmos-db-mirroring-in-microsoft-fabric-private-preview/
- Troubleshoot an application using the Azure Cosmos DB for NoSQL SDK
- Store Azure Cosmos DB for NoSQL account keys in Azure Key Vault
MODULE 12. LEARN: Manage an Azure Cosmos DB for NoSQL solution using DevOps practices
- Adjust provisioned throughput using an Azure CLI script
- Create an Azure Cosmos DB for NoSQL container using Azure Resource Manager templates
MODULE 13. LEARN: Create server-side programming constructs in Azure Cosmos DB for NoSQL - Build multi-item transactions with the Azure Cosmos DB for NoSQL 39 min EXERCISE: with the Azure portal, Author & Rollback a server-side JavaScript stored procedure scoped to a single logical partition
- Expand query and transaction functionality in Azure Cosmos DB for NoSQL
Implement and then use user-defined functions with the SDK
Databricks
VIDEO Explore Azure Databrics
Use Community Edition for free at https://community.cloud.databricks.com/login.html
https://learn.microsoft.com/en-us/azure/databricks/getting-started/free-training from the Databricks Academy at https://www.databricks.com/learn/training/home with videos at https://www.youtube.com/@Databricks
https://www.databricks.com/learn/training/lakehouse-fundamentals-accreditation#video 2-hour Delta Lakehouse Fundamentals
$200 Annual subscription for all classes at https://customer-academy.databricks.com/learn Six 2 hour “Get Started” E-learning classes
https://learning.oreilly.com/library/view/-/9781789809718/ Azure Databricks Cookbook By Phani Raj and Vinod Jaiswal Publisher:Packt Publishing September 2021 452 pages
https://learning.oreilly.com/library/view/-/9781801077347/ Data Modeling for Azure Data Services By Peter ter Braake Publisher:Packt Publishing July 2021 428 pages
https://learning.oreilly.com/library/view/-/9781837634811/ Azure Architecture Explained By David Rendón and Brett Hargreaves Publisher:Packt Publishing September 2023 446 pages
https://learning.oreilly.com/library/view/-/9781837633012/ A Developer’s Guide to .NET in Azure By Anuraj Parameswaran and Tamir Al Balkhi Publisher:Packt Publishing October 2023 504 pages
https://learning.oreilly.com/videos/-/10000MNLV202178/ Secrets Management with Terraform By Scott Winkler Publisher:Manning Publications July 2020 1h 10m
https://learning.oreilly.com/library/view/-/9780137908790/ Designing and Developing Secure Azure Solutions By Michael Howard, Simone Curzi and Heinrich Gantenbein Publisher:Microsoft Press November 2022 528 pages
https://learning.oreilly.com/library/view/-/9780137593163/ Microsoft Azure Storage: The Definitive Guide By Avinash Valiramani Publisher:Microsoft Press September 2023 304 pages
https://learning.oreilly.com/library/view/-/9781484296783/ Design and Deploy a Secure Azure Environment: Mapping the NIST Cybersecurity Framework to Azure Services By Puthiyavan Udayakumar Publisher:Apress September 2023 714 pages
HDInsight
- Data Literacy: Essentials of Azure HDInsight by Niraj Joshi Mar 22, 2021 provided this diagram:
Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs.
Like Hadoop, HDInsight is an open-source software framework for storing data and running applications on clusters of commodity “nodes” (hardware), shown at the bottom of this diagram:

The top of the diagram shows that HDInsight provides data to analytics applications in the format of Blobs, Tables, SQL Database, etc.
HDInsight provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs.
HDInsight is an Azure-managed service. As a cloud service:
- Easy-to-spin-up clusters
- Reduced costs
- Enterprise-grade scurity
- Optimized components
Benefits of Data Lakes:
- Volume
- Velocity
- Variety
- Veracity
Azure Glue is a fully managed extract, transform, and load (ETL) service to prepare and load data for analytics.
Demo HDInsight
- In the portal Home, click “+ Create a resource”.
- REMEMBER: In “Search services and Marketplace” type enough of “HDInsight” to select it from the drop-down list that appears.
-
Click “HDInsight” from Microsoft to reveal:

- Click “Create” under “Azure HDInsight” to click the “Azure HDInsight” that appears.
-
In the “Basics” screen.
For “Cluster details”:
- For “CCluster name”
-
For “Region”
HDInsight Cluster Type
-
For “Cluster Type”, click “Select cluster type”.
HDInsight processs “Big Data” Datalakes using multiple cluster types:
- Hadoop - Distributed file system for Batch Query
- Spark - data cluster computing
- Kafka - stream processing message broker
- HBase - processes schema-free data
- Apache Storm - real-time analytics Stream computation
- ML Services - predictive modeling
- Interactive query - in-memory caching
-
Select the Version, such as “Hadoop 2.7.3 (HDI 3.6)”.
Cluster credentials
Enter credentials that will be used to administer or access the cluster:
- For Cluster login username, replace “admin”
- For Cluster login password
- Repeat to Confirm cluster login password
- For Secure Shell (SSH) username, replace “sshuser”
-
Check “Use cluster login password for SSH
PROTIP: Store the username and password in a secure location. You will need them to access the cluster.
-
Click the “Storage” tab.
- Click the “Security + networking” tab.
- In prod, check the “Enable enterprise security package”, which adds cost.
- For Network settings: Resource provider connection”,
- Select “Inbound” (default) or “Outbound” (if you have a VPN).
-
Specify the “Virtual network” and “Subnet” to use if one was created.
- Click the “Configuration + pricing” tab.
-
For each Node type, select its Node size.
- Click “Tags” tab to specify a “CreatedBy” key with your email.
- Click “Review + Create”. Click “Create”.
-
Wait for “Validation successful” to click “Create”.
Connect to HDInsight
-
Make use of the cluster when “Your deployment is complete” appears.
A URL is created, such as for the dashboard:
https://name.azurehdinsight.net
HDInsight Services
Like others, HDInsight clusters come with a set of pre-installed services components to analyze batch data.
- HDFS
- YARN
- MapReduce2
- Taz
- Hive
- Pig
- Sqoop
- Oozie
- Zookeeper
- An (Apache) Ambari (unreachable S0 Headnode) VM is included on HDInsight clusters to provide a GUI to make configuration changes and display metrics. LEARN.
Additional components can be install on your cluster.
- Avro
-
Alerts
- Delete the Resources created and accessed above.
MongoDB
MongoDB can be used as a file system called GridFS. It stores files up to 16TB with load balancing and data replication over multiple machines.
SQL Server Management Studio (SSMS)
legacy on-prem. only.
SSMS is integrated to visualize and work with Azure SQL, including SQL Server in virtual machines, SQL managed instances, and SQL databases. When necessary, SSMS shows only options that work for a specific Azure service.
https://docs.azure.com/en-us/sql/ssms/download-sql-server-management-studio-ssms Installer
Microsoft SQL Server Data Tools (MDT)
ADF (Azure Data Factory)
- https://learn.microsoft.com/en-us/azure/data-factory
- ADF in one 1h 44m video
- Data Literacy: Essentials of Azure Data Factory by Emilio Melo (cloudadvantage.tech) Apr 7, 2021 provided this diagram:
- Azure Data Factory - An end to end project by MultiCloud4U by Indira Bandari
- OReilly course by Eshant Garg
ADFv1 was released 2015 without a GUI to process JSON created within Visual Studio.
ADFv2 was released September, 2017 as a cloud-based “code-free” GUI service as a replacement to run legacy SSIS (SQL Server Integration Services) packages previously on-prem. Thus, ADFv2 scales on demand.
REMEMBER: Differences in terminology between SSIS and ADFv2:
- Package -> Pipeline
- Connection Manager -> Linked Service
- Destination -> sink
- Activity -> Control flow task (such as Copy)
ADF is used to orchestrate and automate data movement and data transformation.

REMEMBER: ADF itself does not store persisted data. Pipelines are run on a Linked Service.

Use ADF to integrate “data silos” by people of various skill levels – construct ETL and ELT processes either code-free within an intuitive visual environment or write your own code
- Azure security measures to connect to on-premises, cloud-based, and software-as-a-service apps with peace of mind
Polybase Query Service for External Data is a data virtualization feature that enables query of data (using T-SQL) directly (without the need for complex ETL processes) from heterogenous (external) data:
- Apache Hadoop clusters in Hadoop Distributed File System (HDFS)
- Oracle
- Teradata
- MongoDB
- Azure Cosmos DB
- SQL Server (but not Azure SQL Database)
- Azure Synapse Analytics
- Analytics Platform System (PDW)
- Azure Blob Storage
Polybase query pushdown pushes processing tasks down to the source system rather than executing all tasks within Polybase, to reduce data movement across the network.

ADF Portal GUI
- In the portal, click “+ Create a resource”.
- REMEMBER: In “Search services and Marketplace” type enough of “Data Factory” to select it from the drop-down list that appears.
-
Click “Data Factory” Microsoft Azure Service to reveal:
https://portal.azure.com/#create/Microsoft.DataFactory
- Click its “Create” to click the “Data Factory” that appears. The Basics.
- Subscription:
- Resource group: “adf-231222-demo”
- Instance details: Name (of database) is up to 128 characters, unique on same server.
- Region: “East US” or whatever you are using for your other resources.
-
Version: “V2” is the only choice.
PROTIP: ADFv2 can work with data in other locations, including on-premises and other clouds.
- Click “Git configuration” tab to specify Git options:
-
Check “Configure Git later”.
-
Click “Networking” tab to specify Firewall and Virtual Network options:
ADF Integration Runtimes
- Check “Enable Managed Virtual Network on the default AutoResolveIntegrationRuntime”
-
Select radio button “Private endpoint”.
ADF dispatches activities and executes Data Flows, Data Movements, and SSIS packages using its Integration Runtimes compute infrastructure. Three types of Integration Runtimes are automatically created when a new ADF Resource is created:
-
An Azure AutoResolveIntegrationRuntime is created for Mapping Dataflows, the native way to transform data on ADF. It does data movement between public cloud endpoints (such as AWS, GCP, Azure, or SaaS Salesforce, SAP, etc.).
-
A Self-hosted IR is installed on resources (such as SQL Server) on a machine in self-hosted private on-premises networks.
-
A Azure-SSIS IR is installed on an Azure VM (Azure-SSIS) machine to run SS packages, such as for migration.
-
- Click “Advanced” tab.
- If in production, “Enable encryption using a Customer Managed Key”.
- Click “Tags” tab to specify a “CreatedBy” key with your email.
-
Click “Review + Create”. Click “Create”, which takes a few seconds.

-
Click on “Author and Monitor” for a separate browser tab:

- Click on the “»” at the upper-left to obtain the menu.
- Click on “Data Factory” at the upper-left.
-
Click “Author” for the main page for authoring.

Go to the “Manage” section to specify GitHub location.
Elements of ADF include: pipelines, datasets, linked services, triggers, and integration runtimes.

-
ADF enables Pipelines to be constructed to execute a logical group of activities. Each activity performs a specific task, such as copying data from a data source to a destination, executing a Hive query, or running a custom C# or Python activity.
-
Each data movement consumes or produces a dataset. The copy activity can connect (using encrypted TLS on 87 different connectors) such as ODBC and HTTPS as well as pre-defined systems (Salesforce, SAP, QuickBooks, Concur, etc.).
-
Each Dataset defines the actual representation of data (structured or unstructured), at a variety of data sources, including Azure Blob storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure SQL Database, Azure SQL Data Warehouse, Azure Cosmos DB, Azure Table storage, and Azure Database for MySQL.
-
Each Data Transformation> within a Pipeline is a mapping data flow that can be used to transform data at scale. ADF provides a visual interface to create data transformation logic without writing code.
-
To run custom code, ADF can call 13 different external services (Azure Machine Learning, Azure Functions, Azure HDInsight, Azure Databricks, Azure SQL Database, Azure SQL Data Warehouse, Azure Cosmos DB, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Blob storage, Azure Table storage, Azure Database for MySQL, and Azure Database for PostgreSQL).
-
Data Control within each Pipeline activity (such as For Each, Set, Until, Wait, or other logic) can be controlled by Triggers that are event-based, scheduled on a recurring day/time, or within a tumbling window (such as every 2 hours).
-
Linked service specifes where to find data (in Data Lake Store, Azure Databricks, etc.).
Azure Synapse Analytics
- VIDEO Explore Azure Synapse Analytics
- VIDEO: How to configure Data Factory to ingest data for Azure Synapse Analytics.
- Data Literacy: Essentials of Azure Synapse Analytics By Mohit Batra June 14, 2021 provided this diagram:
Azure Synapse Analytics was rebranded from “Azure SQL Data Warehouse”.
Azure Synapse Analytics is a “unified” cloud-based data warehousing service that combines into a single solution:
- data integration,
- enterprise data warehousing, and
- big data analytics

It integrates with Apache Spark. (Spark jobs can also be run in Azure Databricks and Azure HDInsight)
Synapse has a “Massively Parallel” engine of partitioned instances (sharding)
DEMO: Setup a workspace:
-
Create a Gen2 account.
- In the portal service search, type enough of “Azure Synapse Analytics” to select it.
- Click “+ Create” for the Basics page.
- For Subscription
- For Resource group: “synapse-231222-demo”
-
For Managed resource group: “synapse-231222-demo”
- For Workspace name: “synapse-231222-demo”
- For Region: “East US” or whatever you are using for your other resources.
- Select Data Lake Storage Gen21.
- For Account name: “synapse-231222-demo”
-
For File system name:
- Click Security tab.
- Click “Networking” tab.
- Click “Tags” tab.
- Click “Review + Create”. Click “Create”.
Data Studio is installed automtically when SQL Server Management Studio (SSMS) 18.7, Azure Data Studio is installed.
ADF
Azure Data Factory (ADF) is Heterogenous - it has connectors to various other systems.
Linked service to Data Lake Store, Azure Databricks.
Azure Data Factory on Portal GUI
-
In the portal, click “+ Create a resource”, then in “Search services and Marketplace” type enough of “Data Factory” to select it from the drop-down list.

-
Click “Create” after confirming that it’s from “Azure”.
Integrate data silos with Azure Data Factory, a service built for all data integration needs and skill levels. Easily construct ETL and ELT processes code-free within the intuitive visual environment, or write your own code. Visually integrate data sources using more than 90+ natively built and maintenance-free connectors at no added cost. Focus on your data - the serverless integration service does the rest.
- No code or maintenance required to build hybrid ETL and ELT pipelines within the Data Factory visual environment
- Cost-efficient and fully managed serverless cloud data integration tool that scales on demand
- Azure security measures to connect to on-premises, cloud-based, and software-as-a-service apps with peace of mind
- SSIS integration runtime to easily rehost on-premises SSIS packages in the cloud using familiar SSIS tools
- Resource group:
- Database name: up to 128 characters, unique on same server.
- Server:
ADF automates data movement and transformation (ETL).
ADF can spin up and down HDInsights clusters.
Process in Factory Resources:
- Pipeline
- Combine datasets (sources)
- Data flows: Select columns
- Write output to target datasets (using Power Query?)
See Pluralsight: “Building your First Data Pipeline in Azure Data Factory” by Emillio Melo
Azure Synapse Analytics
VIDEO: How to configure Data Factory to ingest data for Azure Synapse Analytics.
Azure Synapse Analytics was rebranded from “Azure SQL Data Warehouse”.
Integrates with Apache Spark. (Spark jobs can also be run in Azure Databricks and Azure HDInsight)
Synapse has a “Massively Parallel” engine of partitioned instances (sharding)
Data Studio is installed automtically when SQL Server Management Studio (SSMS) 18.7, Azure Data Studio is installed.
Connectors
Connectors are used to connect to various data systems to Ingest data into Azure, Transform data, and Load data into Azure.
About 100 connectors are listed at: https://learn.microsoft.com/en-us/azure/data-factory/connector-overview
PowerBI
See my PowerBI notes.
See Pluralsight: “Building your First Power BI Report”
Microsoft Graph
https://learn.microsoft.com/en-us/graph/use-the-api
https://www.m365princess.com/blogs/microsoft-graph-people-picker-power-apps/
https://graph.microsoft.com/v1.0/me/people
Social community
Azure Data Community lists blogs, websites, videos, podcasts, and meetups.
https://www.twitch.tv/425show
https://www.reddit.com/r/AZURE/comments/
Resources
19:48 Q&A in detail by Ravikiran Srinivasulu, Microsoft Azure Data PM
1:32:49 Q&A by Creative Solutions
John Savill’s Azure Master Class v2 - Module 9 - Database & A.I.
Graph Databases 101 with Cosmos DB by Maxime Rouiller
https://learn.microsoft.com/en-us/azure/devops/pipelines/build/variables?view=azure-devops&tabs=yaml Predefined variables
https://www.microsoft.com/en-ie/training-days#pp
https://www.youtube.com/@Microsoft365Community Microsoft 365 & Power Platform Community
https://www.youtube.com/watch?v=sK6_mHWbI78&t=245s Turn that ‘Power Apps’ app into a Mobile app!
https://powerapps.microsoft.com/en-us/blog/create-mobile-apps-with-power-apps-preview/ Create mobile apps with Power Apps (preview)
https://mindmajix.com/quiz/sql-server-quiz
https://www.youtube.com/watch?v=9OnzXWDS2OM&list=PLBfufR7vyJJ5wcKZFxY-IRgr0YwJoYCHz&index=118 VIDEO: DP 900 — Install and Use Power BI by Andrew Brown
More about Azure
This is one of a series about Azure cloud:
- Azure cloud introduction
- Azure Cloud Onramp (Subscriptions, Portal GUI, CLI)
- RDP client to access servers
- Bash Windows using Microsoft’s WSL (Windows Subsystem for Linux)
- Microsoft PowerShell ecosystem
- Azure Cloud Powershell
- PowerShell DSC (Desired State Configuration)
- PowerShell Modules
- Azure Networking
- Azure Storage
- Azure Compute
- Azure cloud DevOps
- Dockerize apps
- Kubernetes container engine
- Hashicorp Vault and Consul for keeping secrets
- Hashicorp Terraform
- Ansible
- Microsoft AI in Azure cloud
- Azure Monitoring
- Azure KSQL (Kusto Query Language) for Azure Monitor, etc.
- Dynatrace cloud monitoring
- Cloud Performance testing/engineering
- Cloud JMeter