

From Pivotal, the Java Spring Boot web services people.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
- Different builds
- Competition
- A Cloud Above Clouds
- Providers’ clouds
- Cloud Foundry API
- Cloud Foundry CLI
- GoRouter
- Service Marketplace Integration
- Elastic Runtime
- Health Monitoring and Self-Healing
- Buildpacks
- Resilience and Availability
- Orgs, Spaces, Roles, and Permissions
- Zero Downtime Deployments
- Cloud Native Design Patterns
- Diego
- Resources
- Social
- Hackathons
- More on DevOps
Here is a hands-on introduction to Cloud Foundry. Concepts are introduced after you take a small action, followed by succinct commentary, with links for more.
NOTE: Content here are my personal opinions, and not intended to represent any employer (past or present). “PROTIP:” here highlight information I haven’t seen elsewhere on the internet because it is hard-won, little-know but significant facts based on my personal research and experience.
A lot of thought has gone into the sequencing of information presented so that you learn in the least time possible.
The sequence is different that the Syllbus of the Linux Foundation’s €285 (currently USD $439) 4-hour Cloud Foundry Certified Developer (CFCD) proctored exam.
Different builds
There are several distributions of Cloud Foundry:
- Open Source CF
- PCF (Pivotal Cloud Foundry)
- IBM Bluemix
- HPE Helion Stackato
Competition
QUOTE: CF has a staging layer that takes a (12-factor) user app (e.g. jar or gem) deployed in Heroku-style buildpack (e.g. Java+Tomcat or Ruby) and produces a droplet (analogous to a Docker image).
CF doesn’t expose the containerization interface to users, but Kubernetes does.
Some expect that over time, the inflexibility of Cloud Foundry and momentum surrounding Docker will drive users to Kubernetes, Mesos, or Docker Swarm/Datacenter. This trend is accelerated by the emergence of AI features in the Google Cloud, which integrates with Kubernetes.
A Cloud Above Clouds
Cloud Foundry is labeled a PaaS (Platform as a Service) which manages many of the details of running applications in production.

But Cloud Foundry is more than this. It provides a cloud above other clouds.
Cloud Foundry provides a vendor-agnostic layer supporting many cloud providers. A single Command Line program (“cf”) provides the same interface to all cloud providers.
cloudfoundry.org is the home page of
the non-profit vendor-independent Cloud Foundry Foundation formed by 70 vendors in January of 2015 to own the
Cloud Foundry open source project at
https://github.com/cloudfoundry
- Abby Kearns is the Executive Director (@ab415)
- Chip Childers is the CTO.
For example, putting SAP’s on-premise stack on CloudFoundry adds a choice of cloud providers at the bottom:

Having hybrid computing capability enables bi-modal organizational capability: managing two separate but coherent styles of work: one focused on predictability, the other on exploration.
Although its competitors include OpenShift and Kubernetes, they integrate to form an IaaS (Infrastructure as a Service):

Providers’ clouds
Cloud Foundry enables one to switch work among clouds. This enables businesses to obtain the best price-performance and avoids vendor lock-in.
First of all, there are technical reasons to use one cloud vs. another. For example, Google Fiber provides fast connection among servers across continents. Some may prefer an Amazon AI service or Lambda features over a similar functionality in Microsoft Azure or Google Compute.
Myriad factors influence price: Size of the virtual machine, type of VM, contract length, use of SSD, to name a few.
Plus, there is a difference in the bills due to per-minute charges from Google vs. per-hour charges by Amazon.
Different techniques to calculate volume discounts make it complex to compare prices. While Microsoft and Amazon provide discounts for up-front commitments, you forfeit money if committed capacity is not actually used. For that reason, Google’s SUD (Sustained Usage Discount) and “Inferred Instance” calculations make it simple to obtain a fair price.
Rightscale’s analysis notes that Google’s SSD costs are high.
cloudspectator.com provides benchmarks comparing cloud providers. Google Compute Engine ranked #1 in (Hyperscale) price-performance [pdf]
Provider Clouds’ Endpoints
DEFINITION: A provider is a company that hosts Cloud Foundry as a service, then bills the client for the resources they use.
The API Endpoint of each Cloud Foundry certified provider:
- Pivotal Web Services at https://run.pivotal.io
uses https://api.run.pivotal.io - IBM BlueMix at ibm.com/cloud-computing/bluemix
uses https://api.ng.bluemix.net to IBM’s Watson artificial intelligence services - SoftLayer was acquired by IBM.
- Swisscom Application Cloud at https://developer.swisscom.com
uses https://api.lyra-836.appcloud.swisscom.com (https://www.swisscom.ch/en/business/enterprise/offer/cloud-data-center-services/paas/application-cloud.html”>*</a>) - SAP Cloud Platform at https://hcp.sap.com/try.html uses https://api.cf.us10.hana.ondemand.com
-
GE Predix at https://www.predix.io/registration (Industrial IoT)
- Microsoft Azure
- Google Compute Platform (GCP)
- VMware vSphere and its Photon Dashboard
- Amazon Web Services (AWS)
- Atos Cloud Foundry
- Huawei Digital Transformation FusionStage (China)
- Appfrog from CenturyLink at https://www.ctl.io/appfog
- OpenStack
Provider Account & Org for Billing
-
Sign Up for a free trial account at one or more of the above providers.
Cloud Foundry is a part of Pivotal, which also provides Spring Boot for Java. So let’s start with Pivotal Web Services at https://run.pivotal.io
Org (Organization) for Billing
-
Define an org at https://console.run.pivotal.io/organizations/new
Using different orgs is how cloud providers split the bill for you. An org encompasses the cost of computing resources, apps, and services.
PROTIP: Although an org can be used by multiple collaborators, an individual or department should be designated accountability for spending.
PROTIP: Write down the org name you created. It will be requested during login.
-
Specify billing address, credit card, etc. associated with the org.
WARNING: Wait several minutes after pressing “Send”.
-
Define the route, which can be randomly assigned by cf.
-
Define the app name such as “web-app”.
-
Define the binding ???
-
Define the space “example” as …com. ???
Cloud Foundry API
The Open Service Broker API (OSBAPI) at https://openservicebrokerapi.org with source at https://github.com/openservicebrokerapi/servicebroker/blob/v2.12/spec.md provides developers, ISVs and SaaS vendors a single, simple and elegant way to deliver services to applications running within cloud-native offerings including Cloud Foundry, OpenShift and Kubernetes.
The first release of the Open Service Broker API was announced June 2017. The focus of the release was to enable multiple platforms to leverage the API through deprecating platform specific terminology. This clears a path for more platforms integrating with the OSBAPI.
Cloud Foundry CLI
There is a CLI plug-in https://github.com/sclevine/cflocal (by Stephen Levine) enables the CLI to Stage and launch CF apps, push and pull droplets, and connect to real CF services – in Docker on a local machine (say on your fancy laptop).
Install cf CLI for your operating system.
Use package managers for easy management and upgrades.
- http://cli.cloudfoundry.org/
VIDEO in https://cloudfoundry.org/get-started by Steve Wall, Sr. Cloud Architect, who references http://docs.cloudfoundry.org/cf-cli/install-go-cli.html
On Debian/Unbuntu flavors of Linux
including Kubuntu which has the more modern lookind KDE desktop. From Canonical until 2012.
- Open a terminal window.
-
Add the Cloud Foundry Foundation public key and package repository to your system:
wget -q -O - https://packages.cloudfoundry.org/debian/cli.cloudfoundry.org.key | sudo apt-key add - echo "deb http://packages.cloudfoundry.org/debian stable main" | sudo tee /etc/apt/sources.list.d/cloudfoundry-cli.list
This sets up the repository. From this point, you just update your local package index, and then install the cf CLI:
sudo apt-get update sudo apt-get install cf-cli
- Verify below.
On RedHat Enterprise Edition and CentOS
- Open a terminal window.
-
Configure the Cloud Foundry Foundation package repository:
sudo wget -O /etc/yum.repos.d/cloudfoundry-cli.repo https://packages.cloudfoundry.org/fedora/cloudfoundry-cli.repo
-
Install the cf CLI (which will also download and add the public key to your system):
sudo yum install cf-cli
- Verify below.
On Apple Macintosh systems
- Open a Terminal window.
-
Install the packaging system Homebrew (https://brew.sh) using a Ruby instance installed by default on all Macs:
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
-
“Tap” the Cloud Foundry repository from within Cloud Foundry:
brew tap cloudfoundry/tap
-
Install the Cloud Foundry CLI:
brew install cloudfoundry/tap/cf-cli
- Verify below.
On Windows
- Open a Run command window.
-
Download and install:
https://cli.run.pivotal.io/stable?release=windows64&source=github
-
Verify below.
Verify
-
Use the
cfCLI program.cf --version
The response (on August 23, 2017):
cf version 6.29.1+d5129d651.2017-08-17
-
Get that number along with a list of commands you can do from the CLI:
cf help -a
cf version 6.29.1+d5129d651.2017-08-17, Cloud Foundry command line tool Usage: cf [global options] command [arguments...] [command options] Before getting started: config login,l target,t help,h logout,lo Application lifecycle: apps,a run-task,rt events push,p logs set-env,se start,st ssh create-app-manifest stop,sp app restart,rs env,e restage,rg scale Services integration: marketplace,m create-user-provided-service,cups services,s update-user-provided-service,uups create-service,cs create-service-key,csk update-service delete-service-key,dsk delete-service,ds service-keys,sk service service-key bind-service,bs bind-route-service,brs unbind-service,us unbind-route-service,urs Route and domain management: routes,r delete-route create-domain domains map-route create-route unmap-route Space management: spaces create-space set-space-role space-users delete-space unset-space-role Org management: orgs,o set-org-role org-users unset-org-role CLI plugin management: plugins add-plugin-repo repo-plugins install-plugin list-plugin-repos Commands offered by installed plugins: Global options: --help, -h Show help -v Print API request diagnostics to stdout These are commonly used commands. Use 'cf help -a' to see all, with descriptions. See 'cf help <command>' to read about a specific command.
PROTIP: Some commands have a single-character short name.
PROTIP: Not everyone should be able to do all these commands. Like a bouncer at an event door who checks for credentials, authentication is the process of gaining access to an application based on a list.
Once inside, like a backstage pass granting additional privileges to go backstage, administrators have additional access than the default access provided general audiences at an event. That’s authorization.
“User Account and Authentication (UAA)” is the Cloud Foundry component that provides authentication and authorization based on talks to a Cloud Controller Database (CCDB).
All settings for users are managed from the command line, either with the cf CLI tool, or with a specific UAA CLI tool called the UAA Command Line Interface (UAAC), depending on the hosting provider.
UAA uses the OAuth 2.0 (aka Open Authorization) protocol to define how users can gain access to an HTTP service. The final piece of this is a login server module that is part of the UAA server component in Cloud Foundry.
It passes tokens around – a unique identifier that provides both credentials for authentication (getting in), as well as authorization (what can be used).
Monolith app
A “monolith” is a technical term used to identify an application that has all of its components residing together as one unit. A web application is a software program running on a web server. An application consists of three main components released as a single unit:
- User interface(UI)
- Database
- Server
Internally. the codebase might be modular, but the components are all deployed together and are only designed to work within that same application.
Set Endpoint
-
To set Pivotal cloud as the endpoint to use for commands to follow:
cf api https://api.run.pivotal.io
The response:
Setting api endpoint to https://api.run.pivotal.io... OK api endpoint: https://api.run.pivotal.io api version: 2.93.0 Not logged in. Use 'cf login' to log in.
BOSH Mainfest.yml
“BOSH is designed to offer a tool chain for release engineering, deployment and lifecycle management of large scale distributed services.” In my words:
BOSH is a “lifecycle management” tool that runs Cloud Foundry itself, used “under the covers” of Pivotal CF to deploy and update infrastructure components.
https://github.com/cloudfoundry/bosh
BOSH is a self-referencing acronym where the “B” stands for BOSH itself. The “OSH” in BOSH is from “Outer Shell”.
https://github.com/cloudfoundry/docs-bosh
A BOSH operator (person) writes and manages various releases built with BOSH.
One file defines default values for the app defined within its folder – the manifest.yml file defines an App Unit of all the pieces of its system for releases. For example:
--- applications: - name: web-app memory: 32M disk_quota: 256M random-route: true buildpack: https://github.com/cloudfoundry/ruby-buildpack.gitBuildpacks are … at https://github.com/cloudfoundry
https://en.wikipedia.org/wiki/YAML
See https://bosh.io/docs/deployment-manifest.html
In practice, all instances on a Diego Cell share the available CPUs with Diego, ensuring no instance can hog the CPU.
Contents are put into a compressed folder and stored on the BOSH server.
Defaults are overrided in this:
- Command line option overrides Manifest
- Manifest.yml specification
- Currently used values
- Provider default values
- Cloud Foundry default, such as memory being one gigabyte (1GB)
Log into Cloud Foundry
-
Login using the abbreviated command name:
cf l
Instead of asking for your email and password again for every command, once logged in, Cloud Foundry generates a temporary token that the CLI stores locally (typically for 24 hours).
The API endpoint for the provider is displayed with its version in parentheses.
Alternately, specify another API during login:
cf login -a api.run.pivotal.io
- Type in the email used to register at the provider.
- Type the password associated with the email entered.
-
The targeted Org and space are displayed.
If there are several orgs, you can type in the number displayed with the org.
Push (upload) from your local machine
- Login to cf (as described above)
- Navigate to the application folder you wish to push (cd Pushing/web-app)
-
See the options associated with the cf push command:
cf help push
Alternately:
cf push -h
Here’s the response:
cf push APP_NAME [-b BUILDPACK_NAME] [-c COMMAND] [-d DOMAIN] [-f MANIFEST_PATH] [--docker-image DOCKER_IMAGE] [-i NUM_INSTANCES] [-k DISK] [-m MEMORY] [--hostname HOST] [-p PATH] [-s STACK] [-t TIMEOUT] [-u (process | port | http)] [--route-path ROUTE_PATH] [--no-hostname] [--no-manifest] [--no-route] [--no-start] [--random-route]
NOTE: You can specify how much memory to allocate.
PROTIP: An cf development environment is not needed just to push.
-
Push to CFs Cloud Controller based on what is defined in the manifest.yml file:
cf push
Alternately:
cf set-env APP-NAME web-app
cf push web-app --no-start
cf set-env APP-NAME special_token h4DKt6W7Fm4dLJxtBU37aW
cf start APP-NAMEweb-appis not needed if the name is defined in the manifest.yml file.--no-startstages apps instead of starting them immediately.cf set-env APP-NAME special_token h4DKt6W7Fm4dLJxtBU37aW
sets an envionment variable containing an access tokencf start APP-NAMEHere’s a flowchart of what should happen during a push:

Below is a description of this flowhart, of how code is transformed through its deployment process through three stages into the application.
-
Build transforms your code into an executable form.
-
The cf CLI gathers your app’s files and uploads them to Cloud Foundry Cloud Controller.
-
The Cloud Controller finds the needed Buildpack.
-
The Buildpack gather everything needed to build and run on Cloud Foundry, then builds an application image (Droplet).
-
-
Release combines the executable with available configuration.
The droplet is copied to a application container.
Within a container, the droplet is unpacked. The command to start your application is run.
If more instances of your application is created, the same droplet is used on those new application containers. The droplet is built once, when pushed, and its use ensures that all future releases are identical until the next push.
-
“Run” is when the release package gets deployed and executed.
All the pieces that combine to provide the execution environment are defined by the Diego architecture.
The “Diego” component at the heart of Cloud Foundry takes each Droplet and runs it in a Container (Diego Cell).
To run apps, the execution environment consists of virtual machines that have the necessary software to start, stop, and monitor each application. These virtual machines are called Diego Cells.
GoRouter
NOTE: Within Cloud Foundry, HTTP traffic is handled by the “GoRouter” gateway which connects two or more networks. The “Go” in the name is there because it was recently re-written (from the original Ruby) in the Go programming language to provide better performance through concurrency and a lower latency for each request.
Externally are clients from the internet, in the middle is the router, and internally are the services of Cloud Foundry.
The GoRouter maintains the association between the application and its network address path. This tuple is called a mapping. Many applications can be mapped to the same network path. This multiple mapping is what makes zero downtime deployments possible since the old and new applications can use the same network path.
The only restriction on the network address path is the path restricted to a single space. So, you cannot deploy your new application to a different space from the old application without building some additional customized routing code.
Diego auction selects Diego Cells to process (match with apps wanting execution).
-
-
Highlight the random URL CF generates (for example “flowing-packets” in “web-app-flowing-packets.cfapps.io”) to copy to your Clipboard.
-
List the apps:
cf apps
A sample response:
Getting apps in org playdate / space development as wilsonmar@gmail.com... OK name requested state instances memory disk urls web-app started 1/1 32M 256M web-app-unstridulating-bronchobuster.cfapps.io
-
List the routes:
cf routes
All Cloud Foundry routes contain a Domain and a Port Number:
Getting routes for org playdate / space development as wilsonmar@gmail.com ... space host domain port path type apps service development web-app-unstridulating-bronchobuster cfapps.io web-app
Domain
DEFINITION: A domain is used to define a router that maps your application to its location in Cloud Foundry.
It’s kinda like a Postal Service zip code designating the general vacinity.
An HTTP route is determined by the URL, while a TCP route uses the port number.
Only the TCP route (NOT HTTP) allows data to pass through without the GoRouter needing to examine it.
Through the Web App Load Balancer
-
Open to view the app runnning. First type in the Terminal:
open https://
-
Then paste the rest from your Clipboard:
open https://web-app-flowing-packets.cfapps.io
A page should open in your default internet browser.
The sample web-app from EDX simply says “Congratulations on pushing your first Cloud Foundry App”.
Many production environments have a load balancer in front of the requests coming into their network – the entry point to the Cloud Foundry network.
The job of a hardware load-balancing device :
- Minimize network downtime
- Facilitate traffic prioritization
- Provide end-to-end application monitoring
- Provide user authentication
- Protect against malicious activity
- Mitigate denial-of-service (DoS) attacks.
Staging, functional testing, and development environments typically do not use a hardware device. Instead, they will use HAProxy software to simulate the capabilities in software that the hardware device provides.
-
View responses from the app runnning. For example:
curl https://web-app-flowing-packets.cfapps.io/whoami
A sample response:
Hi! I'm the process on 10.10.148.98:61046. Nice to meet you!
Without the “whoami”, the HTML is returned.
Logging
-
View the app’s logs created recently:
cf logs web-app --recent
Cloud Foundry by default shows logs sent to channels STDOUT and STDERR by programming code such as:
- In Ruby on Rails `logger = ActiveSupport::Logger.new(STDOUT); logger.debug “Something Happened”’’
- In Go-Lang the “log” package or can write directly with
os.Stderr.WriteString("Something Happened\n") - In Java,
System.err.println("Something Happened");.
As with the logs pattern</a> in the Twelve Factor methodology, the Cloud Foundry component loggregator. streams logs out so data about the system can be gathered and analyzed away from the web server so that aggregation of logs is possible.
When the loggregator receives a message, it adds a timestamp, Channel, and a Log type (origin code of 3 letters):
- “RTR” for Router messages
- “LGR” for problems wth the logging process.
- “APP” for application
- “SSH” for reporting successful remote access, etc.
-
View the app’s SSH logs:
cf ssh web-app
The loggregator stores and forwards time-ordered logs to other analysis systems such as AppDynamics, Splunk, or in a Hadoop/Hive to:
- Finding specific events in the past
- Large-scale graphing of trends (such as requests per minute)
- Active alerting according to user-defined heuristics (such as an alert when the quantity of errors per minute exceeds a certain threshold).
The amount of data can be overwhelming, so apply a nozzle to filter logs not analyzed.
Distributed Tracing
Cloud Foundry supports the zipkin distributed tracing facility
If enabled, Cloud Foundry automatically logs messages in HTTP headers with a traceid and span ID as correlation identifiers used to correlate the different logs being collected.
Force crash
Processes can fail to start, lockup, stop listening, and crash.
-
To kill an instance purposely to see what happens, begin typing in a Terminal:
curl https://
Then paste the host name and domain:
curl https://web-app-flowing-packets.cfapps.io/crashme
Add “/crashme” to end up with something like this:
curl https://web-app-flowing-packets.cfapps.io/crashme
A sample response:
502 Bad Gateway: Registered endpoint failed to handle the request.
Restore
-
PROTIP: Create a script with the above and execute that instead of typing them again and again.
Restore vs. Restart
--no-startstages apps instead of starting them so people can view it.cf set-env APP-NAME special_token h4DKt6W7Fm4dLJxtBU37aWWhen a database is too small and you need to upgrade it, set up a larger server in preparation, import the database to it. To use the new server, change the database URL in your configuration file and restart the application.
cf restart APP-NAME
which will connect you to an instance of your application. If you have multiple instances running, you can use the -i option to choose which instance to connect to. This is a zero-based index; so the first instance is actually
cf ssh APPNAME -i 0
-
To make an external HTTP request to a specific instance of an application (the instance you are connected to via SSH), add a
X-CF-APP-INSTANCEHTTP header.That tells CF to redirect the request to a specific running instance of the app.
-
First, get the instance index (substituing “web-app” with your own app short name):
cf ssh web-app -i 0
-
Get the GUID for the application:
cf APPNAME --guid
-
Once you have both, you use them in a header for the external request.
curl app.example.com -H “X-CF-APP-INSTANCE”:”YOUR-APP-GUID:YOUR-INSTANCE-INDEX”
See the App Instance Routing section of the HTTP Routing topic for more information.
Scaling
-
To scale 2 instances of myApp :
cf scale myApp -i 2
-
Review with
cf appsagain.Delete apps
-
Stop the application, destroy the containers, and remove the applications blobs.
cf delete web-app -r -f
cf delete web-worker -r -f-ralso removes the route:cf delete example com –hostname web-app-random-name
-
PROTIP: Get the current time and save it in a text file so you can audit when you should no longer be charged by your cloud provider.
date
Service Marketplace Integration
-
Locate services and plan in the output from this command:
cf marketplace
cf marketplace -s SERVICEDrag the edge of the Terminal window to expand its width so you can see this:
NOTE: The service broker API enable developers to use existing services or create their own.
-
Create an instance of the service:
cf create-service
-
Tell Cloud Foundry which app to connect the service to:
cf bind-service
When the time comes to connect to the service, the service broker takes the request and creates a “service instance”.
When that instance comes online, it binds the service instance to the application. Binding reports the information to the GoRouter, so it knows how to send information from the application to the database.
 (Click to pop-up large image)
(Click to pop-up large image)Elastic Runtime
A “runtime” consists of a specific choice of operating system, libraries, security measures, languages, and frameworks that need to be made operational.
The runtime takes the instructions of the code and reduces them to the smallest set needed in order to operate. For Java, the runtime is called the Java Virtual Machine (JVM). The code that has been compiled is reduced into another form, called a binary. This binary can then be executed by the JVM.
“Elastic runtime” is about growing or shrinking processors, memory, disk space, etc. to meet demand from customers.
DEFINITION: Worker apps wait for requests, like a cron job (daemons) in Linux. Worker apps can start on a schedule, such as every 15 minutes.
Health Monitoring and Self-Healing
After initial deployment, the ActualLRP of how many copies the DesiredLRP (Desired Long Running Process) are currently running.
These setttings are used by monitoring components, as illustrated by this flowchart:
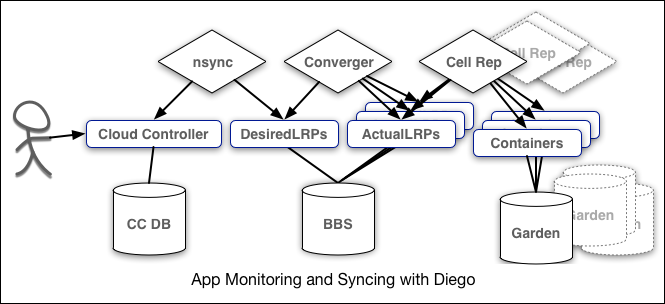
Container execution is handled by “Garden”.
The nsync, BBS, and Cell Rep components work together along a chain to keep apps running.
To set the health check when you push your app (or in your manifest):
cf push APP-NAME -u HEALTH-CHECK-TYPE -t HEALTH-CHECK-TIMEOUT
Replace HEALTH-CHECK-TYPE with one of these:
-
Port - The health monitor tries to connect to the Port it has assigned to your web application. If the Port is listening, the health monitor considers the web application healthy, and closes the connection. The Web application doesn’t have to do anything but “listen” for this to work. This is the default used.
-
Process - This is where the health check just checks with the container to see if the process is running. This works with web applications and is the normal choice for worker applications. The downside is that if an application that is locked up but still running, it is still considered healthy. Still, it’s usually the best choice for worker apps.
-
HTTP - The most advanced and complex health check has the Health Check component call the web application at a URL (endpoint), similar to a web browser. If the web application returns HTTP 200 within one second for the URL checked, the health check is considered healthy. If the request exceeds one second or returns something other than HTTP 200, the web application is considered unhealthy and the instance is replaced.
Replace HEALTH-CHECK-TIMEOUT with 60 seconds for a Java app to start or up to 180 seconds for apps with that slow of a startup.
To change health check parameters on running applications:
cf set-health-check APP-NAME (process | port | http [–endpoint PATH])
Spaces to keep different apps and services logically organized.
People do work in spaces.
Spaces are group affinities (such as “Dev”, “QA”, “Staging”, “Prod”, etc.) that contain applications and services like rooms in a house.
A user can belong to multiple spaces. In each space you see its list of user accounts. This multi-tenancy provides a level of security or separation of work, since there is control over whom is allowed to enter each space.
cf set-quota myorg service instances ???
cf set-space-quota web-app 5
This sets a limit on all future created Spaces.
Each space can have unique properties such as these quotas that define the maximum allowed:
- Total memory - The maximum amount of memory a Space can have
-
Instance memory - The maximum amount of memory an application instance can have
-
Routes - The maximum number of routes allowed in a Space
- Service instances - The maximum number of service instances that can be created
- App instances - The maximum number of application instances that can be deployed
- Paid plans - Allow or disallow paid services
- Route ports - The maximum number of routes with reserved ports
roles, permissions, and user accounts affect spaces.
An org groups spaces together. At the org level, you can list all its user accounts with all their spaces.
Roles are designed using the principle of least privilege – only the permissions necessary for the role function are assigned.
- Developer - manages the applications and services it relates to.
- Billing - is similar to the auditing role, but is more restrictive.
- Auditor - needs to review what is going on, but never modify anything.
- Manager - assigns and un-assigns user accounts from orgs and spaces, but not deploy (push) applications.
- Administrator - has all rights and privileges. So it’s is for only a few user accounts in the operations team.
NOTE: There is no “Org Developer” role or a “QA Manager” role.
BOSH Agents
BOSH is the “lifecycle manager”.
BOSH deploys agent software on each part of the system, so that if one piece fails, the agent can quickly alert operators and perhaps even automatically repair the problem.
You do not need special permissions to use them in your manifests or push command correct. You only need special permissions to add, move, or delete them.
Buildpacks
Runtimes are created by a buildpack. So each buildpack typically targets a programming language and its corresponding build tools.
-
See what buildpacks are available:
cf buildpacks
CF can detect the applications’ programming language:
- Ruby buildpacks look for Gemfiles and Gemfile.lock files and runs Bundler
- Node.js buildpacks look for packages.json and runs NPM or Yarn
- Java looks for framework features like the .groovy directory for Groovy applications. Java can run Ant, Maven, and Gradle, depending on what it detects.
- PHP may run Compose
- Go
- Python runs pip
- Static Files buildpacks look for a file named Staticfiles
- Erlang https://github.com/cloudfoundry-community/cf-docs-contrib/wiki/Buildpacks
- Swift https://github.com/cloudfoundry-community/swift-buildpack.git
- Perl runs CPAN
https://docs.cloudfoundry.org/buildpacks/#system-buildpacks
Heroku third-party buildpacks can be used on Cloud Foundry with little to no modification.
Config parameters
Buildpacks can have configuration parameters, so you can modify what features will be included with your application. For example, the PHP language buildpack allows you to choose which web server to use.
Some buildpacks even help you manage a service’s credentials when attaching and detaching a service such as a database, by managing additional application configuration parameters, such as environment variables and configuration files.
- Install dependencies your applications require
- Compile your applications, if necessary
- Provide Cloud Foundry with application configuration data.
Buildpacks standardize the process for building applications, so the various steps during building that are common can use the same commands and tools.
Resilience and Availability
https://12factor.net is a guide written by Heroku platform co-founder by Adam Wiggins (@hirodusk in Berlin, Germany; about.adamwiggins.com)
DEFINITION: A codebase is the collection of code used to build a particular application. But its “Codebase” principle is not directly supported by CF.
DEFINITION: A backing service is anything the application consumes over the network for normal operation.
A Twelve Factor app should be able to swap out local resources for remote ones with no code changes. There should be no distinction between local and remote resources.
Locally within CF:
- Datastores (e.g. MySQL, Redis, PostgreSQL)
- Caching services (e.g. Memcached)
External resources remote outside CF:
- Asset services (e.g. Amazon S3)
- Logging (e.g. Loggly, New Relic)
- Mail services (e.g. Postmark)
Application processes should not store anything that needs to persist on the filesystem of the web application.
Let’s say an app has a three-step sign up process for users visiting the site (email, confirm, provide other contact info and preferences, etc.) Each time the user hits next in that sign up process, the web server sees that as a fresh request. The state of that user’s signup should be held in a backing service with an identifier passed in each page request.
The CF Backing services hold the state of transactions in a database, a cache or some other storage. If an app uses (archaic) browser cookies, it should put them in a backing service when it receives them.
This “stateless” approach enables the app to be run on multiple servers. Every request to the web server is seen as a new request. Web server code should have no concept of a chain of events, it simply takes a request for a URL and gives a response.
Cloud Foundry provides comprehensive API endpoints that manage how applications and services connect to each other.
Storage in Diego
Buildpacks are stored in the blobstore database which stores BLOB data.
Each BLOB (Binary Large OBject) is a collection of binary data stored as a single entity in a database.
A blogstore is different than SQL databases designed to store and read rows of data.
Diego stores in each row a pointer to the BLOB on the filesystem. Read and write of BLOB data can be optimized since the large binary data is the only object it needs to worry about.
The blobstore uses the Fog Ruby gem (http://fog.io/) so it can use services Amazon S3, WebDAV, or the NFS filesystem for storage.
The Cloud Controller may be configured to use a separate blobstore for each type. But, typically, the same blobstore is used to store all five types of blobs.
The database component is called BBS (for bulletin board system) as homage to an early era before social media, or even the popularity of email and the internet, when connections were made over a dial-up connection, with a terminal program. Once connected, users would upload and download software, play games, and exchange messages. Thus, the BBS server handles messages coming from inside and outside the Diego system. This helps keep track of what work is being orchestrated across Diego at any given moment.
Orgs, Spaces, Roles, and Permissions
• Business Management Modeling
Businesses have different ways to perform their software development. Some are developer-centric, while some are application-centric, and others might be development process-centric. Cloud Foundry provides the mechanisms to achieve this modeling, control user account access, and define limits on your applications and services.
Zero Downtime Deployments
VIDEO of blue/green Zero Downtime Deployment.
A zero downtime deployment allows for the old release to finish any outstanding interactions before being shut down and for the new release to process new requests.
In zero downtime deployments, if the new release exhibits an issue, you can restore back the old release without users being aware that you are restoring back to the old release.
This is because two deployment packages run in parallel. One is the current live environment and the other is either the previous live environment, or the next deployment package ready to become live.
In front of these two environments is the load balancer or a network router determining which environment is currently live. Any existing connections are allowed to complete and any new connections go to the new environment.
When all the connections in the previous environment are closed, the previous environment can then be used to build your next deployment. It is good practice to wait before building the next deployment environment to make sure there is no reason to revert back.
Reduce risk by doing many deployments with small changes that are simpler to understand and review.
Zero downtime deployments further reduces the risk by allowing the new version some traffic for verification before you remove the older version.
When a new release is created, new routes to and from processes and background services are created. For application reliability and scalability issues, the same load balancer or network router is used for both deployments. Both versions of the code are available and connected to the backing service, so all the work is focused solely on the changes to routing.
Any changes should allow for either release to run, i.e., you must maintain forward and backward compatibility.
Let’s say you want to add a required column to the database. In order to be able to revert, we need to do a series of releases like the following:
Add the database column as an optional column and with a default value. Deploy code to use the field, without requiring it, and test the code. In the next deploy, release the code that requires the column to have the value. This release will make changes to the database column, marking it as required. Optionally, a release to remove the default value from the required column can wrap up the steps. In each of these deployments, it is safe to revert back to the previous release at any time.
Web applications use Cascading Style Sheets (CSS) to build their presentation layer. Which, from a developer’s perspective, is code they use to build different elements of the web page. For the user, the presentation layer is what they see in their browser.
In order to deploy changes to the presentation of the website, the CSS and any of the associate files need to have both the new version and the current version available. This means each CSS file has a unique identifier rather than sharing the same name. This can be accomplished with two deploys. Push the CSS first, then push any other code that uses the cssCSS in the next deploy.
When adding a required column to the database, in order to be able to revert, we need to do a series of releases like the following:
Add the database column as an optional column and with a default value. Deploy code to use the field, without requiring it, and test the code. In the next deploy, release the code that requires the column to have the value. This release will make changes to the database column, marking it as required. Optionally, a release to remove the default value from the required column can wrap up the steps. In each of these deployments, it is safe to revert back to the previous release at any time.
Web applications use Cascading Style Sheets (CSS) to build their presentation layer. Which, from a developer’s perspective, is code they use to build different elements of the web page. For the user, the presentation layer is what they see in their browser.
In order to deploy changes to the presentation of the website, the CSS and any of the associate files need to have both the new version and the current version available. This can be accomplished with two deploys. Push the CSS first, then push any other code that uses the cssCSS in the next deploy.
To add a required column to the database, enable revert by doing a series of releases:
- Add the new database column as an optional column and with a default value.
-
Deploy code to use the field, without requiring it, and test the code.
- In the next deploy, release the code that requires the column to have the default value.
-
This release will make changes to the database column, marking it as required.
-
Optionally, a release to remove the default value from the required column can wrap up the steps.
-
Remove
TODO: ??? see video
To avoid mistakes, use the cf command extension or plugin interface to automate sequences of commands. The Cloud Foundry Community has already written plugins for Zero Downtime Deployments at https://plugins.cloudfoundry.org.
bg-restage 1.0.0 Perform a zero-downtime restage of an application over the top of an old one (highly inspired by autopilot) blue-green-deploy 1.2.0 Zero downtime deploys with smoke test support autopilot 0.0.1 zero downtime deploy plugin for cf applications
An app can be restaged without redeploying the code.
Plugin blue-green-deploy performs the manual steps we did in the previous section.
The autopilot plugin does the zero downtime deployment by using the application rename technique.
We also want to mention that there are continuous integration tools such as Concourse and Jenkins that provide extensions to integrate with Cloud Foundry and can automate zero downtime deployments.
The manual commands include:
cf unmap-route blue cfapps.io --hostname blue-LFS132X-example
cf unmap-route green cfapps.io --hostname green-LFS132X-example
cf routes
Beside the deployment itself, do a few sanity or smoke tests to ensure that the application is installed properly.
Cloud Native Design Patterns
A cloud-native design pattern is a generic design template for a programming problem.
Microservice instances are dynamic. Their network route could change when Cloud Foundry starts them up. So there needs to be a way for clients to find active microservices.
The Twelve Factor “port binding” principle uses a design pattern that achieves a dynamic way for microservices to register themselves and for clients to find services.
Clients of a service can also be another microservice.
A datastore should store information about a microservice. A unique property of this datastore is it does not need to persist across reboots since each microservice needs to register itself when it starts running. This datastore will store the multiple network routes for microservice instances using a generic lookup key. Microservices and clients then share this generic key.
The Service Registry component handles both microservice registration and the microservice discovery for clients. The registry determines which clients can access which microservice through an authentication process.
Some registry services will choose a network route for the client to use. In other cases, the registry sends all the network routes back to the clients.
To find the registry service, its network route must be predetermined.
A microservice needs to register itself with the Service Registry.
Most Service Registries expect the service to refresh its registration periodically, to confirm it is still alive and up to date. A microservice might need access to other services so it can request a service just like the client. The microservice should also keep requesting its services discovery as the information will change over time. This constant registration and discovery process ensures you can distribute services and they can find each other, even as services change over time.
The client needs to authenticate with the Service Registry before getting service information back. If an error occurs, the client side needs to report it and deal with the client side interface as well.
There are various other implementations of the The GoRouter’s design pattern, such as CoreOS Etcd, HashiCorp Consul, and Puppet Zookeeper. There are also the Spring Cloud implementations of Eureka and Consul.
NOTE: A large effort to remove the Consul open source project from the Cloud Foundry platform’s internal architecture is in progress. More updates on the CF Runtime’s approach to distribute locking and service discovery can be found here.
Service Discovery Design Pattern
Service discovery makes it easy for clients to find routes to dynamic services.
Configuration Server Design Pattern
Use of a configuration server improves on Cloud Foundry’s configuration variables because:
- Configuration variables do not need to be pushed on deployment
- Configuration variables can be changed without pushing the applications
- The application can start running while waiting for the configuration variables to be defined
Circuit Breaker Design Pattern
The circuit breaker used in homes protect electrical appliances. Similarly,
The circuit breaker design pattern deals with remote communication failures to recover gracefully.
If a failure occurs, then the code path leading to it should be marked so future calls can report back a failure more quickly.
A request is received. If the request requires other services to complete, it makes those calls. Now, what if an unrecoverable error occurs? The client call needs to fail, but does not want to take a very long time. Maybe the first few failures might take a long time, but the remaining calls should complete quickly.
If the service call detects a failure, it needs to mark itself as disabled. In this way, future calls can fail right away.
It then sets up a background process to check for when the service comes back up again.
The thread gets activated when a microservice call detects an unrecoverable error, like a connection failure. In this case, the failed service is checked periodically to see if it is back up. Once the failed service recovers, the failed service call interface is marked as enabled to allow all future calls to go through.
The background task logs when it initiates a service check and when recovery occurs.
Spring uses the Hystrix library to create a dashboard user interface for showing where circuit breakers have tripped across different microservices. The dashboard provides an early detection monitor to see if problems are starting to happen with microservices.
“Release It” by Michael Nygard describes case studies of real world problems and software design patterns.
AutoSleep
Diego
Diego is written in Go to replace DEA (Droplet Execution Manager), which occured as of May 2017. The name Diego is derived from the phonetic of “DEA-Go”.
https://www.youtube.com/watch?v=gB-nrdYTTKU
Its command toolset:
cfdot
Resources
-
Video playlist from Cloud Foundry Summit Silicon Valley 2017 120+ recorded sessions and keynotes.
-
Past Summits in Frankfurt, Germany 26 Sep 2017 and 2016.
-
Free EdX class Introduction to Cloud Foundry and Cloud Native Software Architecture https://www.edx.org/course/introduction-cloud-foundry-cloud-native-linuxfoundationx-lfs132x# by Tyler Bird and Kevin Rutten
The “starkandWayne.com” emails mentioned in the example is a real cloud consultantcy company in San Francisco, where the helpful Norman Abramnovitz works.
-
Linux Foundation’s “Cloud Foundry for Developers” is normally $800.
-
Cloud Foundry developer classes offered by training partners licensed materials for in-person or eLearning include: Biarca, CapGemini, Cognizant, Dell EMC, EngineerBetter, Fast Lane, IBM, Innovivi, Pivotal, Resilient Scale, SAP, Stark & Wayne, and Swisscom.
Social
-
For an invitation to the Slack channel, give your email to:
https://slack.cloudfoundry.org -
Search for “cf” in StackOverflow at
https://stackoverflow.com/search?q=cf -
https://cloudfoundry.org/newsletter/ for invitation to events.
Hackathons
https://thenewstack.io/brainstorming-new-platform-ideas-cloud-foundry-hackathon/
More on DevOps
This is one of a series on DevOps:
- DevOps_2.0
- ci-cd (Continuous Integration and Continuous Delivery)
- User Stories for DevOps
- Git and GitHub vs File Archival
- Git Commands and Statuses
- Git Commit, Tag, Push
- Git Utilities
- Data Security GitHub
- GitHub API
- Choices for DevOps Technologies
- Pulumi Infrastructure as Code (IaC)
- Java DevOps Workflow
- AWS DevOps (CodeCommit, CodePipeline, CodeDeploy)
- AWS server deployment options
- Cloud services comparisons (across vendors)
- Cloud regions (across vendors)
- Azure Cloud Onramp (Subscriptions, Portal GUI, CLI)
- Azure Certifications
- Azure Cloud Powershell
- Bash Windows using Microsoft’s WSL (Windows Subsystem for Linux)
- Azure Networking
- Azure Storage
- Azure Compute
- Digital Ocean
- Packer automation to build Vagrant images
- Terraform multi-cloud provisioning automation
-
Hashicorp Vault and Consul to generate and hold secrets
- Powershell Ecosystem
- Powershell on MacOS
- Jenkins Server Setup
- Jenkins Plug-ins
- Jenkins Freestyle jobs
- Docker (Glossary, Ecosystem, Certification)
- Make Makefile for Docker
- Docker Setup and run Bash shell script
- Bash coding
- Docker Setup
- Dockerize apps
- Ansible
- Kubernetes Operators
- Threat Modeling
- API Management Microsoft
- Scenarios for load
- Chaos Engineering