

What is your team’s maturity at adopting best practices? Here is the comprehensive industry-standard framework from Amazon, Microsoft, and Google
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Overview
- What is it? Overview
- Why?
- WAF AWS Mind Map
- Your Radar Chart of Progress:
- Common definitions:
- WA Assessment Tools
- AWS Cloud Adoption Framework
- “Blue Car” Sample App
- Security pillar
- 1. How do you securely operate each workload?
- 2. How do you manage identities for people and machines?
- 3. How do you manage permissions for people and machines?
- 4. How do you detect and investigate security events?
- 5. How do you protect network resources?
- 6. How do you protect compute resources?
- 7. How do you classify data?
- 8. How do you protect data at rest?
- 9. How do you protect data in transit?
- 10. How do you anticipate, respond to, and recover from incidents?
- Reliability pillar
- 1. How do you manage service quotas and constraints?
- 2. How do you plan network topology?
- 3. How do you design workload service architecture?
- 4. How do you design interactions in a distributed system to prevent failures?
- 5. How do you design interactions in a distributed system to mitigate or withstand failures?
- 6. How do you monitor workload resources?
- 7. How do you design workloads to adapt to changes in demand?
- 8. How do you implement change?
- 9. How do you back up data?
- 10. How do you use fault isolation to protect workloads?
- 11. How do you design workloads to withstand component failures?
- 12. How do you test reliability?
- 13. How do you plan for disaster recovery (DR)?
- Operational Excellence pillar
- 1. How do you determine what operational priorities are?
- 2. How do you structure the organization to support business outcomes?
- 3. How does organizational culture support business outcomes?
- 4. How do you design workloads to understand its state?
- 5. How do you reduce defects, ease remediation, and improve flow into production?
- 6. How do you mitigate deployment risks?
- 7. How do you know that you are ready to support a workload?
- 8. How do you understand the health of each workload?
- 9. How do you understand the health of operations?
- 9. How do you manage workload and operations events?
- 9. How do you evolve operations?
- Performance Efficiency pillar
- Cost Optimization pillar
- AWS Cost, Usage, Billing
- Sustainability
- Well-Architected Framework Review
- References
- More on cloud
This aims to be a succinct yet deep dive about the “mind sets” needed by IT teams in the cloud.
NOTE: Content here are my personal opinions, and not intended to represent any employer (past or present). “PROTIP:” here highlight information I haven’t seen elsewhere on the internet because it is hard-won, little-know but significant facts based on my personal research and experience.
Like ITIL, PMI, SAFe, etc., the Well-Architected Framework provides “industry-standard” common terminology for concepts.
Knowledge about WA (best practices) is tested for in AWS certification exams.
AWS organized their hands-on tutorials to each of the WAF Pillars in their WellArchitectedLabs.com. Each tutorial shows only how AWS tools are used (Cloud9, CloudFormation, etc.). This is how Amazon get people to use their tooling rather than alternatives such as Terraform, Vault, etc.
Vendors offering alternative tools would need their own tutorials on their own websites.
What is it? Overview
On the surface, the “Well Architected Framework” (WAF) is a bunch of open-ended questions such as:
- How do you manage permissions for people and machines?
But each question is a rephrasing of a best practice category such as:
- Manage permissions for people and machines
For each question are considerations such as:
- Define access requirements
- Grant least privilege access
Considerations include specific recommendations such as:
- Have a clear definition of who or what should have access to each component, choose the appropriate identity type and method of authentication and authorization.
- Grant only the access that identities require by allowing access to specific actions on specific AWS resources under specific conditions.
PROTIP: To self-designate your organization and systems assets “Well Architected By Design (WABD)”, convert WAF recommendations into verifiable statements.
- Our __ document defines who or what should have access to each component, which specifies the appropriate identity type and method of authentication and authorization.
- We use Consul’s ACL features to grant only the access that identities require by allowing access to specific actions on specific resources under specific conditions.
Such statements – and evidence that prove their actual usage over time – can then be used as the basis for obtaining annual attestations from auditor based on SOC2, ISO 2700, FedRamp, etc.
WAF questions are grouped into several “pillars” which comprehensively cover all major aspects of Information Technology in the cloud, not just security. And WAF covers the entire lifecycle of apps and data.
Why?
Why? Potential benefits sound like what is claimed for every product:
- Build and deploy faster
- Lower or mitigate risks
- Make more informed decisions
- Learn best practices
- Improve the quality of workloads
https://www.effectual.com/5-reasons-your-development-team-should-be-using-the-well-architected-framework/
Pillars of the framework:
The five pillars are listed here discussed below.
Click each pillar name link to go to contents about that pillar. (Note that “you” and “your” have been removed from text by AWS):
-
OPS = Operational Excellence = The ability to run and monitor systems to deliver business value and continually improve supporting processes and procedures
-
SEC = Security = The ability to protect information, systems, and assets (applications and data) from threats. Google adds privacy, and compliance.
-
REL = Reliability = The ability to recover from failures and continue to function. Also called “High Availability” by Azure.
-
PERF = Performance Efficiency = The ability to adapt to changes in load (scale)
-
COST = Cost Optimization = The ability to achieve business outcomes at the lowest price point - Managing costs to maximize the value delivered
PROTIP: “CROPS” is a mnemonic to make the 5 easier to remember.
Those core 5 is the rare occasion when it’s what major cloud vendors all agree on.
Additional pillars added by individual vendors:
-
6. SUST = Sustainability (only by AWS) for "Minimizing the environmental impacts of running cloud workloads. It includes a shared responsibility model for sustainability, understanding impact, and maximizing utilization to minimize required resources and reduce downstream impacts". Examples are stopping over-provisioning, using more efficient Gravaton (non-x86) CPUs, etc.
6. Google adds its own "System Design" pillar.
ACTIVITY 1 - Rank the pillars
Have each member of your team do a mental exercise to prioritize the pillars as the basis for a discussion, as a team. (Why? The Dunning-Kruger effect). Example realization from this exercise:
-
PROTIP: “Operational Excellence” has to go first because that’s provides the fundamentals of getting up and running with basic services.
-
“Security” has to go first because we don’t want to have the risk of anything exposed and thus ruin our brand.
-
Let’s not slow ourselves down with Cost considerations when getting started.
-
PROTIP: It’s really not appropriate to rank these pillars. They need to be done pretty much in parallel. So we need to look in each and prioritize the impact of tasks within each pillar.
QUESTION: Is it appropriate to assign a leader/team to be responsible for each separate pillar?
WAF AWS Mind Map
Click twice on individual item for the AWS web page on it:
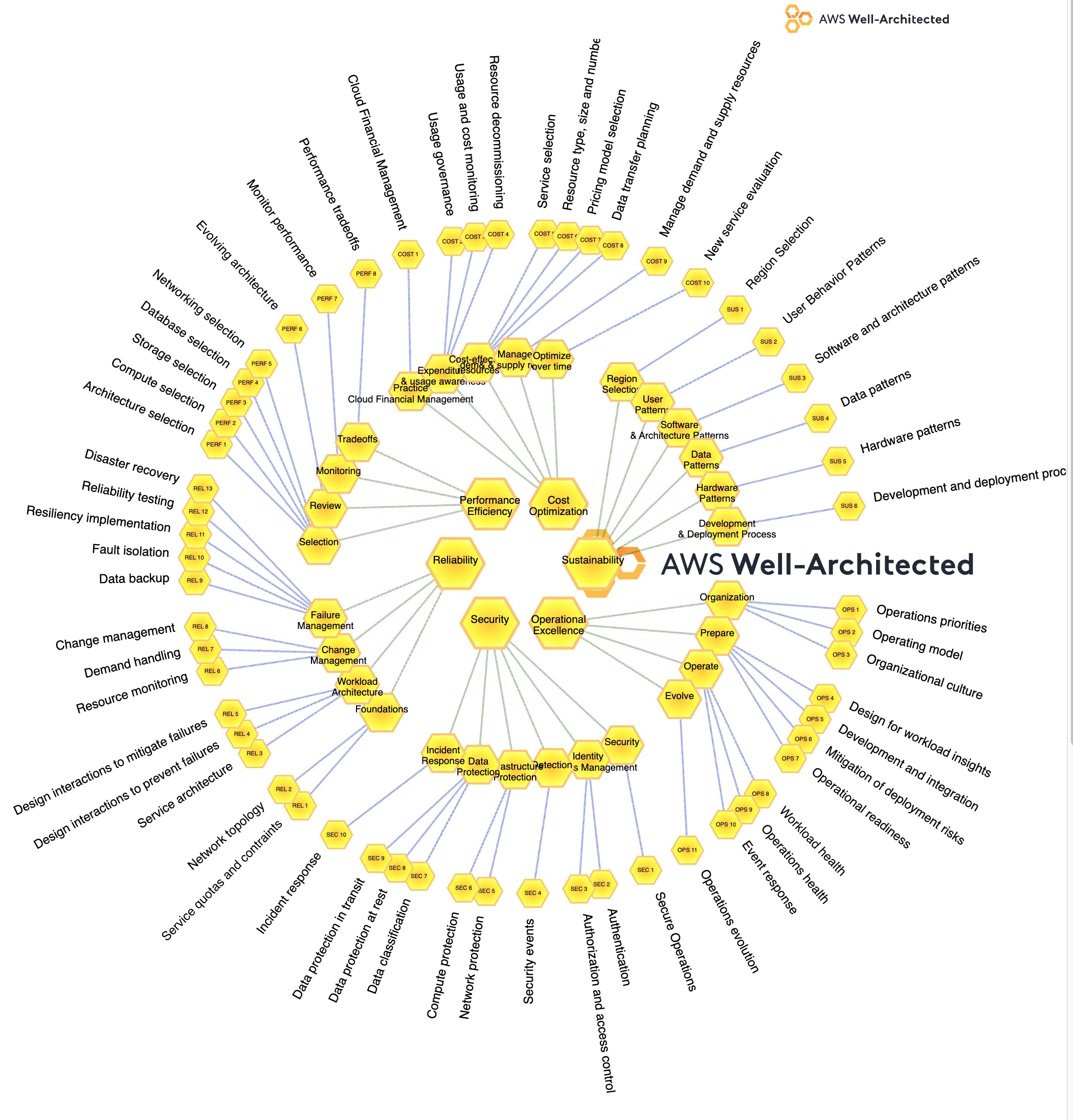
Your Radar Chart of Progress:
PROTIP: To visualize (provide a mental picture of) progress toward using public cloud effectively, I created this sample Radar Chart within an Excel file I built:

The position of each pillar can be changed.
The percentage for each “pillar” category is based on what has been achieved Now: (the inner blue line) and the Next: target (the outer red line).
The gaps (delta) between “Now” and “Next” are addressed by a backlog of activities designed to reach higher organizational and systems capability at building and operating systems using shared public clouds.
Percentages in the Radar Chart are based on a consistent and comprehensive set of design principles and best practices defined in the “Well-Architected” (WA) Framework.
The Well Architected Framework is really an industry standard because it is referenced by Amazon, Microsoft, and Google:
- https://docs.aws.amazon.com/wellarchitected/latest/framework/welcome.html
- https://docs.aws.amazon.com/index.html?ref=wellarchitected
- https://aws.amazon.com/architecture/well-architected/
- https://aws.amazon.com/blogs/apn/the-5-pillars-of-the-aws-well-architected-framework/
- https://wa.aws.amazon.com/index.en.html
- June 2020 “Well Architected Framework” summary (155 pages) in Kindle mobile app
- https://explore.skillbuilder.aws/learn/course/2045/play/6898/the-aws-well-architected-framework
- Microsoft’s WA Framework at https://docs.microsoft.com/en-us/azure/architecture/framework/ (introduced July, 2020)
- Google’s WA Framework at https://cloud.google.com/architecture/framework
https://aws.amazon.com/blogs/architecture/use-templated-answers-to-perform-well-architected-reviews-at-scale/
https://github.com/aws-samples/aws-well-architected-tool-template-automation
Common definitions:
Make sure everyone has a common understanding of each word:
Each “workload” is “a collection of interrelated applications, infrastructure, policy, governance, and operations running on AWS that provides business or operational value”. A workload can span several AWS accounts.
A “technology portfolio” is the collection of workloads that are required for the business to operate.
A “component” is the code, configuration, and resources that together deliver against a requirement. A component is often the unit of technical ownership, and is decoupled from other components.
The “architecture” is how components work together in a workload, usually illustrated by architecture diagrams that show how components communicate and interact.
The “organization” refers to the people in the hierarchy of reporting relationships. The “AWS Organization” refers to the top- Organization setting, with special permissions to an administrator of it.
Runbooks are predefined procedures containing the minimum information necessary to successfully perform the procedure.
Playbooks document the investigation process - the predefined steps to gathering applicable information, identifying potential sources of failure, isolating faults, or determining the root cause of issues.
WA Assessment Tools
Both Microsoft Azure and Amazon AWS have an assessment tool based on WAF.
Amazon’s Tool is operated by specialists who run an analysis of resources defined for each account.
Microsoft’s tool is also based on what has been configured in its Azure cloud. But its results are displayed automatically on every login unless it’s turned off.
https://www.sogosurvey.com/
Microsoft Azure Advisor
Microsoft’s Advisor tool under its “Azure Monitoring and Management” menu pane presents a dashboard to display scores calculated daily:

-
Cost Optimization recommendations includes “Potential yearly savings” specific to each impacted resource:


Azure Advisor automatically identifies low-utilization virtual machines when:
- Average CPU utilization is 5% or less (custom configurable to 5%, 10%, 15%, or 20%)
- network utilization is less than 2%
- current workload can be accommodated by a smaller virtual machine size.
AWS partner dashbird.io
Amazon partner dashbird.io/ (for $79/mo. after 14 day trial) continuously runs multiple best practice checks against serverless workloads, to provide actionable advice on how to improve the applications in alignment with Well-Architected best practices.
AWS WA Assessment Tool

-
Get credentials to sign into AWS GUI console and AWS CLI.
-
In a browser, go to the (free) AWS WA Tool (introduced 2018) provides a set of questions (context) and best practices:
-
Click orange “Define workload”.
-
Specify a name for the workload under assessment. If you’re using a shared account, enter your name such as:
wilson’s all xxx workload
The “xxx” stands for the list of AWS account numbers specified for this assessment.
-
Click “Well-Architected Framework” to get to the content of questions and answers.
-
One pillar at a time, in the priority identified, select each question, then select applicable items.
BLOG: APIs now available for the AWS Well-Architected Tool
https://aws.amazon.com/blogs/architecture/use-templated-answers-to-perform-well-architected-reviews-at-scale/
https://github.com/aws-samples/aws-well-architected-tool-template-automation
### AWS Lenses
-
If applicable, select a lens (listed alphabetically here) to reveal additional terms, processes, etc.:
-
Analytics: HTML | 95 pages on Kindle (mobile) app. The AWS Analytics Lens consists of these layers:
- Data Ingestion Layer
- Data Access and Security Layer
- Catalog and Search Layer
- Central Storage Layer
- Processing and Analytics Layer
- User Access and Interface Layer
Analytics Scenarios:
- Data Lake
- Batch Data Processing
- Streaming Ingest and Stream Processing
- Lambda Architecture
- Data Science
- Multi-tenant Analytics
-
Financial Services Industry: HTML | 71 pages on Kindle (mobile) app
- High-Performance Computing (HPC): HTML | 55 pages on Kindle (mobile) app.
- Loosely Coupled Scenarios
- Tightly Coupled Scenarios
-
IoT: HTML | 77 pages on Kindle (mobile) app. The AWS IoT Lens consists of these layers:
- Design and Manufacturing Layer
- Edge Layer
- Provisioning Layer
- Communication Layer
- Ingestion Layer
- Analytics Layer
- Application Layer
-
SaaS: HTML | 87 pages on Kindle (mobile) app
-
Serverless Applications: HTML | 91 pages on Kindle (mobile) app
- Machine Learning: HTML | PDF | 265 pages on Kindle (mobile) app
The Machine Learning Lens breaks down process lifecycle phases in this Lifecycle architecture diagram:

- Business goal identification
- ML problem framing
- Data processing (Prepare and Process Data Features)
- Model development (Train, Tune, Evaluate)
- Deployment
- Monitoring
-
Microsoft Training on WA
Microsoft Azure Well-Architected Review provides guidance by pillar.
AWS Milestones
The AWS WA Tool has a way to save several milestones to show an annotated line chart about progress over time.
But note that it’s for work across all pillars together, not for individual pillars.
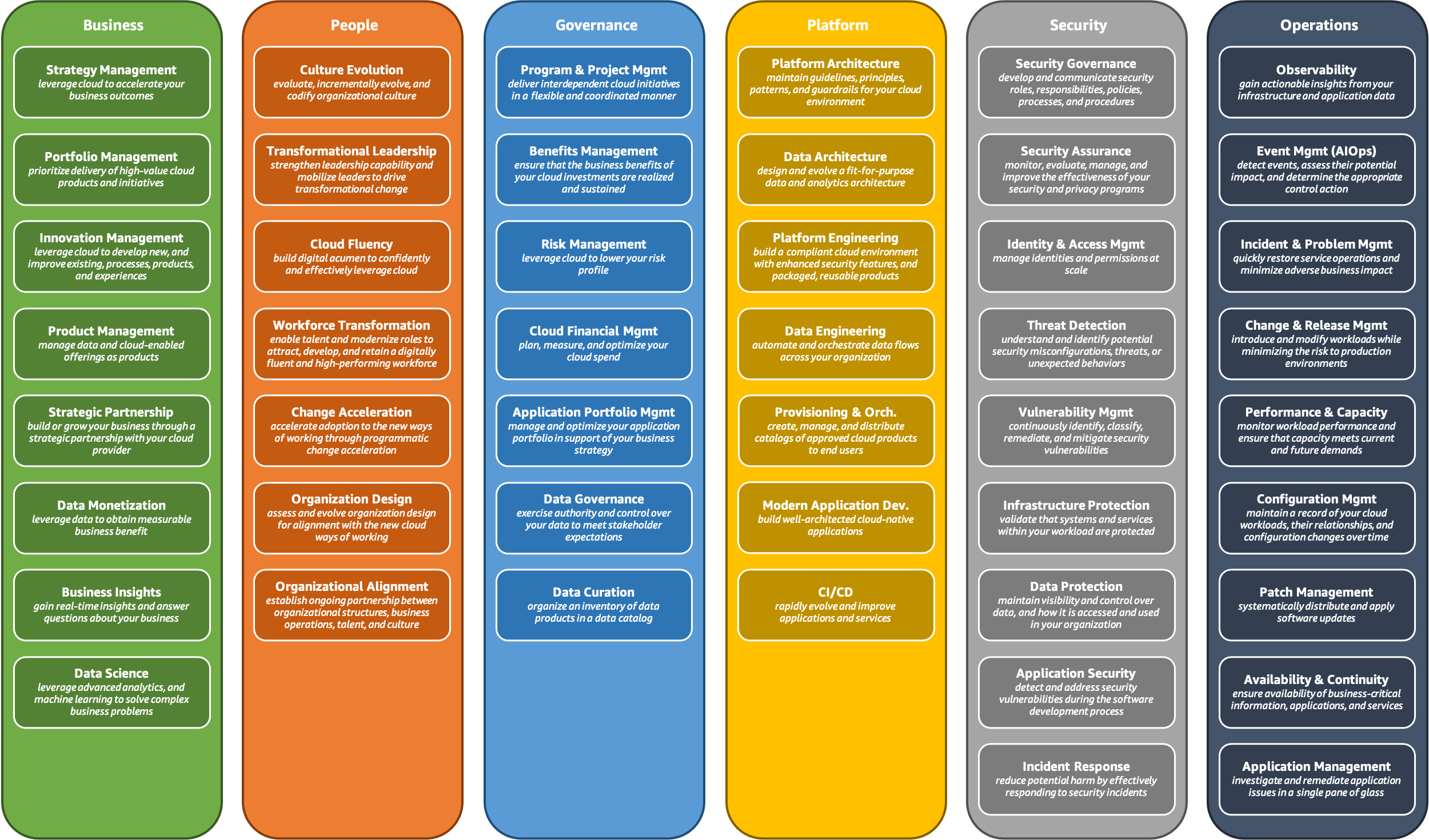
AWS Cloud Adoption Framework
AWS Cloud Adoption Framework (AWS CAF) discusses these (yet another set of) perspectives:
- Business
- People
- Governance
- Platform
- Security
- Operations
General Design Principles
AWS published these General Design Principles:
-
Stop guessing capacity needs - if you make a poor capacity decision when deploying a workload, the team might end up sitting on expensive idle resources or dealing with the performance implications of limited capacity. With cloud computing, these problems can go away. Use as much or as little capacity as needed, and scale up and down automatically.
-
Test systems at production scale - In the cloud, a production-scale test environment can be created on demand, complete testing, and then decommission the resources. Because payment is only for the test environment when it’s running, you can simulate live environments for a fraction of the cost of testing on premises.
-
Automate to make architectural experimentation easier (everything in AWS is an API) - Automation allows you to create and replicate workloads at low cost and avoid the expense of manual effort. You can track changes to the automation, audit the impact, and revert to previous parameters when necessary.
-
Allow for evolutionary architectures - In a traditional environment, architectural decisions are often implemented as static, onetime events, with a few major versions of a system during its lifetime. As a business and its context continue to evolve, these initial decisions might hinder the system’s ability to deliver changing business requirements. In the cloud, the capability to automate and test on demand lowers the risk of impact from design changes. This allows systems to evolve over time so that businesses can take advantage of innovations as a standard practice.
-
Drive architectures using data - In the cloud, you can collect data on how architectural choices affect the behavior of workloads. This enable fact-based decisions on how to improve workloads. Cloud infrastructure is code, so that data can be used to inform architecture choices and improvements over time.
-
Improve through “game days” (dry-run simulation, chaos engineering, etc.) - Test how architecture and processes perform by regularly scheduling game days to simulate events in production. This will help you understand where improvements can be made and can help develop organizational experience in dealing with events.
But what are specific actions?
AWS Skillbuilder video courses are rather verbose and high-level, but provides knowledge checks (quizzes).
AWS Well-Architected Labs
Specific hands-on labs from https://wellarchitectedlabs.com built (using Hugo) from https://github.com/awslabs/aws-well-architected-labs for each pillar (links to details in each section):
-
OPS = Operational Excellence = The ability to run and monitor systems to deliver business value and continually improve supporting processes and procedures
-
SEC = Security = The ability to protect information, systems, and assets (applications and data) from threats. Google calls this “Security, privacy, and compliance”.
-
REL = Reliability = The ability to recover from failures and continue to function
-
PERF = Performance Efficiency = The ability to adapt to changes in load (scale)
-
COST = Cost Optimization = The ability to achieve business outcomes at the lowest price point - Managing costs to maximize the value delivered
-
SUST = Sustainability (AWS only)
AWS provides its partners in-depth training on the Well-Architected Framework so they help companies implement best practices, measure the state of workloads, and make improvements where assistance is required.
AWS’ WellArchitectedLabs.com provides dozens of labs refered in AWS Certification Exam prep and in security quests referenced during free Loft live sessions AWS runs for Startups
Video tutorials on third-party subscription sites:
- https://www.xtremelabs.io/xtremelabs-now-offers-aws-well-architected-labs/ provides AWS user credentials that are managed and maintained by XtremeLabs.
- On LinkedIn Learning: “Master the AWS Well-Architected Framework” series by Mark Wilkins (in 2020)
- On ACloudGuru: “Mastering the AWS Well-Architected Framework” by Mark Nunnikhoven
PROTIP: Complaints about AWS’ Well Archtected Labs are that they:
- have instructions which require Admin permissions not available to some enterprise users
- have too many instructions for clicking and typing in GUI forms instead of automated actions performed by scripts (such as these steps to create VPCs in 3 AZs) instead of shell scripts
- reference AWS’ CloudFormation templates (such as this 2138-line vpc-alb-app-db.yaml file) as Infrastructure-as-Code (for better repeatability, collaboration versioning, security, etc.) instead of HashiCorp Terraform files
Thus, items below have [Terraform] links to Terraform HCL (plus Bash shell scripts and Ansible, where applicable).
Each link will go to a web page containing a Twitch-type Zoom recording walking through the steps, then showing the equivalent Terraform.
PROTIP: We analyze utilities Google’s terraformer and cloud diagram creator Cycloid’s terracognita which create Terraform files based on what has been created in AWS (“reverse Terraform”). Wisdom Hambolu analyzes use of a utility that attempts to convert Cloud Formation to Terraform, with mixed results.
href=”https://spacelift.io/blog/importing-exisiting-infrastructure-into-terraform”>
https://github.com/aws-samples/aws-well-architected-tool-template-automation
Operational Excellence Labs
- [Terraform] 100 - Inventory and Patch Management
- [Terraform] 100 - Dependency Monitoring
-
[Terraform] 200 - Automating operations with Playbooks and Runbooks
Security Labs
- [Terraform] 100: Foundational Labs
- [Terraform] 200: Automated Deployment of VPC
- [Terraform] 200: Automated Deployment of Web Application Firewall
- [Terraform] 200: Automated IAM User Cleanup
- [Terraform] 200: Basic EC2 Web Application Firewall Protection
- [Terraform] 200: AWS Certificate Manager Request Public Certificate
- [Terraform] 200: CloudFront for Web Application
- [Terraform] 200: CloudFront with WAF Protection
- [Terraform] 200: Remote Configuration, Installation, and Viewing of CloudWatch logs
- [Terraform] 300: Multilayered API Security with Cognito and WAF
- [Terraform] 300: Autonomous Monitoring Of Cryptographic Activity With KMS
- [Terraform] 300: Autonomous Patching With EC2 Image Builder And Systems Manager
- [Terraform] 300: IAM Permission Boundaries Delegating Role Creation
- [Terraform] 300: IAM Tag Based Access Control for EC2
- [Terraform] 300: Incident Response Playbook with Jupyter - AWS IAM
- [Terraform] 300: Incident Response with AWS Console and CLI
- [Terraform] 300: Lambda Cross Account Using Bucket Policy
- [Terraform] 300: Lambda Cross Account IAM Role Assumption
-
[Terraform] 300: VPC Flow Logs Analysis Dashboard
Reliability Labs
- [Terraform] 100: Deploy a Reliable Multi-tier Infrastructure using CloudFormation
- [Terraform] 200: Implementing Bi-Directional Cross-Region Replication (CRR) for Amazon Simple Storage Service (Amazon S3)
- [Terraform] 200: Deploy and Update CloudFormation
- [Terraform] 200: Testing Backup and Restore of Data
- [Terraform] 200: Testing for Resiliency of EC2 instances
-
[Terraform] 200: Backup and Restore with Failback for Analytics Workload
- [Terraform] 300: Implementing Health Checks and Managing Dependencies to improve Reliability
- [Terraform] 300: Testing for Resiliency of EC2, RDS, and AZ
- [Terraform] 300: Fault Isolation with Shuffle Sharding
-
Performance Efficiency Labs
- [Terraform] 100: Monitoring with CloudWatch Dashboards
- [Terraform] 100: Calculating differences in clock source
- [Terraform] 100: Monitoring Windows EC2 instance with CloudWatch Dashboards
-
[Terraform] 100: Monitoring an Amazon Linux EC2 instance with CloudWatch Dashboards
Cost Optimization Labs
- [Terraform] 100: AWS Account Setup: Lab Guide
- [Terraform] 100: Cost and Usage Governance
- [Terraform] 100: Pricing Models
- [Terraform] 100: Cost and Usage Analysis
- [Terraform] 100: Cost Visualization
- [Terraform] 100: Rightsizing Recommendations
- [Terraform] 100: Cost Estimation
- [Terraform] 100: Goals and Targets
- [Terraform] 200: Cost and Usage Governance
- [Terraform] 200: Pricing Models
- [Terraform] 200: Cost and Usage Analysis
- [Terraform] 200: Cost Visualization
- [Terraform] 200: Rightsizing with Compute Optimizer
- [Terraform] 200: Pricing Model Analysis
- [Terraform] 200: Cloud Intelligence Dashboards
- [Terraform] 200: Workload Efficiency
- [Terraform] 200: Licensing
- [Terraform] 300: Automated Athena CUR Query and E-mail Delivery
- [Terraform] 300: Automated CUR Updates and Ingestion
- [Terraform] 300: AWS CUR Query Library
- [Terraform] 300: Splitting the CUR and Sharing Access
- [Terraform] 300: Optimization Data Collection
-
[Terraform] 300: Organization Data CUR Connection
Sustainability Labs
- [Terraform] 300: Optimize Data Pattern using Amazon Redshift Data Sharing
- [Terraform] 300: Turning Cost & Usage Reports into Efficiency Reports
“Blue Car” Sample App
STAR: Follow these instructions to deploy Amazon’s “Blue Car” sample app from an Amazon Cloud Formation template. It is a “JAM” stack app where JavaScript in each user’s browser interacts with a public API Gateway to a backend API built using Lambda:
-
Amazon Cloud9 IDE in the cloud
- Amazon Cognito provides user management and authentication functions to secure the backend API
- AWS Amplify hosts the static website with CI/CD build-in
- Amazon API Gateway provides a persistence layer where data can be stored by the API’s Lambda function
- AWS Lambda to process requests
- Amazon DynamoDB provides a persistence layer where data can be stored by the API’s Lambda function.
STATUS: I’ve been getting an error. Maintainer Stephen Salim contacted for below: Use this stack.
Security pillar
 References:
References:
- VIDEO: AWS Well Architected Cloud Framework, a Deep-Dive into IT Security Pillar”
- https://wa.aws.amazon.com/wat.pillar.security.en.html
- VIDEO: Well-Architected for Security: Advanced Session by Amazon Web Services
- 56 pages on Kindle (mobile) app
- AWS Well-Architected Labs for Security
- VIDEO: AWS Tech talk
-
AWS Security Reference Architecture (AWS SRA) is a holistic set of guidelines for deploying the full complement of AWS security services in a multi-account environment, with examples in GitHub for Customizations for AWS Control Tower (CFCT).
- Google: Security, privacy, and compliance
The broad security areas:
- Identity and access management
- Infrastructure protection
- Data protection: sovereignty and encryption
- Incidence response
- Application security
- Security resources
Key Design principles for security in the cloud:
- Implement a strong identity foundation
- Enable traceability
-
Apply security at all layers (levels)
- Automate security best practices
- Protect data in transit and at rest
- Keep people away from data
-
Prepare for security events (incident response)
- Identify and validate control objectives
- Automate testing and validation of security controls in pipelines
Best practice categories for Security:
- Securely operate each workload
- Manage identities for people and machines
- Manage permissions for people and machines
- Detect and investigate security events
- Protect network resources
- Protect compute resources
- Classify data
- Protect data at rest
- Protect data in transit
- Anticipate, respond to, and recover from incidents
Questions and Considerations for Security:
1. How do you securely operate each workload?
-
SEC-01-01-GrowSepAccts
Separate workloads using accounts - Organize workloads in separate accounts and group accounts based on function or a common set of controls rather than mirroring the company’s reporting structure. Start with security and infrastructure in mind to enable the organization to set common guardrails as workloads grow. -
SEC-01-02-SecAccts
Secure AWS account Secure access to accounts - for example by enabling MFA and restrict use of the root user, and configure account contacts. -
SEC-01-03-ControlObjs
Identify and validate control objectives - Based on compliance requirements and risks identified from the threat model, derive and validate the control objectives and controls that you need to apply to workloads. Ongoing validation of control objectives and controls help you measure the effectiveness of risk mitigation. -
SEC-01-04-NoticeThreats
Keep up to date with security threats - Recognize attack vectors by staying up to date with the latest security threats to help you define and implement appropriate controls. -
SEC-01-05-NoticeRecommendations
Keep up to date with security recommendations - Stay up to date with both AWS and industry security recommendations to evolve the security posture of workloads. -
SEC-01-06-AutoTesting
Automate testing and validation of security controls in pipelines - Establish secure baselines and templates for security mechanisms that are tested and validated as part of builds, pipelines, and processes. Use tools and automation to test and validate all security controls continuously. For example, scan items such as machine images and infrastructure as code templates for security vulnerabilities, irregularities, and drift from an established baseline at each stage. -
SEC-01-07-ThreatModel
Identify and prioritize risks using a threat model - Use a threat model to identify and maintain an up-to-date register of potential threats. Prioritize threats and adapt security controls to prevent, detect, and respond. Revisit and maintain this in the context of the evolving security landscape. -
SEC-01-08-EvalNewSvcs
Evaluate and implement new security services and features regularly - AWS and APN Partners constantly release new features and services that allow you to evolve the security posture of workloads.
2. How do you manage identities for people and machines?
-
SEC-02-01-SignInMFA
Use strong sign-in mechanisms - Enforce minimum password length, and educate users to avoid common or re-used passwords. Enforce multi-factor authentication (MFA) with software or hardware mechanisms to provide an additional layer. Use temporary credentials -
SEC-02-02-SSO-IAM
Require identities to dynamically acquire temporary credentials. - For workforce identities, use AWS Single Sign-On, or federation with IAM roles to access AWS accounts. For machine identities, require the use of IAM roles instead of long term access keys. -
SEC-02-03-AutoRotationSvc
Store and use secrets securely - For workforce and machine identities that require secrets such as passwords to third party applications, store them with automatic rotation using the latest industry standards in a specialized service. -
SEC-02-04-CentralIdP
Rely on a centralized identity provider - For workforce identities, rely on an identity provider that enables you to manage identities in a centralized place. This enables you to create, manage, and revoke access from a single location – making it easier to manage access. This reduces the requirement for multiple credentials and provides an opportunity to integrate with HR processes. -
SEC-02-05-LongCredRotation
Audit and rotate credentials periodically - When you cannot rely on temporary credentials and require long term credentials, audit credentials to ensure that the defined controls (for example, MFA) are enforced, rotated regularly, and have appropriate access level. -
SEC-02-06-UserAttributes
Leverage user groups and attributes - Place users with common security requirements in groups defined by identity providers, and put mechanisms in place to ensure that user attributes that may be used for access control (e.g., department or location) are correct and updated. Use these groups and attributes, rather than individual users, to control access. This manages access centrally by changing a user’s group membership or attributes once, rather than updating many individual policies when a user’s access needs change.
3. How do you manage permissions for people and machines?
-
SEC-03-01-DefAccess
Define access requirements - Each component or resource of a workload needs to be accessed by administrators, end users, or other components. Have a clear definition of who or what should have access to each component, choose the appropriate identity type and method of authentication and authorization. -
SEC-03-02-LeastPrivilege
Grant least privilege access - Grant only the access that identities require by allowing access to specific actions on specific AWS resources under specific conditions. Rely on groups and identity attributes to dynamically set permissions at scale, rather than defining permissions for individual users. For example, you can allow a group of developers access to manage only resources for their project. This way, when a developer is removed from the group, access for the developer is revoked everywhere that group was used for access control, without requiring any changes to the access policies. -
SEC-03-03-EmergAccess
Establish emergency access process - A process that allows emergency access to workloads in the unlikely event of an automated process or pipeline issue. This will help you rely on least privilege access, but ensure users can obtain the right of access when they require it. For example, establish a process for administrators to verify and approve their request. -
SEC-03-04-ReducePerms
Reduce permissions continuously - As teams and workloads determine what access they need, remove permissions they no longer use and establish review processes to achieve least privilege permissions. Continuously monitor and reduce unused identities and permissions. -
SEC-03-05-PermisGuards
Define permission guardrails for the organization - Establish common controls that restrict access to all identities in the organization. For example, you can restrict access to specific AWS Regions, or prevent operators from deleting common resources, such as an IAM role used for the central security team. -
SEC-03-06-FederatedLifecycle
Manage access based on life cycle - Integrate access controls with operator and application life cycle and centralized federation providers. For example, remove a user’s access when they leave the organization or change roles. -
SEC-03-07-CrossAcctAccess
Analyze public and cross-account access - Continuously monitor findings that highlight public and cross account access. Reduce public access and cross account access to only resources that require this type of access. -
SEC-03-08-SharedAccess
Share resources securely - Govern the consumption of shared resources across accounts or within the AWS Organization. Monitor shared resources and review shared resource access.
4. How do you detect and investigate security events?
-
SEC-04-01-
Configure service and application logging - Configure logging throughout the workload, including application logs, resource logs, and AWS service logs. For example, ensure that AWS CloudTrail, Amazon CloudWatch Logs, Amazon GuardDuty and AWS Security Hub are enabled for all accounts within the organization. -
SEC-04-02-
Analyze logs, findings, and metrics centrally - All logs, metrics, and telemetry should be collected centrally, and automatically analyzed to detect anomalies and indicators of unauthorized activity. A dashboard can provide you easy to access insight into real-time health. For example, ensure that Amazon GuardDuty and Security Hub logs are sent to a central location for alerting and analysis. -
SEC-04-03-
Automate response to events - Using automation to investigate and remediate events reduces human effort and error, and enables you to scale investigation capabilities. Regular reviews will help you tune automation tools, and continuously iterate. For example, automate responses to Amazon GuardDuty events by automating the first investigation step, then iterate to gradually remove human effort. -
SEC-04-04-
Implement actionable security events - Create alerts that are sent to and can be actioned by the team. Ensure that alerts include relevant information for the team to take action. For example, ensure that Amazon GuardDuty and AWS Security Hub alerts are sent to the team to action, or sent to response automation tooling with the team remaining informed by messaging from the automation framework.
5. How do you protect network resources?
-
SEC-05-08-NetLayers
Create network layers - Group (separate) components that share reachability requirements into layers. For example, a database cluster in a VPC with no need for internet access should be placed in subnets with no route to or from the internet. In a serverless workload operating without a VPC, similar layering and segmentation with microservices can achieve the same goal. -
SEC-05-08-ControlTraffic
Control traffic at all layers - Apply controls with a defense in depth approach for both inbound and outbound traffic. For example, for Amazon Virtual Private Cloud (VPC) this includes security groups, Network ACLs, and subnets. For AWS Lambda, consider running in private VPC with VPC-based controls. -
SEC-05-08-ProtectNetwork
Automate network protection - Automate protection mechanisms to provide a self-defending network based on threat intelligence and anomaly detection. For example, intrusion detection and prevention tools that can pro-actively adapt to current threats and reduce their impact. -
SEC-05-08-InspectNet
Implement inspection and protection - Inspect and filter traffic at each layer. For example, use a web application firewall to help protect against inadvertent access at the application network layer. For Lambda functions, third-party tools can add application-layer firewalling to the runtime environment.
6. How do you protect compute resources?
-
SEC-06-01-
Perform vulnerability management - Frequently scan and patch for vulnerabilities in code, dependencies, and infrastructure to help protect against new threats. -
SEC-06-02-
Reduce attack surface - Reduce attack surfaces by hardening operating systems, minimizing components, libraries, and externally consumable services in use. -
SEC-06-03-
Implement managed services - Implement services that manage resources, such as Amazon RDS, AWS Lambda, and Amazon ECS, to reduce security maintenance tasks as part of the shared responsibility model. -
SEC-06-04-
Automate compute protection - Automate protective compute mechanisms, including vulnerability management, for reduction in attack surface, and management of resources. -
SEC-06-05-
Enable people to perform actions at a distance - Removing the ability for interactive access reduces the risk of human error, and the potential for manual configuration or management. For example, use a change management workflow to deploy EC2 instances using infrastructure as code, then manage EC2 instances using tools instead of allowing direct access or a bastion host. -
SEC-06-06-
Validate software integrity - Implement mechanisms (for example, code signing) to validate that the software, code, and libraries used in the workload are from trusted sources and have not been tampered with.
7. How do you classify data?
-
SEC-07-01-
Identify the data within workloads - This includes the type and classification of data, the associated business processes. data owner, applicable legal and compliance requirements, where it’s stored, and the resulting controls that are needed to be enforced. This may include classifications to indicate if the data is intended to be publicly available, if the data is internal use only such as customer Personally Identifiable Information (PII), or if the data is for more restricted access such as intellectual property, legally privileged or marked sensitive, and more. -
SEC-07-03-
Define data protection controls - Protect data according to its classification level. For example, secure data classified as public by using relevant recommendations while protecting sensitive data with additional controls. Automate identification and classification</strong> of data to reduce the risk of human error from manual interactions. SEC-07-02- -
SEC-07-03-
Define data lifecycle management - The defined lifecycle strategy should be based on sensitivity level, as well as legal and organization requirements. Aspects including the duration you retain data for, data destruction, data access management, data transformation, and data sharing should be considered.
8. How do you protect data at rest?
-
SEC-08-01-
Implement secure key management - Encryption keys must be stored securely, with strict access control, for example, by using a key management service such as AWS KMS. Consider using different keys, and access control to the keys, combined with the AWS IAM and resource policies, to align with data classification levels and segregation requirements. -
SEC-08-02-
Enforce encryption at rest - Enforce encryption requirements based on the latest standards and recommendations to help protect data at rest. -
SEC-08-03-
Automate data at rest protection - Use automated tools to validate and enforce data at rest protection continuously, for example, verify that there are only encrypted storage resources. -
SEC-08-04-
Enforce access control - Enforce access control with least privileges and mechanisms, including backups, isolation, and versioning, to help protect data at rest. Prevent operators from granting public access to data. -
SEC-08-05-
Use mechanisms to keep people away from data - Keep all users away from directly accessing sensitive data and systems under normal operational circumstances. For example, provide a dashboard instead of direct access to a data store to run queries. Where CI/CD pipelines are not used, determine which controls and processes are required to adequately provide a normally disabled break-glass access mechanism.
9. How do you protect data in transit?
-
SEC-09-01-TransitKeys
Implement secure key and certificate management - Store encryption keys and certificates securely and rotate them at appropriate time intervals while applying strict access control; for example, by using a certificate management service, such as AWS Certificate Manager (ACM). -
SEC-09-02-EnforceTransit
Enforce encryption in transit - Enforce defined encryption requirements based on appropriate standards and recommendations to help you meet organizational, legal, and compliance requirements. -
SEC-09-03-DetectAccess
Automate detection of unintended data access - Use tools such as GuardDuty to automatically detect attempts to move data outside of defined boundaries based on data classification level, for example, to detect a trojan that is copying data to an unknown or untrusted network using the DNS protocol. -
SEC-09-04-AuthNetComm
Authenticate network communications - Verify the identity of communications by using protocols that support authentication, such as Transport Layer Security (TLS) or IPsec.
10. How do you anticipate, respond to, and recover from incidents?
-
SEC-10-01-
Identify key personnel and external resources - Identify internal and external personnel, resources, and legal obligations that would help the organization respond to an incident. -
SEC-10-02-
Develop incident management plans - Create “playbooks” to help respond to, communicate during, and recover from an incident. For example, start an incident response plan with the most likely scenarios for workloads and organizations. Include how you would communicate and escalate both internally and externally. -
SEC-10-03-
Prepare forensic capabilities - Identify and prepare forensic investigation capabilities that are suitable, including external specialists, tools, and automation. -
SEC-10-04-
Automate containment capability and recovery of an incident to reduce response times and organizational impact. -
SEC-10-05-
Pre-provision access - Ensure that incident responders have the correct access pre-provisioned into AWS to reduce the time for investigation through to recovery. -
SEC-10-06-
Pre-deploy tools - Ensure that security personnel have the right tools pre-deployed into AWS to reduce the time for investigation through to recovery. -
SEC-10-07-
Run game days - Practice incident response game days (simulations) regularly, incorporate lessons learned into incident management plans, and continuously improve.
Reliability pillar

- https://wa.aws.amazon.com/wat.pillar.reliability.en.html
- 110 pages on Kindle (mobile) app
- Microsoft Reliability Documentation
- Google: Reliability
The ability to recover from failures and meet demand: The ability of a system to recover from infrastructure or service disruptions, dynamically acquire computing resources to meet demand, and mitigate disruptions such as misconfigurations or transient network issues.
- Foundations – IAM, Amazon VPC, AWS Trusted Advisor, AWS Shield
- Change Management – AWS CloudTrail, AWS Config, Auto Scaling, Amazon CloudWatch
- Failure Management – AWS CloudFormation, Amazon S3, AWS KMS, Amazon Glacier
- Workload architecture
Design principles for reliability:
- Test recovery procedures
- Automatically recover from failure
- Scale horizontally to increate aggregate system availability
- Stop guessing capacity (scale horizontally and veritically)
- Manage change in automation
Best practice categories for Reliability:
- Manage service quotas and constraints
- Plan network topology
- Design workload service architecture
- Design interactions in a distributed system to prevent failures
- Design interactions in a distributed system to mitigate or withstand failures
- Monitor workload resources
- Design workloads to adapt to changes in demand
- Implement change
- Back up data
- Use fault isolation to protect workloads
- Design workloads to withstand component failures
- Test reliability
- Plan for disaster recovery (DR)
Questions and considerations for Reliability:
1. How do you manage service quotas and constraints?
-
REL-01-01-
Aware of service quotas and constraints - You are aware of default quotas and quota increase requests for workload architecture. You additionally know which resource constraints, such as disk or network, are potentially impactful. -
REL-01-02-
Manage service quotas across accounts and regions - If you are using multiple AWS accounts or AWS Regions, ensure that you request the appropriate quotas in all environments in which production workloads run. -
REL-01-03-
Accommodate fixed service quotas and constraints through architecture - Be aware of unchangeable service quotas and physical resources, and architect to prevent these from impacting reliability. -
REL-01-04-
Monitor and manage quotas - Evaluate potential usage and increase quotas appropriately allowing for planned growth in usage. -
REL-01-05-
Automate quota management - Implement tools to alert you when thresholds are being approached. By using AWS Service Quotas APIs, you can automate quota increase requests. -
REL-01-06-
Ensure that a sufficient gap exists between the current quotas and the maximum usage to accommodate failover - When a resource fails, it may still be counted against quotas until its successfully terminated. Ensure that quotas cover the overlap of all failed resources with replacements before the failed resources are terminated. You should consider an Availability Zone failure when calculating this gap.
2. How do you plan network topology?
-
REL-02-01-
Use highly available network connectivity for workload public endpoints - These endpoints and the routing to them must be highly available. To achieve this, use highly available DNS, content delivery networks (CDNs), API Gateway, load balancing, or reverse proxies. -
REL-02-02-
Provision redundant connectivity between private networks in the cloud and on-premises environments - Use multiple AWS Direct Connect (DX) connections or VPN tunnels between separately deployed private networks. Use multiple DX locations for high availability. If using multiple AWS Regions, ensure redundancy in at least two of them. You might want to evaluate AWS Marketplace appliances that terminate VPNs. If you use AWS Marketplace appliances, deploy redundant instances for high availability in different Availability Zones. -
REL-02-03-
Ensure IP subnet allocation accounts for expansion and availability - Amazon VPC IP address ranges must be large enough to accommodate workload requirements, including factoring in future expansion and allocation of IP addresses to subnets across Availability Zones. This includes load balancers, EC2 instances, and container-based applications. -
REL-02-04-
Prefer hub-and-spoke topologies over many-to-many mesh - If more than two network address spaces (for example, VPCs and on-premises networks) are connected via VPC peering, AWS Direct Connect, or VPN, then use a hub-and-spoke model, like that provided by AWS Transit Gateway. -
REL-02-05-
Enforce non-overlapping private IP address ranges in all private address spaces where they are connected - The IP address ranges of each of VPCs must not overlap when peered or connected via VPN. You must similarly avoid IP address conflicts between a VPC and on-premises environments or with other cloud providers that you use. You must also have a way to allocate private IP address ranges when needed.
3. How do you design workload service architecture?
-
REL-03-01-
Choose how to segment workloads - Monolithic architecture should be avoided. Instead, you should choose between SOA and microservices. When making each choice, balance the benefits against the complexities—what is right for a new product racing to first launch is different than what a workload built to scale from the start needs. The benefits of using smaller segments include greater agility, organizational flexibility, and scalability. Complexities include possible increased latency, more complex debugging, and increased operational burden. -
REL-03-02-
Build services focused on specific business domains and functionality - SOA builds services with well-delineated functions defined by business needs. Microservices use domain models and bounded context to limit this further so that each service does just one thing. Focusing on specific functionality enables you to differentiate the reliability requirements of different services, and target investments more specifically. A concise business problem and having a small team associated with each service also enables easier organizational scaling. -
REL-03-03-
Provide service contracts per API - Service contracts are documented agreements between teams on service integration and include a machine-readable API definition, rate limits, and performance expectations. A versioning strategy allows clients to continue using the existing API and migrate their applications to the newer API when they are ready. Deployment can happen anytime, as long as the contract is not violated. The service provider team can use the technology stack of their choice to satisfy the API contract. Similarly, the service consumer can use their own technology.
4. How do you design interactions in a distributed system to prevent failures?
-
REL-04-01-
Identify which kind of distributed system is required - Hard real-time distributed systems require responses to be given synchronously and rapidly, while soft real-time systems have a more generous time window of minutes or more for response. Offline systems handle responses through batch or asynchronous processing. Hard real-time distributed systems have the most stringent reliability requirements. -
REL-04-02-
Implement loosely coupled dependencies - Dependencies such as queuing systems, streaming systems, workflows, and load balancers are loosely coupled. Loose coupling helps isolate behavior of a component from other components that depend on it, increasing resiliency and agility -
REL-04-03-
Make all responses idempotent - An idempotent service promises that each request is completed exactly once, such that making multiple identical requests has the same effect as making a single request. An idempotent service makes it easier for a client to implement retries without fear that a request will be erroneously processed multiple times. To do this, clients can issue API requests with an idempotency token—the same token is used whenever the request is repeated. An idempotent service API uses the token to return a response identical to the response that was returned the first time that the request was completed. -
REL-04-04-
Do constant work - Systems can fail when there are large, rapid changes in load. For example, a health check system that monitors the health of thousands of servers should send the same size payload (a full snapshot of the current state) each time. Whether no servers are failing, or all of them, the health check system is doing constant work with no large, rapid changes.
5. How do you design interactions in a distributed system to mitigate or withstand failures?
-
REL-05-01-
Implement graceful degradation to transform applicable hard dependencies into soft dependencies - When a component’s dependencies are unhealthy, the component itself can still function, although in a degraded manner. For example, when a dependency call fails, failover to a predetermined static response. -
REL-05-02-
Throttle requests - This is a mitigation pattern to respond to an unexpected increase in demand. Some requests are honored but those over a defined limit are rejected and return a message indicating they have been throttled. The expectation on clients is that they will back off and abandon the request or try again at a slower rate. -
REL-05-03-
Control and limit retry calls - Use exponential backoff to retry after progressively longer intervals. Introduce jitter to randomize those retry intervals, and limit the maximum number of retries. -
REL-05-04-
Fail fast and limit queues - If the workload is unable to respond successfully to a request, then fail fast. This allows the releasing of resources associated with a request, and permits the service to recover if it’s running out of resources. If the workload is able to respond successfully but the rate of requests is too high, then use a queue to buffer requests instead. However, do not allow long queues that can result in serving stale requests that the client has already given up on. -
REL-05-05-
Set client timeouts - Set timeouts appropriately, verify them systematically, and do not rely on default values as they are generally set too high -
REL-05-06-
Make services stateless where possible - Services should either not require state, or should offload state such that between different client requests, there is no dependence on locally stored data on disk or in memory. This enables servers to be replaced at will without causing an availability impact. Amazon ElastiCache or Amazon DynamoDB are good destinations for offloaded state. -
REL-05-07-
Implement emergency levers - These are rapid processes that may mitigate availability impact on workloads. They can be operated in the absence of a root cause. An ideal emergency lever reduces the cognitive burden on the resolvers to zero by providing fully deterministic activation and deactivation criteria. Example levers include blocking all robot traffic or serving a static response. Levers are often manual, but they can also be automated.
6. How do you monitor workload resources?
-
REL-06-01-
Monitor all components for the workload (Generation) - Monitor the components of the workload with Amazon CloudWatch or third-party tools. Monitor AWS services with Personal Health Dashboard -
REL-06-02-
Define and calculate metrics (Aggregation) - Store log data and apply filters where necessary to calculate metrics, such as counts of a specific log event, or latency calculated from log event timestamps -
REL-06-03-
Send notifications (Real-time processing and alarming) - Organizations that need to know, receive notifications when significant events occur -
REL-06-04-
Automate responses (Real-time processing and alarming) - Use automation to take action when an event is detected, for example, to replace failed components -
REL-06-05-
Storage and Analytics - Collect log files and metrics histories and analyze these for broader trends and workload insights -
REL-06-06-
Conduct reviews regularly - Frequently review how workload monitoring is implemented and update it based on significant events and changes -
REL-06-07-
Monitor end-to-end tracing of requests through the system - Use AWS X-Ray or third-party tools so that developers can more easily analyze and debug distributed systems to understand how their applications and its underlying services are performing
7. How do you design workloads to adapt to changes in demand?
-
REL-07-01-
Use automation when obtaining or scaling resources - When replacing impaired resources or scaling workloads, automate the process by using managed AWS services, such as Amazon S3 and AWS Auto Scaling. You can also use third-party tools and AWS SDKs to automate scaling. -
REL-07-02-
Obtain resources upon detection of impairment to a workload - Scale resources reactively when necessary if availability is impacted, to restore workload availability. -
REL-07-03-
Obtain resources upon detection that more resources are needed for a workload - Scale resources proactively to meet demand and avoid availability impact. -
REL-07-04-
Load test workloads - Adopt a load testing methodology to measure if scaling activity meets workload requirements.
8. How do you implement change?
-
REL-08-01-
Use runbooks for standard activities such as deployment - Runbooks are the predefined steps used to achieve specific outcomes. Use runbooks to perform standard activities, whether done manually or automatically. Examples include deploying a workload, patching it, or making DNS modifications. -
REL-08-02-
Integrate functional testing as part of deployments - Functional tests are run as part of automated deployment. If success criteria are not met, the pipeline is halted or rolled back. -
REL-08-03-
Integrate resiliency testing as part of deployments - Resiliency tests (as part of chaos engineering) are run as part of the automated deployment pipeline in a pre-prod environment. -
REL-08-04-
Deploy using immutable infrastructure - This is a model that mandates that no updates, security patches, or configuration changes happen in-place on production workloads. When a change is needed, the architecture is built onto new infrastructure and deployed into production. -
REL-08-05-
Deploy changes with automation - Automate Deployments and patching to eliminate negative impact.
9. How do you back up data?
-
REL-09-01-
Identify and back up all data that needs to be backed up, or reproduce the data from sources - Amazon S3 can be used as a backup destination for multiple data sources. AWS services such as Amazon EBS, Amazon RDS, and Amazon DynamoDB have built in capabilities to create backups. Third-party backup software can also be used. Alternatively, if the data can be reproduced from other sources to meet RPO, you might not require a backup -
REL-09-02-
Secure and encrypt backups - Detect access using authentication and authorization, such as AWS IAM, and detect data integrity compromise by using encryption. -
REL-09-03-
Perform data backup automatically - Configure backups to be taken automatically based on a periodic schedule, or by changes in the dataset. RDS instances, EBS volumes, DynamoDB tables, and S3 objects can all be configured for automatic backup. AWS Marketplace solutions or third-party solutions can also be used. -
REL-09-04-
Perform periodic recovery of the data to verify backup integrity and processes - Validate that backup process implementation meets recovery time objectives (RTO) and recovery point objectives (RPO) by performing a recovery test.
10. How do you use fault isolation to protect workloads?
-
REL-10-01-
Deploy the workload to multiple locations - Distribute workload data and resources across multiple Availability Zones or, where necessary, across AWS Regions. These locations can be as diverse as required. -
REL-10-02-
Automate recovery for components constrained to a single location - If components of the workload can only run in a single Availability Zone or on-premises data center, you must implement the capability to do a complete rebuild of the workload within defined recovery objectives. REL-10-02- -
REL-10-03-
Use bulkhead architectures - Like the bulkheads on a ship, this pattern ensures that a failure is contained to a small subset of requests/users so the number of impaired requests is limited, and most can continue without error. Bulkheads for data are usually called partitions or shards, while bulkheads for services are known as cells.
11. How do you design workloads to withstand component failures?
-
REL-11-01-
Monitor all components of the workload to detect failures - Continuously monitor the health of workloads so that people and automated systems are aware of degradation or complete failure as soon as they occur. Monitor for key performance indicators (KPIs) based on business value. -
REL-11-02-
Fail over to healthy resources - Ensure that if a resource failure occurs, that healthy resources can continue to serve requests. For location failures (such as Availability Zone or AWS Region) ensure you have systems in place to fail over to healthy resources in unimpaired locations. -
REL-11-03-
Automate healing on all layers - Upon detection of a failure, use automated capabilities to perform actions to remediate. -
REL-11-04-
Use static stability to prevent bimodal behavior - Bimodal behavior is when a workload exhibits different behavior under normal and failure modes, for example, relying on launching new instances if an Availability Zone fails. You should instead build workloads that are statically stable and operate in only one mode. In this case, provision enough instances in each Availability Zone to handle the workload load if one AZ were removed and then use Elastic Load Balancing or Amazon Route 53 health checks to shift load away from the impaired instances. -
REL-11-05-
Send notifications when events impact availability - Notifications are sent upon the detection of significant events, even if the issue caused by the event was automatically resolved.
12. How do you test reliability?
-
REL-12-01-
Use playbooks to investigate failures - Enable consistent and prompt responses to failure scenarios that are not well understood, by documenting the investigation process in playbooks. Playbooks are the predefined steps performed to identify the factors contributing to a failure scenario. The results from any process step are used to determine the next steps to take until the issue is identified or escalated. -
REL-12-02-
Perform post-incident analysis - Review customer-impacting events, and identify the contributing factors and preventative action items. Use this information to develop mitigations to limit or prevent recurrence. Develop procedures for prompt and effective responses. Communicate contributing factors and corrective actions as appropriate, tailored to target audiences. Have a method to communicate these causes to others as needed. -
REL-12-03-
Test functional requirements - These include unit tests and integration tests that validate required functionality. -
REL-12-04-
Test scaling and performance requirements - This includes load testing to validate that the workload meets scaling and performance requirements. -
REL-12-05-
Test resiliency using chaos engineering - Run tests that inject failures regularly into pre-production and production environments. Hypothesize how each workload will react to the failure, then compare hypothesis to the testing results and iterate if they do not match. Ensure that production testing does not impact users. -
REL-12-06-
Conduct game days regularly - Use game days to regularly exercise failure procedures as close to production as possible (including in production environments) with the people who will be involved in actual failure scenarios. Game days enforce measures to ensure that production testing does not impact users.
13. How do you plan for disaster recovery (DR)?
-
REL-13-01-
Define recovery objectives for downtime and data loss - The workload has a recovery time objective (RTO) and recovery point objective (RPO). -
REL-13-02-
Use defined recovery strategies to meet the recovery objectives - Define a disaster recovery (DR) strategy to meet objectives. -
REL-13-03-
Test disaster recovery implementation to validate the implementation - Regularly test failover to DR to ensure that RTO and RPO are met. -
REL-13-04-
Manage configuration drift at the DR site or region - Ensure that the infrastructure, data, and configuration are as needed at the DR site or region. For example, check that AMIs and service quotas are up to date. -
REL-13-05-
Automate recovery - Use AWS or third-party tools to automate system recovery and route traffic to the DR site or region.
Ideas:
AWS Reliability hands-on labs:
Operational Excellence pillar

- https://wa.aws.amazon.com/wat.pillar.operationalExcellence.en.html
- 54 pages on Kindle (mobile) app
- AWS Well-Architected Labs for Operational Excellence
- Google: Operational excellence
Processes and procedures to:
- Organize
- Prepare - AWS Config
- Operate - Amazon CloudWatch
- Evolve - Amazon Elasticsearch service
Transcend challenges in traditional workplaces:
- Manual changes
- Batch changes
- Rarely run Game Days
- No time to learn from mistakes
- Stale documentation
Best practices:
- Monitoring and diagnostics
Design Principles for Operational Excellence:
- Manual changes -> Perform operations as code
- Annotate documentation (among code)
- Batch changes -> Make frequent, small, reversible change
- Refine operations procedures frequently
- Anticipate failure
- Learn from all operational failures
Best practice categories for Operational Excellence:
- Determine what operational priorities are
- Structure the organization to support business outcomes
- Organizational culture support business outcomes
- Design workloads to understand its state
- Reduce defects, ease remediation, and improve flow into production
- Mitigate deployment risks
- Ready to support a workload
- Understand the health of each workload
- Understand the health of operations
- Manage workload and operations events
- Evolve operations
Questions and Considerations for Operational Excellence:
1. How do you determine what operational priorities are?
-
OPS-01-01-
Evaluate external customer needs - Involve key stakeholders, including business, development, and operations teams, to determine where to focus efforts on external customer needs. This will ensure that you have a thorough understanding of the operations support that is required to achieve desired business outcomes. -
OPS-01-02-
Evaluate internal customer needs - Involve key stakeholders, including business, development, and operations teams, when determining where to focus efforts on internal customer needs. This will ensure that you have a thorough understanding of the operations support that is required to achieve business outcomes. -
OPS-01-03-
Evaluate governance requirements - Ensure awareness of guidelines or obligations defined by organization that may mandate or emphasize specific focus. Evaluate internal factors, such as organization policy, standards, and requirements. Validate that you have mechanisms to identify changes to governance. If no governance requirements are identified, ensure that you have applied due diligence to this determination. -
OPS-01-04-
Evaluate compliance requirements - Evaluate external factors, such as regulatory compliance requirements and industry standards, to ensure that you are aware of guidelines or obligations that may mandate or emphasize specific focus. If no compliance requirements are identified, ensure that you apply due diligence to this determination. -
OPS-01-05-
Evaluate threat landscape - Evaluate threats to the business (for example, competition, business risk and liabilities, operational risks, and information security threats) and maintain current information in a risk registry. Include the impact of risks when determining where to focus efforts. -
OPS-01-06-
Evaluate tradeoffs - Evaluate the impact of tradeoffs between competing interests or alternative approaches, to help make informed decisions when determining where to focus efforts or choosing a course of action. For example, accelerating speed to market for new features may be emphasized over cost optimization, or you may choose a relational database for non-relational data to simplify the effort to migrate a system, rather than migrating to a database optimized by data type and updating application. -
OPS-01-07-
Manage benefits and risks - Manage benefits and risks to make informed decisions when determining where to focus efforts. For example, it may be beneficial to deploy a workload with unresolved issues so that significant new features can be made available to customers. It may be possible to mitigate associated risks, or it may become unacceptable to allow a risk to remain, in which case you will take action to address the risk.
2. How do you structure the organization to support business outcomes?
aka the “Operating Model”
-
OPS-02-01-
Resources have identified owners - Understand who has ownership of each application, workload, platform, and infrastructure component, what business value is provided by that component, and why that ownership exists. Understanding the business value of these individual components and how they support business outcomes informs the processes and procedures applied against them. -
OPS-02-02-
Processes and procedures have identified owners - Understand who has ownership of the definition of individual processes and procedures, why those specific process and procedures are used, and why that ownership exists. Understanding the reasons that specific processes and procedures are used enables identification of improvement opportunities. -
OPS-02-03-
Operations activities have identified owners responsible for their performance - Understand who has responsibility to perform specific activities on defined workloads and why that responsibility exists. Understanding who has responsibility to perform activities informs who will conduct the activity, validate the result, and provide feedback to the owner of the activity. -
OPS-02-04-
Team members know what they are responsible for - Understanding the responsibilities of each role and how they contribute to business outcomes informs the prioritization of tasks and why each role is important. This enables team members to recognize needs and respond appropriately. -
OPS-02-05-
Mechanisms exist to identify responsibility and ownership - Where no individual or team is identified, there are defined escalation paths to someone with the authority to assign ownership or plan for that need to be addressed. -
OPS-02-06-
Mechanisms exist to request additions, changes, and exceptions - You are able to make requests to owners of processes, procedures, and resources. Make informed decisions to approve requests where viable and determined to be appropriate after an evaluation of benefits and risks. -
OPS-02-07-
Responsibilities between teams are predefined or negotiated - There are defined or negotiated agreements between teams describing how they work with and support each other (for example, response times, service objectives, or service agreements). Understanding the impact of the teams’ work on business outcomes, and the outcomes of other teams and organizations, informs the prioritization of their tasks and enables them to respond appropriately.
3. How does organizational culture support business outcomes?
-
OPS-03-01-
Executive Sponsorship - Senior leadership clearly sets expectations for the organization and evaluates success. Senior leadership is the sponsor, advocate, and driver for the adoption of best practices and evolution of the organization -
OPS-03-02-
Team members are empowered to take action when outcomes are at risk - The workload owner has defined guidance and scope empowering team members to respond when outcomes are at risk. Escalation mechanisms are used to get direction when events are outside of the defined scope. -
OPS-03-03-
Escalation is encouraged - Team members have mechanisms and are encouraged to escalate concerns to decision makers and stakeholders if they believe outcomes are at risk. Escalation should be performed early and often so that risks can be identified, and prevented from causing incidents. -
OPS-03-04-
Communications are timely, clear, and actionable - Mechanisms exist and are used to provide timely notice to team members of known risks and planned events. Necessary context, details, and time (when possible) are provided to support determining if action is necessary, what action is required, and to take action in a timely manner. For example, providing notice of software vulnerabilities so that patching can be expedited, or providing notice of planned sales promotions so that a change freeze can be implemented to avoid the risk of service disruption. -
OPS-03-05-
Experimentation is encouraged - Experimentation accelerates learning and keeps team members interested and engaged. An undesired result is a successful experiment that has identified a path that will not lead to success. Team members are not punished for successful experiments with undesired results. Experimentation is required for innovation to happen and turn ideas into outcomes. -
OPS-03-06-
Team members are enabled and encouraged to maintain and grow their skill sets - Teams must grow their skill sets to adopt new technologies, and to support changes in demand and responsibilities in support of workloads. Growth of skills in new technologies is frequently a source of team member satisfaction and supports innovation. Support team members’ pursuit and maintenance of industry certifications that validate and acknowledge their growing skills. Cross train to promote knowledge transfer and reduce the risk of significant impact when you lose skilled and experienced team members with institutional knowledge. Provide dedicated structured time for learning. -
OPS-03-07-
Resource teams appropriately - Maintain team member capacity, and provide tools and resources, to support workload needs. Overtasking team members increases the risk of incidents resulting from human error. Investments in tools and resources (for example, providing automation for frequently executed activities) can scale the effectiveness of the team, enabling them to support additional activities. -
OPS-03-08-
Diverse opinions are encouraged and sought within and across teams - Leverage cross-organizational diversity to seek multiple unique perspectives. Use this perspective to increase innovation, challenge assumptions, and reduce the risk of confirmation bias. Grow inclusion, diversity, and accessibility within teams to gain beneficial perspectives.
4. How do you design workloads to understand its state?
-
OPS-04-01-
Implement application telemetry - Instrument application code to emit information about its internal state, status, and achievement of business outcomes. For example, queue depth, error messages, and response times. Use this information to determine when a response is required. -
OPS-04-02-
Implement and configure workload telemetry - Design and configure workloads to emit information about its internal state and current status. For example, API call volume, HTTP status codes, and scaling events. Use this information to help determine when a response is required. -
OPS-04-03-
Implement user activity telemetry - Instrument application code to emit information about user activity, for example, click streams, or started, abandoned, and completed transactions. Use this information to help understand how the application is used, patterns of usage, and to determine when a response is required. -
OPS-04-04-
Implement dependency telemetry - Design and configure workloads to emit information about the status (for example, reachability or response time) of resources it depends on. Examples of external dependencies can include, external databases, DNS, and network connectivity. Use this information to determine when a response is required. -
OPS-04-05-
Implement transaction traceability - Implement application code and configure workload components to emit information about the flow of transactions across the workload. Use this information to determine when a response is required and to assist you in identifying the factors contributing to an issue.
5. How do you reduce defects, ease remediation, and improve flow into production?
-
OPS-05-01-
Use version control - Use version control to enable tracking of changes and releases. -
OPS-05-02-
Test and validate changes - Test and validate changes to help limit and detect errors. Automate testing to reduce errors caused by manual processes, and reduce the effort to test. -
OPS-05-03-
Use configuration management systems - Use configuration management systems to make and track configuration changes. These systems reduce errors caused by manual processes and reduce the effort to deploy changes. -
OPS-05-04-
Use build and deployment management systems - Use build and deployment management systems. These systems reduce errors caused by manual processes and reduce the effort to deploy changes. -
OPS-05-05-
Perform patch management - Perform patch management to gain features, address issues, and remain compliant with governance. Automate patch management to reduce errors caused by manual processes, and reduce the effort to patch. -
OPS-05-06-
Share design standards - Share best practices across teams to increase awareness and maximize the benefits of development efforts. -
OPS-05-07-
Implement practices to improve code quality - Implement practices to improve code quality and minimize defects. For example, test-driven development, code reviews, and standards adoption. -
OPS-05-08-
Use multiple environments - Use multiple environments to experiment, develop, and test workloads. Use increasing levels of controls as environments approach production to gain confidence each workload will operate as intended when deployed. -
OPS-05-09-
Make frequent, small, reversible changes - Frequent, small, and reversible changes reduce the scope and impact of a change. This eases troubleshooting, enables faster remediation, and provides the option to roll back a change. -
OPS-05-10-
Fully automate integration and deployment - Automate build, deployment, and testing of the workload. This reduces errors caused by manual processes and reduces the effort to deploy changes.
6. How do you mitigate deployment risks?
-
OPS-06-01-
Plan for unsuccessful changes - Plan to revert to a known good state, or remediate in the production environment if a change does not have the desired outcome. This preparation reduces recovery time through faster responses. -
OPS-06-02-
Test and validate changes - Test changes and validate the results at all lifecycle stages to confirm new features and minimize the risk and impact of failed deployments. -
OPS-06-03-
Use deployment management systems - Use deployment management systems to track and implement change. This reduces errors cause by manual processes and reduces the effort to deploy changes. -
OPS-06-04-
Test using limited deployments - Test with limited deployments alongside existing systems to confirm desired outcomes prior to full scale deployment. For example, use deployment canary testing or one-box deployments. -
OPS-06-05-
Deploy using parallel environments - Implement changes onto parallel environments, and then transition over to the new environment. Maintain the prior environment until there is confirmation of successful deployment. Doing so minimizes recovery time by enabling rollback to the previous environment. -
OPS-06-06-
Deploy frequent, small, reversible changes - Use frequent, small, and reversible changes to reduce the scope of a change. This results in easier troubleshooting and faster remediation with the option to roll back a change. -
OPS-06-07-
Fully automate integration and deployment - Automate build, deployment, and testing of the workload. This reduces errors cause by manual processes and reduces the effort to deploy changes. -
OPS-06-08-
Automate testing and rollback - Automate testing of deployed environments to confirm desired outcomes. Automate rollback to previous known good state when outcomes are not achieved to minimize recovery time and reduce errors caused by manual processes.
7. How do you know that you are ready to support a workload?
-
OPS-07-01-
Ensure personnel capability - Have a mechanism to validate that you have the appropriate number of trained personnel to provide support for operational needs. Train personnel and adjust personnel capacity as necessary to maintain effective support. -
OPS-07-02-
Ensure consistent review of operational readiness - Ensure you have a consistent review of readiness to operate a workload. Reviews must include, at a minimum, the operational readiness of the teams and the workload, and security requirements. Implement review activities in code and trigger automated review in response to events where appropriate, to ensure consistency, speed of execution, and reduce errors caused by manual processes. -
OPS-07-03-
Use runbooks to perform procedures - Runbooks are documented procedures to achieve specific outcomes. Enable consistent and prompt responses to well-understood events by documenting procedures in runbooks. Implement runbooks as code and trigger the execution of runbooks in response to events where appropriate, to ensure consistency, speed responses, and reduce errors caused by manual processes. -
OPS-07-04-
Use playbooks to investigate issues - Enable consistent and prompt responses to issues that are not well understood, by documenting the investigation process in playbooks. Playbooks are the predefined steps performed to identify the factors contributing to a failure scenario. The results from any process step are used to determine the next steps to take until the issue is identified or escalated. -
OPS-07-05-
Make informed decisions to deploy systems and changes - Evaluate the capabilities of the team to support the workload and the workload’s compliance with governance. Evaluate these against the benefits of deployment when determining whether to transition a system or change into production. Understand the benefits and risks to make informed decisions.
8. How do you understand the health of each workload?
-
OPS-08-01-
Identify key performance indicators (KPIs) based on desired business outcomes (for example, order rate, customer retention rate, and profit versus operating expense) and customer outcomes (for example, customer satisfaction). Evaluate KPIs to determine workload success. -
OPS-08-02-
Define workload metrics - Define workload metrics to measure the achievement of KPIs (for example, abandoned shopping carts, orders placed, cost, price, and allocated workload expense). Define workload metrics to measure the health of the workload (for example, interface response time, error rate, requests made, requests completed, and utilization). Evaluate metrics to determine if the workload is achieving desired outcomes, and to understand the health of the workload. -
OPS-08-03-
Collect and analyze workload metrics - Perform regular proactive reviews of metrics to identify trends and determine where appropriate responses are needed. -
OPS-08-04-
Establish workload metrics baselines to provide expected values as the basis for comparison and identification of under and over performing components. Identify thresholds for improvement, investigation, and intervention. -
OPS-08-05-
Learn expected patterns of activity for workload - Establish patterns of workload activity to identify anomalous behavior so that you can respond appropriately if required. -
OPS-08-06-
Alert when workload outcomes are at risk - Raise an alert when workload outcomes are at risk so that you can respond appropriately if necessary. -
OPS-08-07-
Alert when workload anomalies are detected - Raise an alert when workload anomalies are detected so that you can respond appropriately if necessary. -
OPS-08-08-
Validate the achievement of outcomes and the effectiveness of KPIs and metrics - Create a business-view of workload operations to help you determine if you are satisfying needs and to identify areas that need improvement to reach business goals. Validate the effectiveness of KPIs and metrics and revise them if necessary.
9. How do you understand the health of operations?
-
OPS-09-01-
Identify key performance indicators (KPIs) based on desired business (for example, new features delivered) and customer outcomes (for example, customer support cases). Evaluate KPIs to determine operations success. -
OPS-09-02-
Define operations metrics to measure the achievement of KPIs (for example, successful deployments, and failed deployments). Define operations metrics to measure the health of operations activities (for example, mean time to detect an incident (MTTD), and mean time to recovery (MTTR) from an incident). Evaluate metrics to determine if operations are achieving desired outcomes, and to understand the health of operations activities. -
OPS-09-03-
Collect and analyze operations metrics - Perform regular, proactive reviews of metrics to identify trends and determine where appropriate responses are needed. -
OPS-09-04-
Establish operations metrics baselines to provide expected values as the basis for comparison and identification of under and over performing operations activities. -
OPS-09-05-
Learn the expected patterns of activity for operations to identify anomalous activity so that you can respond appropriately if necessary. -
OPS-09-06-
Alert when operations outcomes are at risk - Raise an alert when operations outcomes are at risk so that you can respond appropriately if necessary. -
OPS-09-07-
Alert when operations anomalies are detected so that you can respond appropriately if necessary. -
OPS-09-08-
Validate the achievement of outcomes and the effectiveness of KPIs and metrics - Create a business-view of operations activities to help you determine if you are satisfying needs and to identify areas that need improvement to reach business goals. Validate the effectiveness of KPIs and metrics and revise them if necessary.
9. How do you manage workload and operations events?
-
OPS-10-01-
Use processes for event, incident, and problem management - Have processes to address observed events, events that require intervention (incidents), and events that require intervention and either recur or cannot currently be resolved (problems). Use these processes to mitigate the impact of these events on the business and customers by ensuring timely and appropriate responses. -
OPS-10-02-
Have a process per alert - Have a well-defined response (runbook or playbook), with a specifically identified owner, for any event for which you raise an alert. This ensures effective and prompt responses to operations events and prevents actionable events from being obscured by less valuable notifications. -
OPS-10-03-
Prioritize operational events based on business impact - Ensure that when multiple events require intervention, those that are most significant to the business are addressed first. For example, impacts can include loss of life or injury, financial loss, or damage to reputation or trust. -
OPS-10-04-
Define escalation paths - Define escalation paths in runbooks and playbooks, including what triggers escalation, and procedures for escalation. Specifically identify owners for each action to ensure effective and prompt responses to operations events. -
OPS-10-05-
Enable push notifications - Communicate directly with users (for example, with email or SMS) when the services they use are impacted, and again when the services return to normal operating conditions, to enable users to take appropriate action. -
OPS-10-06-
Communicate status through dashboards - Provide dashboards tailored to their target audiences (for example, internal technical teams, leadership, and customers) to communicate the current operating status of the business and provide metrics of interest. -
OPS-10-07-
Automate responses to events - Automate responses to events to reduce errors caused by manual processes, and to ensure prompt and consistent responses.
9. How do you evolve operations?
-
OPS-11-01-
Have a process for continuous improvement - Regularly evaluate and prioritize opportunities for improvement to focus efforts where they can provide the greatest benefits. -
OPS-11-02-
Perform post-incident analysis - Review customer-impacting events, and identify the contributing factors and preventative actions. Use this information to develop mitigations to limit or prevent recurrence. Develop procedures for prompt and effective responses. Communicate contributing factors and corrective actions as appropriate, tailored to target audiences. -
OPS-11-03-
Implement feedback loops - Include feedback loops in procedures and workloads to help you identify issues and areas that need improvement. -
OPS-11-04-
Perform Knowledge Management - Mechanisms exist for team members to discover the information that they are looking for in a timely manner, access it, and identify that it’s current and complete. Mechanisms are present to identify needed content, content in need of refresh, and content that should be archived so that it’s no longer referenced. -
OPS-11-05-
Define drivers for improvement - Identify drivers for improvement to help you evaluate and prioritize opportunities. -
OPS-11-06-
Validate insights - Review analysis results and responses with cross-functional teams and business owners. Use these reviews to establish common understanding, identify additional impacts, and determine courses of action. Adjust responses as appropriate. -
OPS-11-07-
Perform operations metrics reviews - Regularly perform retrospective analysis of operations metrics with cross-team participants from different areas of the business. Use these reviews to identify opportunities for improvement, potential courses of action, and to share lessons learned. -
OPS-11-08-
Document and share lessons learned from the execution of operations activities so that you can use them internally and across teams. -
OPS-11-09-
Allocate time to make improvements - Dedicate time and resources within processes to make continuous incremental improvements possible.
AWS Operational Excellence hands-on labs:
Performance Efficiency pillar
- https://wa.aws.amazon.com/wat.pillar.performance.en.html
- 51 pages on Kindle (mobile) app
- Google: Performance optimization
Principles:
- Selection – Auto Scaling for Compute, Amazon EBS and S3 for Storage, Amazon RDS and DynamoDB for Database, Route53, VPC, and AWS Direct Connect for Network
- Review – AWS Blog and What’s New section of the website
- Monitoring – Amazon CloudWatch
- Tradeoffs – Amazon Elasticache, Amazon CloudFront, AWS Snowball, Amazon RDS read replicas.
Best practices:
- Autoscaling
- Background jobs
- Caching
- CDN
- Data partitioning
Design principles for Performance Efficiency:
- Democratize advanced technologies
- Go global in minutes
- Use serverless architectures
- Experiment more often
- Mechanical sympathy
Best practice categories for Performance Efficiency:
- Select the best performing architecture
- Select the compute solution
- Select storage solutions
- Select database solutions
- Configure networking solutions
- Evolve each workload to take advantage of new releases
- Monitor resources to ensure they are performing
- Use tradeoffs to improve performance
Questions and Considerations for Performance Efficiency:
1. How do you select the best performing architecture?
-
PERF-01-IdentifySvcs
Understand the available services and resources - Learn about and understand the wide range of services and resources available in the cloud. Identify the relevant services and configuration options for each workload, and understand how to achieve optimal performance. -
PERF-01-02-
Define a process for architectural choices - Use internal experience and knowledge of the cloud, or external resources such as published use cases, relevant documentation, or whitepapers to define a process to choose resources and services. You should define a process that encourages experimentation and benchmarking with the services that could be used by workloads. -
PERF-01-03-
Factor cost requirements into decisions - Workloads often have cost requirements for operation. Use internal cost controls to select resource types and sizes based on predicted resource need. -
PERF-01-04-
Use policies or reference architectures - Maximize performance and efficiency by evaluating internal policies and existing reference architectures and using analysis to select services and configurations for each workload. -
PERF-01-05-
Use guidance from cloud providers or partners - Use cloud company resources, such as solutions architects, professional services, or an appropriate partner to guide decisions. These resources can help review and improve the architecture for optimal performance. -
PERF-01-06-
Benchmark existing workloads - Benchmark the performance of an existing workload to understand how it performs on the cloud. Use the data collected from benchmarks to drive architectural decisions. -
PERF-01-07-
Load test workloads - Deploy the latest workload architecture on the cloud using different resource types and sizes. Monitor the deployment to capture performance metrics that identify bottlenecks or excess capacity. Use this performance information to design or improve architecture and resource selection.
2. How do you select the compute solution?
-
PERF-02-01-
Evaluate the available compute options - Understand the performance characteristics of the compute-related options available to you. Know how instances, containers, and functions work, and what advantages, or disadvantages, they bring to workloads. -
PERF-02-02-
Understand the available compute configuration options - Understand how various options complement workloads, and which configuration options are best for the system. Examples of these options include instance family, sizes, features (GPU, I/O), function sizes, container instances, and single versus multi-tenancy. -
PERF-02-03-
Collect compute-related metrics - One of the best ways to understand how compute systems are performing is to record and track the true utilization of various resources. This data can be used to make more accurate determinations about resource requirements. -
PERF-02-04-
Determine the required configuration by right-sizing - Analyze the various performance characteristics of each workload and how these characteristics relate to memory, network, and CPU usage. Use this data to choose resources that best match each workload’s profile. For example, a memory-intensive workload, such as a database, could be served best by the r-family of instances. However, a bursting workload can benefit more from an elastic container system. -
PERF-02-05-
Use the available elasticity of resources - The cloud provides the flexibility to expand or reduce resources dynamically through a variety of mechanisms to meet changes in demand. Combined with compute-related metrics, a workload can automatically respond to changes and utilize the optimal set of resources to achieve its goal. -
PERF-02-06-
Re-evaluate compute needs based on metrics - Use system-1. [Terraform] metrics to identify the behavior and requirements of workloads over time. Evaluate workload needs by comparing the available resources with these requirements and make changes to compute environment to best match each workload’s profile. For example, over time a system might be observed to be more memory-intensive than initially thought, so moving to a different instance family or size could improve both performance and efficiency.
3. How do you select storage solutions?
-
PERF-03-01-
Understand storage characteristics and requirements - Understand the different characteristics (for example, shareable, file size, cache size, access patterns, latency, throughput, and persistence of data) that are required to select the services that best fit the workload, such as object storage, block storage, file storage, or instance storage. -
PERF-03-04-
Evaluate available configuration options - Evaluate the various characteristics and configuration options and how they relate to storage. Understand where and how to use provisioned IOPS, SSDs, magnetic storage, object storage, archival storage, or ephemeral storage to optimize storage space and performance for each workload. -
PERF-03-05-
Make decisions based on access patterns and metrics - Choose storage systems based on each workload’s access patterns and configure them by determining how the workload accesses data. Increase storage efficiency by choosing object storage over block storage. Configure the storage options you choose to match data access patterns.
4. How do you select database solutions?
-
PERF-04-01-
Understand data characteristics - Understand the different characteristics of data in each workload. Determine if the workload requires transactions, how it interacts with data, and what its performance demands are. Use this data to select the best performing database approach for each workload (for example, relational databases, NoSQL Key-value, document, wide column, graph, time series, or in-memory storage). -
PERF-04-02-
Evaluate the available options - Evaluate the services and storage options that are available as part of the selection process for each workload’s storage mechanisms. Understand how, and when, to use a given service or system for data storage. Learn about available configuration options that can optimize database performance or efficiency, such as provisioned IOPs, memory and compute resources, and caching. -
PERF-04-03-
Collect and record database performance metrics - Use tools, libraries, and systems that record performance measurements related to database performance. For example, measure transactions per second, slow queries, or system latency introduced when accessing the database. Use this data to understand the performance of database systems. -
PERF-04-04-
Choose data storage based on access patterns - Use the access patterns of the workload to decide which services and technologies to use. For example, utilize a relational database for workloads that require transactions, or a key-value store that provides higher throughput but is eventually consistent where applicable. -
PERF-04-05-
Optimize data storage based on access patterns and metrics - Use performance characteristics and access patterns that optimize how data is stored or queried to achieve the best possible performance. Measure how optimizations such as indexing, key distribution, data warehouse design, or caching strategies impact system performance or overall efficiency.
5. How do you configure networking solutions?
-
PERF-05-01-
Understand how networking impacts performance - Analyze and understand how network-related decisions impact workload performance. For example, network latency often impacts the user experience, and using the wrong protocols can starve network capacity through excessive overhead. -
PERF-05-02-
Evaluate available networking features - Evaluate networking features in the cloud that may increase performance. Measure the impact of these features through testing, metrics, and analysis. For example, take advantage of network- features that are available to reduce latency, network distance, or jitter. -
PERF-05-03-
Choose appropriately sized dedicated connectivity or VPN for hybrid workloads - When there is a requirement for on-premise communication, ensure that you have adequate bandwidth for workload performance. Based on bandwidth requirements, a single dedicated connection or a single VPN might not be enough, and you must enable traffic load balancing across multiple connections. -
PERF-05-04-
Leverage load-balancing and encryption offloading - Distribute traffic across multiple resources or services to allow each workload to take advantage of the elasticity that the cloud provides. You can also use load balancing for offloading encryption termination to improve performance and to manage and route traffic effectively. -
PERF-05-05-
Choose network protocols to improve performance - Make decisions about protocols for communication between systems and networks based on the impact to the workload’s performance. -
PERF-05-06-
Choose each workload’s location based on network requirements - Use the cloud location options available to reduce network latency or improve throughput. Utilize AWS Regions, Availability Zones, placement groups, and edge locations such as Outposts, Local Regions, and Wavelength, to reduce network latency or improve throughput. -
PERF-05-07-
Optimize network configuration based on metrics - Use collected and analyzed data to make informed decisions about optimizing network configuration. Measure the impact of those changes and use the impact measurements to make future decisions.
-
How do you evolve each workload to take advantage of new releases?
-
PERF-06-01-
Stay up-to-date on new resources and services - Evaluate ways to improve performance as new services, design patterns, and product offerings become available. Determine which of these could improve performance or increase the efficiency of the workload through ad-hoc evaluation, internal discussion, or external analysis. -
PERF-06-02-
Define a process to improve workload performance - Evaluate new services, design patterns, resource types, and configurations as they become available. For example, run existing performance tests on new instance offerings to determine their potential to improve the workload. -
PERF-06-03-
Evolve workload performance over time - As an organization, use the information gathered through the evaluation process to actively drive adoption of new services or resources when they become available.
-
-
How do you monitor resources to ensure they are performing?
-
PERF-07-01-
Record performance-related metrics - Use a monitoring and observability service to record performance-related metrics. For example, record database transactions, slow queries, I/O latency, HTTP request throughput, service latency, or other key data. -
PERF-07-02-
Analyze metrics when events or incidents occur - In response to (or during) an event or incident, use monitoring dashboards or reports to understand and diagnose the impact. These views provide insight into which portions of the workload are not performing as expected. -
PERF-07-03-
Establish Key Performance Indicators (KPIs) to measure workload performance - Identify the KPIs that indicate whether the workload is performing as intended. For example, an API-based workload might use overall response latency as an indication of overall performance, and an e-commerce site might choose to use the number of purchases as its KPI. -
PERF-07-04-
Use monitoring to generate alarm-based notifications - Using the performance-related key performance indicators (KPIs) that you defined, use a monitoring system that generates alarms automatically when these measurements are outside expected boundaries. -
PERF-07-05-
Review metrics at regular intervals - As routine maintenance, or in response to events or incidents, review which metrics are collected. Use these reviews to identify which metrics were key in addressing issues and which additional metrics, if they were being tracked, would help to identify, address, or prevent issues. -
PERF-07-06-
Monitor and alarm proactively - Use key performance indicators (KPIs), combined with monitoring and alerting systems, to proactively address performance-related issues. Use alarms to trigger automated actions to remediate issues where possible. Escalate the alarm to those able to respond if automated response is not possible. For example, you may have a system that can predict expected key performance indicators (KPI) values and alarm when they breach certain thresholds, or a tool that can automatically halt or roll back deployments if KPIs are outside of expected values.
-
-
How do you use tradeoffs to improve performance?
-
PERF-08-01-
Understand the areas where performance is most critical - Understand and identify areas where increasing the performance of the workload will have a positive impact on efficiency or customer experience. For example, a website that has a large amount of customer interaction can benefit from using edge services to move content delivery closer to customers. -
PERF-08-02-
Learn about design patterns and services - Research and understand the various design patterns and services that help improve workload performance. As part of the analysis, identify what you could trade to achieve higher performance. For example, using a cache service can help to reduce the load placed on database systems; however, it requires some engineering to implement safe caching or possible introduction of eventual consistency in some areas. -
PERF-08-03-
Identify how tradeoffs impact customers and efficiency - When evaluating performance-related improvements, determine which choices will impact customers and workload efficiency. For example, if using a key-value data store increases system performance, it is important to evaluate how the eventually consistent nature of it will impact customers. -
PERF-08-04-
Measure the impact of performance improvements - As changes are made to improve performance, evaluate the collected metrics and data. Use this information to determine impact that the performance improvement had on the workload, the workload’s components, and customers. This measurement helps you understand the improvements that result from the tradeoff, and helps you determine if any negative side-effects were introduced. -
PERF-08-05-
Use various performance-related strategies - Where applicable, utilize multiple strategies to improve performance. For example, using strategies like caching data to prevent excessive network or database calls, using read-replicas for database engines to improve read rates, sharding or compressing data where possible to reduce data volumes, and buffering and streaming of results as they are available to avoid blocking.
-
AWS Performance hands-on labs:
Cost Optimization pillar

- Summary
- Cost Optimization Pillar whitepaper (June 2020) HTML,PDF, 44 pages on Kindle (mobile) app
-
AWS Well-Architected Labs for Cost Optimization by Nathan Besh
-
https://aws.amazon.com/blogs/aws-cloud-financial-management/
- Microsoft Cost Optimization Documentation | Checklist
- Google: Cost optimization
Google’s Cost Optimization has two processes:
AWS Cost Optimization Abstract:
- Practice Cloud Financial Management
- Expenditure and Usage Awareness
- Cost Effective Resources
- Manage Demand and Supply Resources
- Optimize Over Time
Best practice categories for Cost Optimization:
- Implement cloud financial management
- Govern usage
- Monitor usage and cost
- Decommission resources
- Evaluate when you select services
- Meet targets when you select resource type, size, and number
- Use pricing models to reduce cost
- Plan for data transfer charges
- Manage demand, and supply resources
- Evaluate new services
Questions and Considerations for Cost Optimization:
-
How do you implement cloud financial management?
Best practices and Improvement Plan items:
-
COST-01-01-
Establish a cost optimization function - Create a team that is responsible for establishing and maintaining cost awareness across the organization. The team requires people from finance, technology, and business roles across the organization. -
COST-01-02-
Establish a partnership between finance and technology - Involve finance and technology teams in cost and usage discussions at all stages of the cloud journey. Teams regularly meet and discuss topics such as organizational goals and targets, current state of cost and usage, and financial and accounting practices. -
COST-01-03-
Establish cloud budgets and forecasts - Adjust existing organizational budgeting and forecasting processes to be compatible with the highly variable nature of cloud costs and usage. Processes must be dynamic using trend based or business driver-based algorithms, or a combination. -
COST-01-04-
Implement cost awareness into new or existing processes that impact usage, and leverage existing processes for cost awareness. Implement cost awareness into employee training. -
COST-01-05-
Report and notify on cost optimization - Configure AWS Budgets to provide notifications on cost and usage against targets. Have regular meetings to analyze this workload’s cost efficiency and to promote cost aware culture. -
COST-01-05-
Monitor cost proactively - Implement tooling and dashboards to monitor cost proactively for the workload. Do not just look at costs and categories when you receive notifications. This helps to identify positive trends and promote them throughout the organization. -
COST-01-07-
Keep up to date with new service releases - Consult regularly with experts or APN Partners to consider which services and features provide lower cost. Review AWS blogs and other information sources.
-
-
How do you govern usage?
-
COST-02-01-
Develop policies based on organization requirements - Develop policies that define how resources are managed by the organization. Policies should cover cost aspects of resources and workloads, including creation, modification and decommission over the resource lifetime. -
COST-02-02-
Implement both cost and usage goals for each workload - Goals provide direction to the organization on cost and usage, and targets provide measurable outcomes for each workload. -
COST-02-03-
Implement an account structure that maps to the organization. This assists in allocating and managing costs throughout the organization. -
COST-02-04-
Implement groups and roles that align to policies and control who can create, modify, or decommission instances and resources in each group. For example, implement development, test, and production groups. This applies to AWS services and third-party solutions. -
COST-02-05-
Implement cost controls based on organization policies and defined groups and roles. These ensure that costs are only incurred as defined by organization requirements: for example, control access to regions or resource types with IAM policies. -
COST-02-06-
Track project lifecycle - measure, and audit the lifecycle of projects, teams, and environments to avoid using and paying for unnecessary resources.
-
-
How do you monitor usage and cost?
-
COST-03-01-
Configure detailed information sources - Configure the AWS Cost and Usage Report, and Cost Explorer hourly granularity, to provide detailed cost and usage information. Configure workloads to have log entries for every delivered business outcome. -
COST-03-02-
Identify cost attribution categories that could be used to allocate cost within the organization. -
COST-03-03-
Establish organization metrics required for each workload. Example metrics of a workload are customer reports produced or web pages served to customers. -
COST-03-04-
Configure billing and cost management tools - Configure AWS Cost Explorer and AWS Budgets inline with organization policies. -
COST-03-05-
Add organization information to cost and usage - Define a tagging schema based on organization, and workload attributes, and cost allocation categories. -
COST-03-06-
Implement tagging across all resources. - Use Cost Categories to group costs and usage according to organization attributes. -
COST-03-07-
Allocate costs based on workload metrics - Allocate the workload’s costs by metrics or business outcomes to measure workload cost efficiency. Implement a process to analyze the AWS Cost and Usage Report with Amazon Athena, which can provide insight and charge back capability.
-
-
How do you decommission resources?
- Plan ahead. Announce.
- Genereate Terraform files for all AWS services
-
Archive to AWS Glacier. Test retrieval.
-
COST-04-01-
Track resources over their life time - Define and implement a method to track resources and their associations with systems over their life time. You can use tagging to identify the workload or function of the resource. -
COST-04-02-
Implement a decommissioning process - Implement a process to identify and decommission orphaned resources. -
COST-04-03-
Decommission resources triggered by events such as periodic audits, or changes in usage. Decommissioning is typically performed periodically, and is manual or automated. - COST-04-04-
Decommission resources automatically - Design workloads to gracefully handle resource termination as you identify and decommission non-critical resources, resources that are not required, or resources with low utilization.
-
How do you evaluate when you select services?
-
COST-05-01-
Identify organization requirements for cost - Work with team members to define the balance between cost optimization and other pillars, such as performance and reliability, for this workload. -
COST-05-02-
Analyze all components of this workload - Ensure every workload component is analyzed, regardless of current size or current costs. Review effort should reflect potential benefit, such as current and projected costs. -
COST-05-03-
Perform a thorough analysis of each component - the overall cost of each component. Look at total cost of ownership by factoring in cost of operations and management, especially when using managed services. Review effort should reflect potential benefit: for example, time spent analyzing is proportional to component cost. -
COST-05-04-
Select software with cost effective licensing - Open source software will eliminate software licensing costs, which can contribute significant costs to workloads. Where licensed software is required, avoid licenses bound to arbitrary attributes such as CPUs, look for licenses that are bound to output or outcomes. The cost of these licenses scales more closely to the benefit they provide. -
COST-05-05-
Select components of this workload to optimize cost in line with organization priorities - Factor in cost when selecting all components. This includes using application and managed services, such as Amazon RDS, Amazon DynamoDB, Amazon SNS, and Amazon SES to reduce overall organization cost. Use serverless and containers for compute, such as AWS Lambda, Amazon S3 for static websites, and Amazon ECS. -
COST-05-06-
Minimize license costs by using open source software, or software that does not have license fees: for example, Amazon Linux for compute workloads or migrate databases to Amazon Aurora. -
COST-05-07-
Perform cost analysis for different usage over time - Workloads can change over time. Some services or features are more cost effective at different usage levels. By performing the analysis on each component over time and at projected usage, you ensure the workload remains cost effective over its lifetime..
-
-
How do you meet targets when you select resource type, size, and number?
Ensure that you choose the appropriate resource size and number of resources for the task at hand. You minimize waste by selecting the most cost effective type, size, and number.
-
COST-06-01-
Perform cost modeling - Identify organization requirements and perform cost modeling of the workload and each of its components. Perform benchmark activities for the workload under different predicted loads and compare the costs. The modeling effort should reflect potential benefit: for example, time spent is proportional to component cost. -
COST-06-02-
Select resource type, size, and number based on data about the workload and resource characteristics: for example, compute, memory, throughput, or write intensive. This selection is typically made using a previous version of the workload (such as an on-premises version), using documentation, or using other sources of information about the workload. -
COST-06-03-
Select resource type, size, and number automatically based on metrics - Use metrics from the currently running workload to select the right size and type to optimize for cost. Appropriately provision throughput, sizing, and storage for services such as Amazon EC2, Amazon DynamoDB, Amazon EBS (PIOPS), Amazon RDS, Amazon EMR, and networking. This can be done with a feedback loop such as automatic scaling or by custom code in the workload.
-
-
How do you use pricing models to reduce cost?
-
COST-07-01-
Perform pricing model analysis - Analyze each component of the workload. Determine if the component and resources will be running for extended periods (for commitment discounts), or dynamic and short running (for spot or on-demand). Perform an analysis on the workload using the Recommendations feature in AWS Cost Explorer. -
COST-07-02-
Implement regions based on cost - Resource pricing can be different in each region. Factoring in region cost ensures you pay the lowest overall price for this workload -
COST-07-03-
Select third party agreements with cost efficient terms to ensure the cost of these services scales with the benefits they provide. Select agreements and pricing that scale when they provide additional benefits to the organization. -
COST-07-04-
Implement pricing models for all components of this workload - Permanently running resources should utilize reserved capacity such as Savings Plans or reserved Instances. Short term capacity is configured to use Spot Instances, or Spot Fleet. On demand is only used for short-term workloads that cannot be interrupted and do not run long enough for reserved capacity, between 25% to 75% of the period, depending on the resource type. -
COST-07-05-
Perform pricing model analysis at the master account level - Use Cost Explorer Savings Plans and Reserved Instance recommendations to perform regular analysis at the master account for commitment discounts.
-
-
How do you plan for data transfer charges?
-
COST-08-01-
Perform data transfer modeling - Gather organization requirements and perform data transfer modeling of the workload and each of its components. This identifies the lowest cost point for its current data transfer requirements. -
COST-08-02-
Select components to optimize data transfer cost - All components are selected, and architecture is designed to reduce data transfer costs. This includes using components such as WAN optimization and Multi-AZ configurations -
COST-08-03-
Implement services to reduce data transfer costs - For example, use a CDN such as Amazon CloudFront to deliver content to end users, caching layers using Amazon ElastiCache, or using AWS Direct Connect instead of VPN for connectivity to AWS.
-
-
How do you manage demand, and supply resources?
For a workload that has balanced spend and performance, ensure that everything you pay for is used and avoid significantly underutilizing instances. A skewed utilization metric in either direction has an adverse impact on the organization, in either operational costs (degraded perform
-
COST-09-01-
Perform an analysis on the workload demand over time. Ensure the analysis covers seasonal trends and accurately represents operating conditions over the full workload lifetime. Analysis effort should reflect potential benefit: for example, time spent is proportional to the workload cost. -
COST-09-02-
Implement a buffer or throttle to manage demand - Buffering and throttling modify the demand on each workload, smoothing out any peaks. Implement throttling when clients perform retries. Implement buffering to store the request and defer processing until a later time. Ensure throttles and buffers are designed so clients receive a response in the required time. -
COST-09-03-
Supply resources dynamically - Resources are provisioned in a planned manner. This can be demand-based, such as through automatic scaling, or time-based, where demand is predictable and resources are provided based on time. These methods result in the least amount of over or under provisioning. -
COST-09-04-
Decommission resources, entire services, and systems no longer required.
-
-
How do you evaluate new services?
As AWS releases new services and features, it’s a best practice to review existing architectural decisions to ensure they continue to be the most cost effective.
-
COST-10-01-
Develop a workload review process that defines the criteria and process for workload review. The review effort should reflect potential benefit: for example, core workloads or workloads with a value of over 10% of the bill are reviewed quarterly, while workloads below 10% are reviewed annually. -
COST-10-02-
Review and analyze this workload regularly - Existing workloads are regularly reviewed as per defined processes.
-
Questions lead to these goals/focus areas (and the services used to get there):
- Practice Cloud Financial Management -
- Expenditure and usage awareness – AWS Cost Explorer, AWS Budgets
- Cost-Effective resources – Cost Explorer, Amazon CloudWatch and Trusted Advisor, Amazon Aurora for RDS, AWS Direct Connect with Amazon CloudFront
- Matching supply and demand – Auto Scaling
-
Optimize Over Time – AWS News Blog and the What’s New section on the AWS website, AWS Trusted Advisor
- Develop a cost model
- Create budgets and alerts
AWS Design Principles for cost optimization:
-
Implement cloud financial management: To achieve financial success and accelerate business value realization in the cloud, you must invest in Cloud Financial Management. The organization must dedicate the necessary time and resources for building capability in this new domain of technology and usage management. Similar to Security or Operations capability, build capability through knowledge building, programs, resources, and processes to help you become a cost efficient organization.
- Functional Ownership
- Finance and Technology Partnership
- Cloud Budgets and Forecasts
- Cost-Aware Processes
- Cost-Aware Culture
- Quantify Business Value Delivered Through Cost Optimization
Others:
-
Adopt a consumption model</a>: Pay only for the computing resources you consume, and increase or decrease usage depending on business requirements. For example, development and test environments are typically only used for eight hours a day during the work week. You can stop these resources when they’re not in use for a potential cost savings of 75% (40 hours versus 168 hours).
-
Measure overall efficiency: Measure the business output of the workload and the costs associated with delivery. Use this data to understand the gains you make from increasing output, increasing functionality, and reducing cost.
-
Stop spending money on undifferentiated “heavy lifting” of data center operations like racking, stacking, and powering servers. AWS also removes the operational burden of managing operating systems and applications with managed services. This allows you to focus on customers and business projects rather than on IT infrastructure.
-
Analyze and attribute expenditure: The cloud makes it easier to accurately identify the cost and usage of workloads, which then allows transparent attribution of IT costs to revenue streams and individual workload owners. This helps measure return on investment (ROI) and gives workload owners an opportunity to optimize their resources and reduce costs.
-
Use managed services to reduce cost of ownership
Tasks:
-
Expenditure and usage awareness
- Governance
- Monitor Cost and Usage
- Decommission Resources
-
- Evaluate Cost When Selecting Services
- Select the Correct Resource Type, Size, and Number
- Select the Best Pricing Model
- Plan for Data Transfer
-
Manage Demand and Supply Resources
- Manage Demand – Throttling: API Gateway
-
Manage Demand – Buffer based: Amazon SQS (Kafka), Kinesis stream
- Demand-based supply: ELB
- Time-based supply: APIs and SDKs
- Dynamic Supply: AWS Auto Scaling
7 hr video course “AWS FinOps: Cost Management & Optimization” by Oliver Gehrmann identified these strategies for cost optimization:
- Right-sizing instances
- Increase elasticity
- Pick the right pricing model
- Match usage to Storage costs
AWS Cost, Usage, Billing
Docs: AWS Cost & Usage Report (AWS CUR) contains the most comprehensive set of cost and usage data available.
NOTE: The AWS Pricing Calculator at https://calculator.aws/# is used to estimate costs for specific architectures. Different server types have different costs. The same services in different regions have different prices. Transfer of data between different regions incur charges.
AWS billing reports are published to an Amazon Simple Storage Service (Amazon S3) bucket.
-
REMEMBER: Click your name at the top bar for the menu to select “My Billing Dashboard”:
“Cost Management” consists of:
- Cost Explorer
- Budgets
- Budgets Reports
- Saving Plans
- Cost & Usage Reports
- Cost Categories
- Cost allocation tags
“Billing” consists of:
- Billing
- Orders and invoices
- Credits
- Purchase orders
In “AWS Cost Management”:
-
Click “Cost Explorer” to launch Cost Explorer for “AWS Cost Management”
-
For Daily views, in preferences, check “Hourly and Resource Data” which costs more money.
https://www.youtube.com/watch?v=NfONXHkTefA How do I use the AWS Cost and Usage Report?
https://www.youtube.com/watch?v=gl0zpKLbRe0 AWS re:Invent 2020: Billing management and cost control by Keith Jarrett (Head of AWS Cost Management, Product Marketing and Business Intelligence)
AWS Cost Optimization: Tools and Methods to Reduce Your Spend With Us
AWS Cost Optimization hands-on labs:
Sustainability
AWS Sustainability hands-on labs:
- 300: Turning Cost & Usage Reports into Efficiency Reports in an “improvement” process:
- Identify targets for improvement
- Evaluate specific improvements
- Prioritize and plan improvements
- Test and validate improvements
- Deploy changes to production
- Measure results and replicate successes
Well-Architected Framework Review
Enterprise subscribers ($15,000/month) can have AWS Solution Architects (from Amazon Professional Services) conduct a “Well-Architected Review” of advice covered in the Well-Architected Framework described in this free video training and books (in pdf and Kindle).
Apptio CloudAbility
References
In the deprecated AWS classroom training site, curriculum?id=12049 provides a separate document/video summarizing each of the topics covered in the Well-Architected Framework:
- Cost Optimization
- Performance
- Security
- Fault Tolerance
- Service Limits
https://explore.skillbuilder.aws/learn https://explore.skillbuilder.aws/learn/learning_plan/view/91/security-learning-plan
https://tutorialsdojo.com/aws-well-architected-framework-five-pillars/
STAR: https://aws.amazon.com/blogs/aws-cloud-financial-management/cost-reporting-based-on-aws-organizations-account-id-tags/
Mike’s blog lists AWS whitepapers recommended per specific AWS exam.
https://www.trendmicro.com/en_us/what-is/cloud-security/cloud-architecture.html highlights considerations for Components, sub-components, etc.
https://www.trendmicro.com/en_us/what-is/cloud-security.html
https://learn.hashicorp.com/tutorials/well-architected-framework/implement-cloud-operating-model?in=well-architected-framework/com
More on cloud
This is one of a series on cloud computing:
- Dockerize apps
- Kubernetes container engine
- Hashicorp Vault and Consul for keeping secrets
- Hashicorp Terraform
- Ansible server configuration automation
- Serverless software app development
- Terraform (declarative IaC)
- Build load-balanced servers in AWS EC2
- AWS On-boarding (CLI install)
- AWS MacOS instances in the cloud)
- AWS Certifications
- AWS IAM admin.
- AWS Data Tools
- AWS Security
- AWS VPC Networking
- AWS X-Ray tracing
- AWS server deployment options
- AWS Lambda
- AWS Cloud Formation/cloud-formation/)
- AWS Lightsail
- AWS Deeplens AI
- AWS Load Balanced Servers using CloudFormation
-
Microtrader (sample microservices CI/CD to production Docker within AWS)
-
AWS Data Processing: Databases, Big Data, Data Warehouse, Data Lakehouse
- Google Cloud Platform
-
Bash Windows using Microsoft’s WSL (Windows Subsystem for Linux)
- Azure cloud introduction
- Azure Cloud Onramp (Subscriptions, Portal GUI, CLI)
- Azure Cloud Powershell
- PowerShell GitHub API programming
- PowerShell DSC (Desired State Configuration)
- PowerShell Modules
- Microsoft AI in Azure cloud
- Azure cloud DevOps
- Azure Networking
- Azure Storage
- Azure Compute
- Dynatrace cloud monitoring
- Digital Ocean
- Cloud Foundry